- A+
接上篇 通过一个示例形象地理解C# async await 非并行异步、并行异步、并行异步的并发量控制
前些天写了两篇关于C# async await异步的博客,
第一篇博客看的人多,点赞评论也多,我想应该都看懂了,比较简单。
第二篇博客看的人少,点赞的也少,没有评论。
我很纳闷,第二篇博客才是重点,如此吊炸天的代码,居然没人评论。
这个代码,就是.NET圈的顶级大佬也没有写过,为什么这么说,这就要说到C# async await的语法糖:
没有语法糖,代码一样写,java8没有语法糖,一样写出很厉害的代码。但有了C# async await语法糖,普通的水平一般的业务程序员,哪怕是菜B,也能写出高吞吐高性能的代码,这就是意义!
所以我说顶级大佬没写过,因为他们水平高,脑力好,手段多,自然不需要这么写。但普通程序员要那样写代码,麻烦不说,BUG频出。
标题我用了"探索"这个词,有没有更好的实践,让小白们都会写的并行异步的实践?
ElasticSearch的性能
代码的实用价值,是查询es。
最近发现es的性能非常好!先给大家看个控制台输出的截图。服务我是部署在服务器上的,真实环境,不是自己电脑。
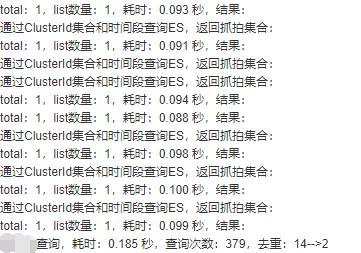
379次es查询,仅需0.185秒,当然耗时会有波动,零点几秒都是正常的,超过1秒也有可能。
es最怕的是什么,是慢查询,是条件复杂的查询,是范围查询。
我的策略是多次精确查询,这样可以利用es极高的吞吐能力。
并行异步
既然查询次数多,单线程或者说同步肯定是不行的,必须并行。
并行代码,python能写吗?java能写吗?肯定能啊!
但我前同事写的python多次查询es写的就是同步代码,为什么不并行呢?并行肯定可以写,但是能不写就不写,为什么?因为写起来复杂,不好写。你以为自己技术好,脑力好没问题,但别人呢?
重点是什么?不仅要写并行代码,还要写的简单,不破坏代码原有逻辑结构。
异步方法
大家都会写的,用async await就行了,很简单,放个我写的,代码主要是在双循环中多次异步请求(大致看一下先跳过):
/// <summary> /// xxx查询 /// </summary> public async Task<List<AccompanyInfo>> Query2(string strStartTime, string strEndTime, int kpCountThreshold, int countThreshold, int distanceThreshold, int timeThreshold, List<PeopleCluster> peopleClusterList) { List<AccompanyInfo> resultList = new List<AccompanyInfo>(); Stopwatch sw = Stopwatch.StartNew(); //创建字典 Dictionary<string, PeopleCluster> clusterIdPeopleDict = new Dictionary<string, PeopleCluster>(); foreach (PeopleCluster peopleCluster in peopleClusterList) { foreach (string clusterId in peopleCluster.ClusterIds) { if (!clusterIdPeopleDict.ContainsKey(clusterId)) { clusterIdPeopleDict.Add(clusterId, peopleCluster); } } } int queryCount = 0; Dictionary<string, AccompanyInfo> dict = new Dictionary<string, AccompanyInfo>(); foreach (PeopleCluster people1 in peopleClusterList) { List<PeopleFeatureInfo> peopleFeatureList = await ServiceFactory.Get<PeopleFeatureQueryService>().Query(strStartTime, strEndTime, people1); queryCount++; foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList) { DateTime capturedTime = DateTime.ParseExact(peopleFeatureInfo1.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture); string strStartTime2 = capturedTime.AddSeconds(-timeThreshold).ToString("yyyyMMddHHmmss"); string strEndTime2 = capturedTime.AddSeconds(timeThreshold).ToString("yyyyMMddHHmmss"); List<PeopleFeatureInfo> peopleFeatureList2 = await ServiceFactory.Get<PeopleFeatureQueryService>().QueryExcludeSelf(strStartTime2, strEndTime2, people1); queryCount++; if (peopleFeatureList2.Count > 0) { foreach (PeopleFeatureInfo peopleFeatureInfo2 in peopleFeatureList2) { string key = null; PeopleCluster people2 = null; string people2ClusterId = null; if (clusterIdPeopleDict.ContainsKey(peopleFeatureInfo2.cluster_id.ToString())) { people2 = clusterIdPeopleDict[peopleFeatureInfo2.cluster_id.ToString()]; key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2.ClusterIds)}"; } else { people2ClusterId = peopleFeatureInfo2.cluster_id.ToString(); key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2ClusterId)}"; } double distance = LngLatUtil.CalcDistance(peopleFeatureInfo1.Longitude, peopleFeatureInfo1.Latitude, peopleFeatureInfo2.Longitude, peopleFeatureInfo2.Latitude); if (distance > distanceThreshold) continue; AccompanyInfo accompanyInfo; if (dict.ContainsKey(key)) { accompanyInfo = dict[key]; } else { accompanyInfo = new AccompanyInfo(); dict.Add(key, accompanyInfo); } accompanyInfo.People1 = people1; if (people2 != null) { accompanyInfo.People2 = people2; } else { accompanyInfo.ClusterId2 = people2ClusterId; } AccompanyItem accompanyItem = new AccompanyItem(); accompanyItem.Info1 = peopleFeatureInfo1; accompanyItem.Info2 = peopleFeatureInfo2; accompanyInfo.List.Add(accompanyItem); accompanyInfo.Count++; resultList.Add(accompanyInfo); } } } } resultList = resultList.FindAll(a => (a.People2 != null && a.Count >= kpCountThreshold) || a.Count >= countThreshold); //去重 int beforeDistinctCount = resultList.Count; resultList = resultList.DistinctBy(a => { string str1 = string.Join(",", a.People1.ClusterIds); string str2 = a.People2 != null ? string.Join(",", a.People2.ClusterIds) : string.Empty; string str3 = a.ClusterId2 ?? string.Empty; StringBuilder sb = new StringBuilder(); foreach (AccompanyItem item in a.List) { var info2 = item.Info2; sb.Append($"{info2.camera_id},{info2.captured_time},{info2.cluster_id}"); } return $"{str1}_{str2}_{str3}_{sb}"; }).ToList(); sw.Stop(); string msg = $"xxx查询,耗时:{sw.Elapsed.TotalSeconds:0.000} 秒,查询次数:{queryCount},去重:{beforeDistinctCount}-->{resultList.Count}"; Console.WriteLine(msg); LogUtil.Info(msg); return resultList; } 异步方法的并行化
上述代码是没有问题的,但也有问题。就是在双循环中多次请求,虽然用了async await,但不是并行,耗时会很长,如何优化?请看如下代码:
/// <summary> /// xxx查询 /// </summary> public async Task<List<AccompanyInfo>> Query(string strStartTime, string strEndTime, int kpCountThreshold, int countThreshold, int distanceThreshold, int timeThreshold, List<PeopleCluster> peopleClusterList) { List<AccompanyInfo> resultList = new List<AccompanyInfo>(); Stopwatch sw = Stopwatch.StartNew(); //创建字典 Dictionary<string, PeopleCluster> clusterIdPeopleDict = new Dictionary<string, PeopleCluster>(); foreach (PeopleCluster peopleCluster in peopleClusterList) { foreach (string clusterId in peopleCluster.ClusterIds) { if (!clusterIdPeopleDict.ContainsKey(clusterId)) { clusterIdPeopleDict.Add(clusterId, peopleCluster); } } } //组织第一层循环task Dictionary<PeopleCluster, Task<List<PeopleFeatureInfo>>> tasks1 = new Dictionary<PeopleCluster, Task<List<PeopleFeatureInfo>>>(); foreach (PeopleCluster people1 in peopleClusterList) { var task1 = ServiceFactory.Get<PeopleFeatureQueryService>().Query(strStartTime, strEndTime, people1); tasks1.Add(people1, task1); } //计算第一层循环task并缓存结果,组织第二层循环task Dictionary<string, Task<List<PeopleFeatureInfo>>> tasks2 = new Dictionary<string, Task<List<PeopleFeatureInfo>>>(); Dictionary<PeopleCluster, List<PeopleFeatureInfo>> cache1 = new Dictionary<PeopleCluster, List<PeopleFeatureInfo>>(); foreach (PeopleCluster people1 in peopleClusterList) { List<PeopleFeatureInfo> peopleFeatureList = await tasks1[people1]; cache1.Add(people1, peopleFeatureList); foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList) { DateTime capturedTime = DateTime.ParseExact(peopleFeatureInfo1.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture); string strStartTime2 = capturedTime.AddSeconds(-timeThreshold).ToString("yyyyMMddHHmmss"); string strEndTime2 = capturedTime.AddSeconds(timeThreshold).ToString("yyyyMMddHHmmss"); var task2 = ServiceFactory.Get<PeopleFeatureQueryService>().QueryExcludeSelf(strStartTime2, strEndTime2, people1); string task2Key = $"{strStartTime2}_{strEndTime2}_{string.Join(",", people1.ClusterIds)}"; tasks2.TryAdd(task2Key, task2); } } //读取第一层循环task缓存结果,计算第二层循环task Dictionary<string, AccompanyInfo> dict = new Dictionary<string, AccompanyInfo>(); foreach (PeopleCluster people1 in peopleClusterList) { List<PeopleFeatureInfo> peopleFeatureList = cache1[people1]; foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList) { DateTime capturedTime = DateTime.ParseExact(peopleFeatureInfo1.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture); string strStartTime2 = capturedTime.AddSeconds(-timeThreshold).ToString("yyyyMMddHHmmss"); string strEndTime2 = capturedTime.AddSeconds(timeThreshold).ToString("yyyyMMddHHmmss"); string task2Key = $"{strStartTime2}_{strEndTime2}_{string.Join(",", people1.ClusterIds)}"; List<PeopleFeatureInfo> peopleFeatureList2 = await tasks2[task2Key]; if (peopleFeatureList2.Count > 0) { foreach (PeopleFeatureInfo peopleFeatureInfo2 in peopleFeatureList2) { string key = null; PeopleCluster people2 = null; string people2ClusterId = null; if (clusterIdPeopleDict.ContainsKey(peopleFeatureInfo2.cluster_id.ToString())) { people2 = clusterIdPeopleDict[peopleFeatureInfo2.cluster_id.ToString()]; key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2.ClusterIds)}"; } else { people2ClusterId = peopleFeatureInfo2.cluster_id.ToString(); key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2ClusterId)}"; } double distance = LngLatUtil.CalcDistance(peopleFeatureInfo1.Longitude, peopleFeatureInfo1.Latitude, peopleFeatureInfo2.Longitude, peopleFeatureInfo2.Latitude); if (distance > distanceThreshold) continue; AccompanyInfo accompanyInfo; if (dict.ContainsKey(key)) { accompanyInfo = dict[key]; } else { accompanyInfo = new AccompanyInfo(); dict.Add(key, accompanyInfo); } accompanyInfo.People1 = people1; if (people2 != null) { accompanyInfo.People2 = people2; } else { accompanyInfo.ClusterId2 = people2ClusterId; } AccompanyItem accompanyItem = new AccompanyItem(); accompanyItem.Info1 = peopleFeatureInfo1; accompanyItem.Info2 = peopleFeatureInfo2; accompanyInfo.List.Add(accompanyItem); accompanyInfo.Count++; resultList.Add(accompanyInfo); } } } } resultList = resultList.FindAll(a => (a.People2 != null && a.Count >= kpCountThreshold) || a.Count >= countThreshold); //去重 int beforeDistinctCount = resultList.Count; resultList = resultList.DistinctBy(a => { string str1 = string.Join(",", a.People1.ClusterIds); string str2 = a.People2 != null ? string.Join(",", a.People2.ClusterIds) : string.Empty; string str3 = a.ClusterId2 ?? string.Empty; StringBuilder sb = new StringBuilder(); foreach (AccompanyItem item in a.List) { var info2 = item.Info2; sb.Append($"{info2.camera_id},{info2.captured_time},{info2.cluster_id}"); } return $"{str1}_{str2}_{str3}_{sb}"; }).ToList(); //排序 foreach (AccompanyInfo item in resultList) { item.List.Sort((a, b) => -string.Compare(a.Info1.captured_time, b.Info1.captured_time)); } sw.Stop(); string msg = $"xxx查询,耗时:{sw.Elapsed.TotalSeconds:0.000} 秒,查询次数:{tasks1.Count + tasks2.Count},去重:{beforeDistinctCount}-->{resultList.Count}"; Console.WriteLine(msg); LogUtil.Info(msg); return resultList; } 上述代码说明
- 为了使异步并行化,双循环要写三遍。第一遍只需写第一层循环,省了第二层。第二遍没有数据处理的那层子循环。第三遍是最全的。
- 和普通的异步相比,第一、二遍双循环是多出来的,第三遍双循环代码结构和普通的异步代码结构是一样的。
- 写的时候,可以先写好普通的异步方法,然后再改造成并行化的异步方法。
你为什么说.NET圈的顶级大佬没有写过?
- 不吹个牛,博客没人看,没人点赞啊?!
- 牛B的是C#,由于C#语法糖,把牛B的代码写简单了,才是真的牛B。
- 我倒是希望有大佬写个更好的实践,把我这种写法淘汰掉,因为这是我能想到的最容易控制的写法了。
并行代码,很多人都会写,java、python也能写,但问题是,比较菜的普通业务程序员,如何无脑写这种并行代码?
最差的写法,例如java的CompletableFuture,结合业务代码,写法就很复杂了。真的没法无脑写。
其次的写法,例如:
List<PeopleFeatureInfo>[] listArray = await Task.WhenAll(tasks2.Values); 在双循环体中,怎么拿结果?肯定能写,但又要思考怎么写了不是?
而我的写法,在双循环体中是可以直接拿结果的:
List<PeopleFeatureInfo> list = await tasks2[task2Key]; - 只放C#代码没有说服力,我一个同事python写的很6,他写的挖掘代码很多都是并行,放一段代码:
def get_es_multiprocess(index_list, people_list, core_percent, rev_clusterid_idcard_dict): ''' 多进程读取es数据,转为整个数据帧,按时间排序 :return: 规模较大的数据帧 ''' col_list = ["cluster_id", "camera_id", "captured_time"] pool = Pool(processes=int(mp.cpu_count() * core_percent)) input_list = [(i, people_list, col_list) for i in index_list] res = pool.map(get_es, input_list) if not res: return None pool.close() pool.join() df_all = pd.DataFrame(columns=col_list+['longitude', 'latitude']) for df in res: df_all = pd.concat([df_all, df]) # 这里强制转换为字符串! df_all['cluster_id_'] = df_all['cluster_id'].apply(lambda x: rev_clusterid_idcard_dict[str(x)]) del df_all['cluster_id'] df_all.rename(columns={'cluster_id_': 'cluster_id'}, inplace=True) df_all.sort_values(by='captured_time', inplace=True) print('=' * 100) print('整个数据(聚类前):') print(df_all.info()) cluster_id_list = [(i, df) for i, df in df_all.groupby(['cluster_id'])] cluster_id_list_split = [j for j in func(cluster_id_list, 1000000)] # todo 缩小数据集,用于调试! data_all = df_all.iloc[:, :] return data_all, cluster_id_list_split 上述python代码解析
- 核心代码:
res = pool.map(get_es, input_list) pool.join() ...省略 其中get_es是查询es的方法,他写的应该不是异步方法,不过这个不是重点
2. res是查询结果,通过并行的方式一把查出来,放到res中,然后把结果再解出来
3. 注意,这只是单循环,想想双层循环怎么写
4. pool.join()是阻塞当前线程的,这个不好
5. 同事注释中写的是"多进程",是写错了吗?实际是多线程?还是就是多进程?
6. 当然,python是有async await异步写法的,应该不比C#差,只是同事没有用,可能是因为他用的python版本不够新
7. python代码,字符串太多,字符串是最不好维护的。C#中的字符串里面都是强类型。
把脑力活变成体力活
照葫芦画瓢,把脑力活变成体力活,我又写了一个方法(业务逻辑不重要,看并行异步的使用):
/// <summary> /// xxx查询 /// </summary> public async Task<List<SameVehicleInfo>> Query(string strStartTime, string strEndTime, int kpCountThreshold, int timeThreshold, List<PeopleCluster> peopleClusterList) { List<SameVehicleInfo> resultList = new List<SameVehicleInfo>(); Stopwatch sw = Stopwatch.StartNew(); //组织第一层循环task,查xxx Dictionary<PeopleCluster, Task<List<PeopleFeatureInfo>>> tasks1 = new Dictionary<PeopleCluster, Task<List<PeopleFeatureInfo>>>(); foreach (PeopleCluster people1 in peopleClusterList) { var task1 = ServiceFactory.Get<PeopleFeatureQueryService>().Query(strStartTime, strEndTime, people1); tasks1.Add(people1, task1); } //计算第一层循环task并缓存结果,组织第二层循环task,精确搜xxx Dictionary<string, Task<List<MotorVehicleInfo>>> tasks2 = new Dictionary<string, Task<List<MotorVehicleInfo>>>(); Dictionary<PeopleCluster, List<PeopleFeatureInfo>> cache1 = new Dictionary<PeopleCluster, List<PeopleFeatureInfo>>(); foreach (PeopleCluster people1 in peopleClusterList) { List<PeopleFeatureInfo> peopleFeatureList = await tasks1[people1]; cache1.Add(people1, peopleFeatureList); foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList) { string task2Key = $"{peopleFeatureInfo1.camera_id}_{peopleFeatureInfo1.captured_time}"; var task2 = ServiceFactory.Get<MotorVehicleQueryService>().QueryExact(peopleFeatureInfo1.camera_id, peopleFeatureInfo1.captured_time); tasks2.TryAdd(task2Key, task2); } } //读取第一层循环task缓存结果,计算第二层循环task Dictionary<PersonVehicleKey, PersonVehicleInfo> dictPersonVehicle = new Dictionary<PersonVehicleKey, PersonVehicleInfo>(); foreach (PeopleCluster people1 in peopleClusterList) { List<PeopleFeatureInfo> peopleFeatureList = cache1[people1]; foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList) { string task2Key = $"{peopleFeatureInfo1.camera_id}_{peopleFeatureInfo1.captured_time}"; List<MotorVehicleInfo> motorVehicleList = await tasks2[task2Key]; motorVehicleList = motorVehicleList.DistinctBy(a => a.plate_no).ToList(); foreach (MotorVehicleInfo motorVehicleInfo in motorVehicleList) { PersonVehicleKey key = new PersonVehicleKey(people1, motorVehicleInfo.plate_no); PersonVehicleInfo personVehicleInfo; if (dictPersonVehicle.ContainsKey(key)) { personVehicleInfo = dictPersonVehicle[key]; } else { personVehicleInfo = new PersonVehicleInfo() { People = people1, PlateNo = motorVehicleInfo.plate_no, List = new List<PeopleFeatureInfo>() }; dictPersonVehicle.Add(key, personVehicleInfo); } personVehicleInfo.List.Add(peopleFeatureInfo1); } } } //比对xxx List<PersonVehicleKey> keys = dictPersonVehicle.Keys.ToList(); Dictionary<string, SameVehicleInfo> dict = new Dictionary<string, SameVehicleInfo>(); for (int i = 0; i < keys.Count - 1; i++) { for (int j = i + 1; j < keys.Count; j++) { var key1 = keys[i]; var key2 = keys[j]; var personVehicle1 = dictPersonVehicle[key1]; var personVehicle2 = dictPersonVehicle[key2]; if (key1.PlateNo == key2.PlateNo) { foreach (PeopleFeatureInfo peopleFeature1 in personVehicle1.List) { double minTimeDiff = double.MaxValue; int minIndex = -1; for (int k = 0; k < personVehicle2.List.Count; k++) { PeopleFeatureInfo peopleFeature2 = personVehicle2.List[k]; DateTime capturedTime1 = DateTime.ParseExact(peopleFeature1.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture); DateTime capturedTime2 = DateTime.ParseExact(peopleFeature2.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture); var timeDiff = Math.Abs(capturedTime2.Subtract(capturedTime1).TotalSeconds); if (timeDiff < minTimeDiff) { minTimeDiff = timeDiff; minIndex = k; } } if (minIndex >= 0 && minTimeDiff <= timeThreshold * 60) { PeopleCluster people1 = key1.People; PeopleCluster people2 = key2.People; PeopleFeatureInfo peopleFeatureInfo2 = personVehicle2.List[minIndex]; string key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2.ClusterIds)}"; ; SameVehicleInfo accompanyInfo; if (dict.ContainsKey(key)) { accompanyInfo = dict[key]; } else { accompanyInfo = new SameVehicleInfo(); dict.Add(key, accompanyInfo); } accompanyInfo.People1 = people1; accompanyInfo.People2 = people2; SameVehicleItem accompanyItem = new SameVehicleItem(); accompanyItem.Info1 = peopleFeature1; accompanyItem.Info2 = peopleFeatureInfo2; accompanyInfo.List.Add(accompanyItem); accompanyInfo.Count++; resultList.Add(accompanyInfo); } } } } } resultList = resultList.FindAll(a => a.Count >= kpCountThreshold); //筛选,排除xxx resultList = resultList.FindAll(a => { if (string.Join(",", a.People1.ClusterIds) == string.Join(",", a.People2.ClusterIds)) { return false; } return true; }); //去重 int beforeDistinctCount = resultList.Count; resultList = resultList.DistinctBy(a => { string str1 = string.Join(",", a.People1.ClusterIds); string str2 = string.Join(",", a.People2.ClusterIds); StringBuilder sb = new StringBuilder(); foreach (SameVehicleItem item in a.List) { var info2 = item.Info2; sb.Append($"{info2.camera_id},{info2.captured_time},{info2.cluster_id}"); } return $"{str1}_{str2}_{sb}"; }).ToList(); //排序 foreach (SameVehicleInfo item in resultList) { item.List.Sort((a, b) => -string.Compare(a.Info1.captured_time, b.Info1.captured_time)); } sw.Stop(); string msg = $"xxx查询,耗时:{sw.Elapsed.TotalSeconds:0.000} 秒,查询次数:{tasks1.Count + tasks2.Count},去重:{beforeDistinctCount}-->{resultList.Count}"; Console.WriteLine(msg); LogUtil.Info(msg); return resultList; } 未完,待补充
XXX
- 我们开发的低代码平台很牛B,C#:我就是低代码!
- 我们开发的平台很牛B,支持写脚本、自定义脚本,C#:我就是脚本!
- 我们用spark、flink分布式,性能牛B,C#:并行异步性能吊炸天,内存给大些,单机就可以。C#:我的并行异步的性能,能把es干挂,只要不是计算密集型,只要内存够,不用spark、flink,单机简单啊,只是es是集群就行了。




