- A+
所属分类:Web前端
UTF-8编码的汉字:少数是汉字每个占用3个字节,多数占用4个字节
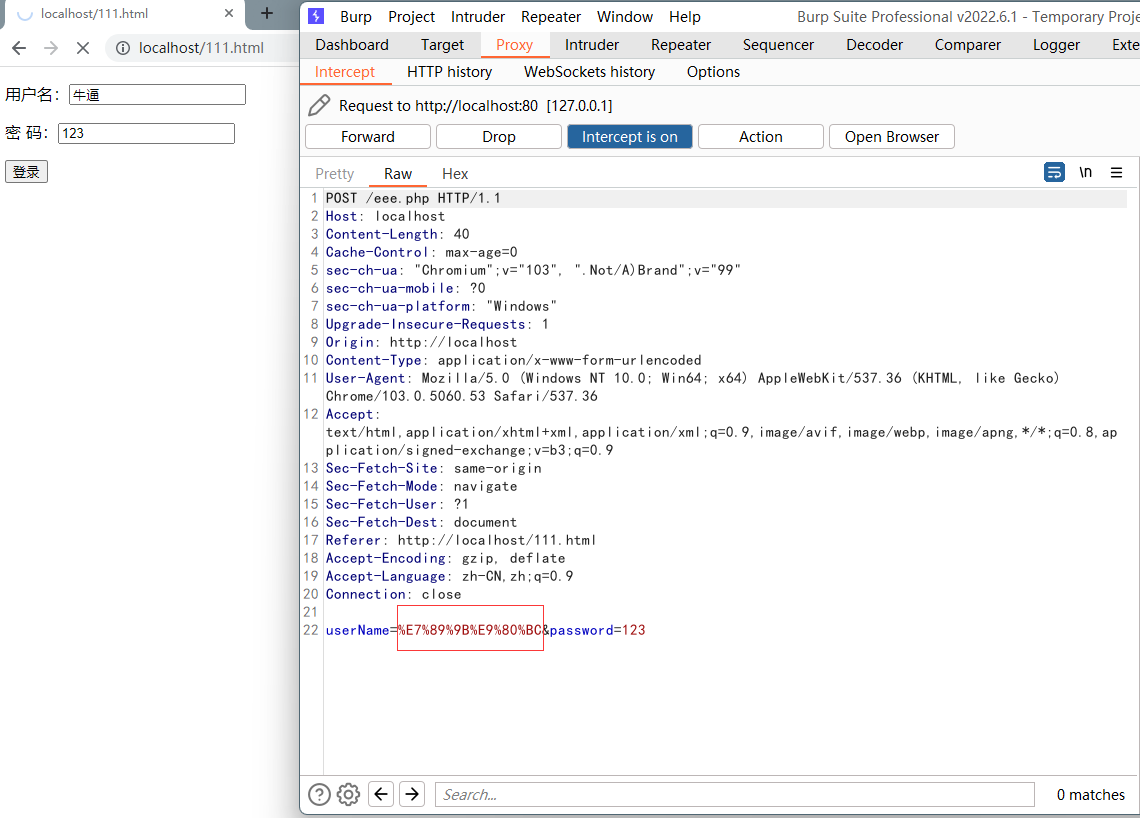
# GET请求编码
Chrome会先把URL中非ASCII字符按照某种编码格式(谷歌浏览器是UTF-8)编码成byte数组后,然后转成16进制数组,然后在每个16进制数字前加上&分割
eg:
地址栏:http://localhost/eee.php?b=1zpeasy牛逼 回车
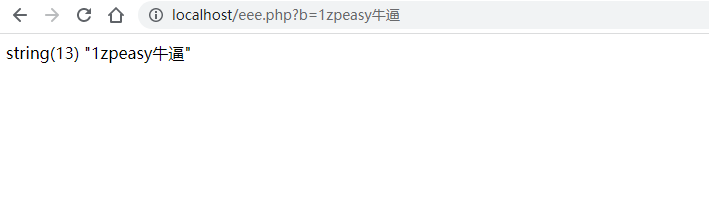
我们发现浏览器发送的请求是: http://localhost/eee.php?b=1zpeasy%E7%89%9B%E9%80%BC

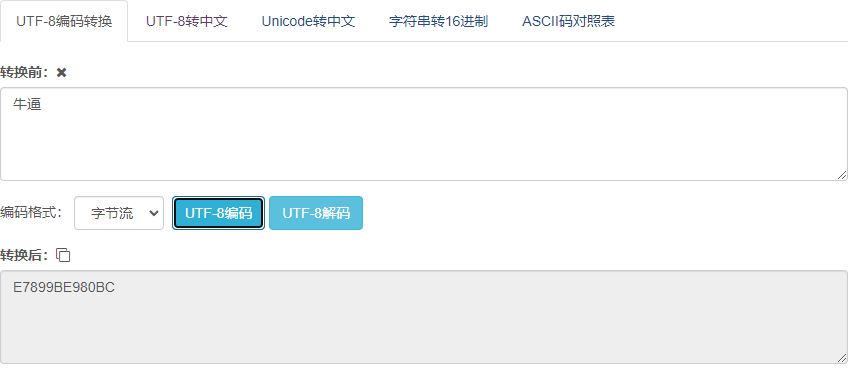
也就是浏览器在发送请求前给编码处理了,首先是把非ASCII字符牛逼->二进制字节楼->16进制字节流 E7899BE980BC->%E7%89%9B%E9%80%BC
编码转换网址:UTF-8编码转换器-ME2在线工具 (metools.info)
# GET接收解码
互联网上的所有数据都是字节传输的,当服务器接受过来接受过来之后,首先会对url这一块解码,解码出http://localhost/eee.php(这部分解码是根据服务器配置文件设置的,列入tomcat <Connector URIEncoding="UTF-8">)
关于参数的解码这里不再赘述,详情可参考http请求(GET/POST)时,url/参数编码的过程分析_个人文章 - SegmentFault 思否
# POST请求编码
post提交参数时也是要编码的,和GET方式类似