- A+
所属分类:linux技术
BIO
BIO(Blocking IO) 又称同步阻塞IO,一个客户端由一个线程来进行处理
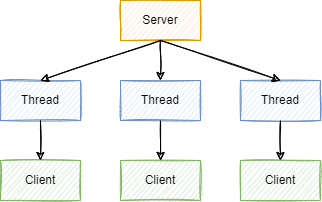
当客户端建立连接后,服务端会开辟线程用来与客户端进行连接。以下两种情况会造成IO阻塞:
- 服务端会一直阻塞,直到和客户端进行连接
- 客户端也会一直阻塞,直到和服务端进行连接
基于BIO,当连接时,每有一个客户端,服务就开启线程处理,这样对资源的占用时非常大的;如果使用线城市来做优化,当大量连接时,服务端也会面临无空闲线程处理的问题。那么怎么设计才能让单个线程能够处理更多请求,而不是一个。所以NIO就被提出。
NIO
NIO(Non Blocking IO)又称同步非阻塞IO。服务器实现模式为把多个连接(请求)放入集合中,只用一个线程可以处理多个请求(连接),也就是多路复用。
NIO有3大核心组件:
- Buffer:缓冲区,buffer 底层就是数组
- Channel:通道,channel 类似于流,每个 channel 对应一个 buffer缓冲区
- Selector:多路复用器,channel 会注册到 selector 上,由 selector 根据 channel 读写事件的发生将其交由某个空闲的线程处理
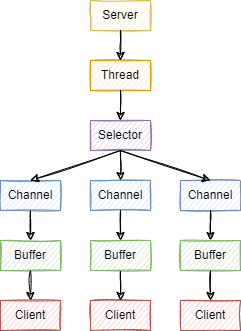
这样就大大提升了连接的数量,用于接收请求。
NIO目前有三个函数(模型)
- select
- poll
- epoll
Select函数
Select 是Linux提供的一个函数,可以将一批fd一次性传递给内核,然后由内核去遍历,来确定哪个fd符合,并提供给用户空间
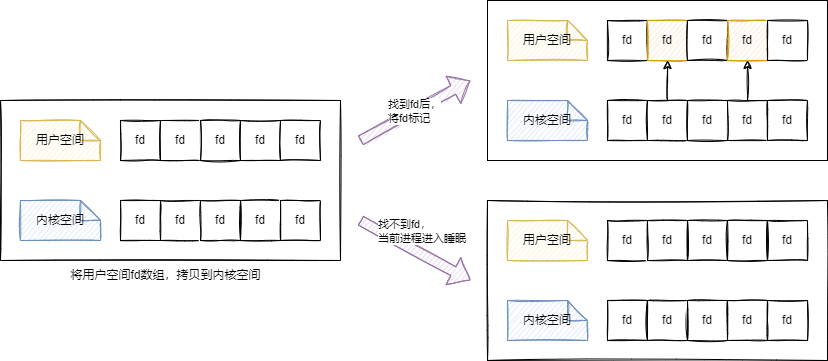
Select 函数处理过程
- 将用户空间的
fd数组拷贝到内核空间 - 内核空间会遍历
fd数组,查看是否有数据到达- 遍历所有
fd,将当前进程挂到每个fd的等待队列中 - 当设备收到一条消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,随后
当前进程就会被唤醒
- 遍历所有
- 遍历完成后,如果有数据到达,返回有数据到达的
fd的数量,并对用户空间的fd做标记 - 如果无数据到达,则
当前进程进入睡眠,当有某个fd有I/O事件或当前进程睡眠超时后,当前进程重新唤醒再次遍历所有fd文件 - 用户空间再此循环遍历,没有标记的
fd不处理,只有标记的fd才会去处理
Select存在的问题
fd数量有限制:单个进程所打开的fd是有限制的,通过FD_SETSIZE设置,默认1024fd拷贝耗时:每次调用select,需要将fd数组从用户空间拷贝到内核空间- 内核空间遍历耗时:内核空间通过遍历的方式,查看
fd是否有数据到达,这是一个同步的过程 - 找到
fd后,返回的是数量,而不是fd本身:select返回的是fd的数量,具体是哪个还需要用户自己遍历
Poll函数
Poll 也是Linux提供的内核函数,poll 和 select 基本是一致,唯一的区别在于它们支持的fd的数量不一致
- select : 只能监听 1024 个
fd - poll :无限制,操作系统支持多少,poll 就可以支持多少
Epoll函数
poll解决了select函数的fd数量问题,而epoll解决了select、poll函数其余问题:
fd数量有限制:poll已经解决此问题fd拷贝耗时:内核空间种保存一份fd数组,无需用户每次都重新传入,只需要告诉内核修改的部分即可- 内核空间遍历耗时:内核空间不再通过遍历的方式找
fd,而是通过异步 IO 事件唤醒 - 找到
fd后,返回的是数量,而不是fd本身:内核空间会通过异步 IO 事件,将fd返回给用户,用户无需在遍历整个fd数组
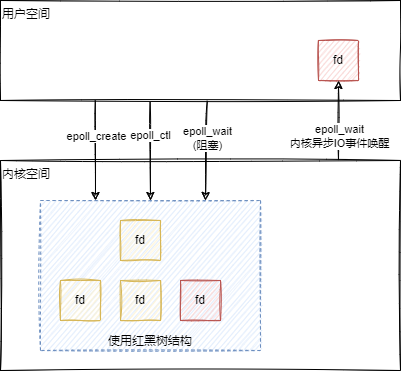
因此,epoll提供3 个函数,来处理上述改进的方案:
epoll_create:创建 epoll 句柄epoll_ctl:向内核空间添加,修改,删除需要监控的fdepoll_wait、epoll_pwait:类似select函数




