- A+
本系列将和大家分享Redis分布式缓存,本章主要简单介绍下Redis中的布隆过滤器(Bloom Filter),以及如何破解ServiceStack和如何解决缓存雪崩、缓存穿透、缓存击穿、缓存预热问题。话不多说,下面我们直接进入主题。
一、ServiceStack破解
首先我们先来看一下Demo的目录结构,如下所示:
第一种方式:我们通过 NuGet 安装 ServiceStack 相关的程序包。
然后在 MyRedis 控制台项目中运行如下测试代码:
/// <summary> /// 模拟抛出LicenseException异常 /// </summary> public static void ThrowLicenseException() { //模拟1小时内超过6000次请求 Parallel.For(0, 10000, (i) => { using (RedisStringService service = new RedisStringService()) { service.Set("TianYa" + i, i); service.IncrementValue("TianYa" + i); Console.WriteLine(i); } }); }
using System; using MyRedis.Scene; namespace MyRedis { /// <summary> /// Redis:Remote Dictionary Server 远程字典服务器 /// 基于内存管理(数据存在内存),实现了5种数据结构(分别应对各种具体需求),单线程模型的应用程序(单进程单线程),对外提供插入--查询--固化--集群功能。 /// 正是因为基于内存管理所以速度快,可以用来提升性能。但是不能当数据库,不能作为数据的最终依据。 /// 单线程多进程的模式来提供集群服务。 /// 单线程最大的好处就是原子性操作,就是要么都成功,要么都失败,不会出现中间状态。Redis每个命令都是原子性(因为单线程),不用考虑并发,不会出现中间状态。(线程安全) /// Redis就是为开发而生,会为各种开发需求提供对应的解决方案。 /// Redis只是为了提升性能,不做数据标准。任何的数据固化都是由数据库完成的,Redis不能代替数据库。 /// Redis实现的5种数据结构:String、Hashtable、Set、ZSet和List。 /// </summary> internal class Program { static void Main(string[] args) { //ServiceStackTest.ShowString(); //OverSellFailedTest.Show(); //OverSellTest.Show(); //ServiceStackTest.ShowHash(); //ServiceStackTest.ShowSet(); //FriendManager.Show(); //ServiceStackTest.ShowZSet(); //RankManager.Show(); //ServiceStackTest.ShowList(); //ServiceStackTest.ShowPublishAndSubscribe(); ServiceStackTest.ThrowLicenseException(); Console.ReadKey(); } } }
运行结果如下所示:
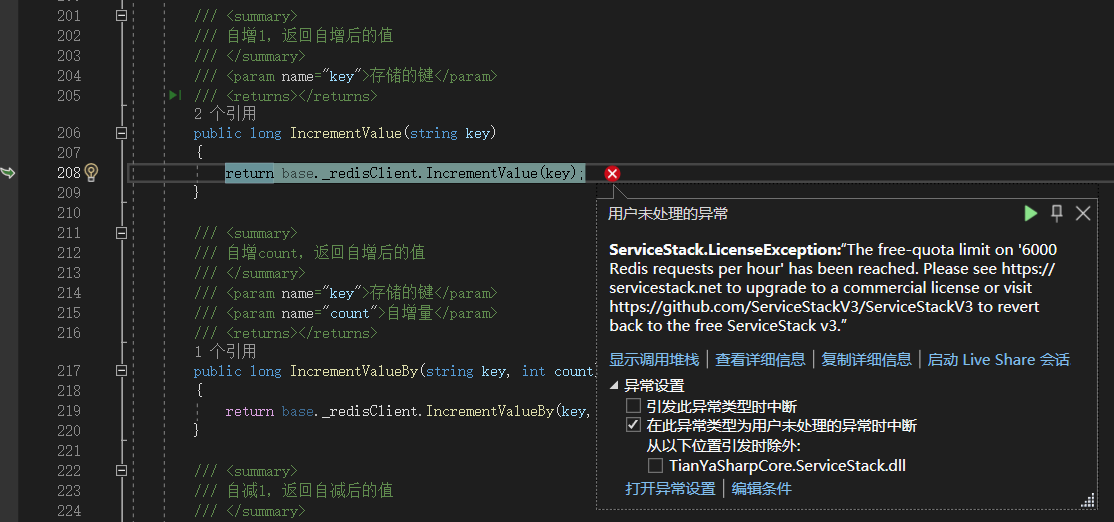
可以发现此时会抛出异常,提示每小时只能进行6000次Redis请求。
第二种方式:使用破解好的 ServiceStack 相关的动态链接库。
首先我们先从 GitHub 上下载最新版本的 ServiceStack 源码,如下所示:
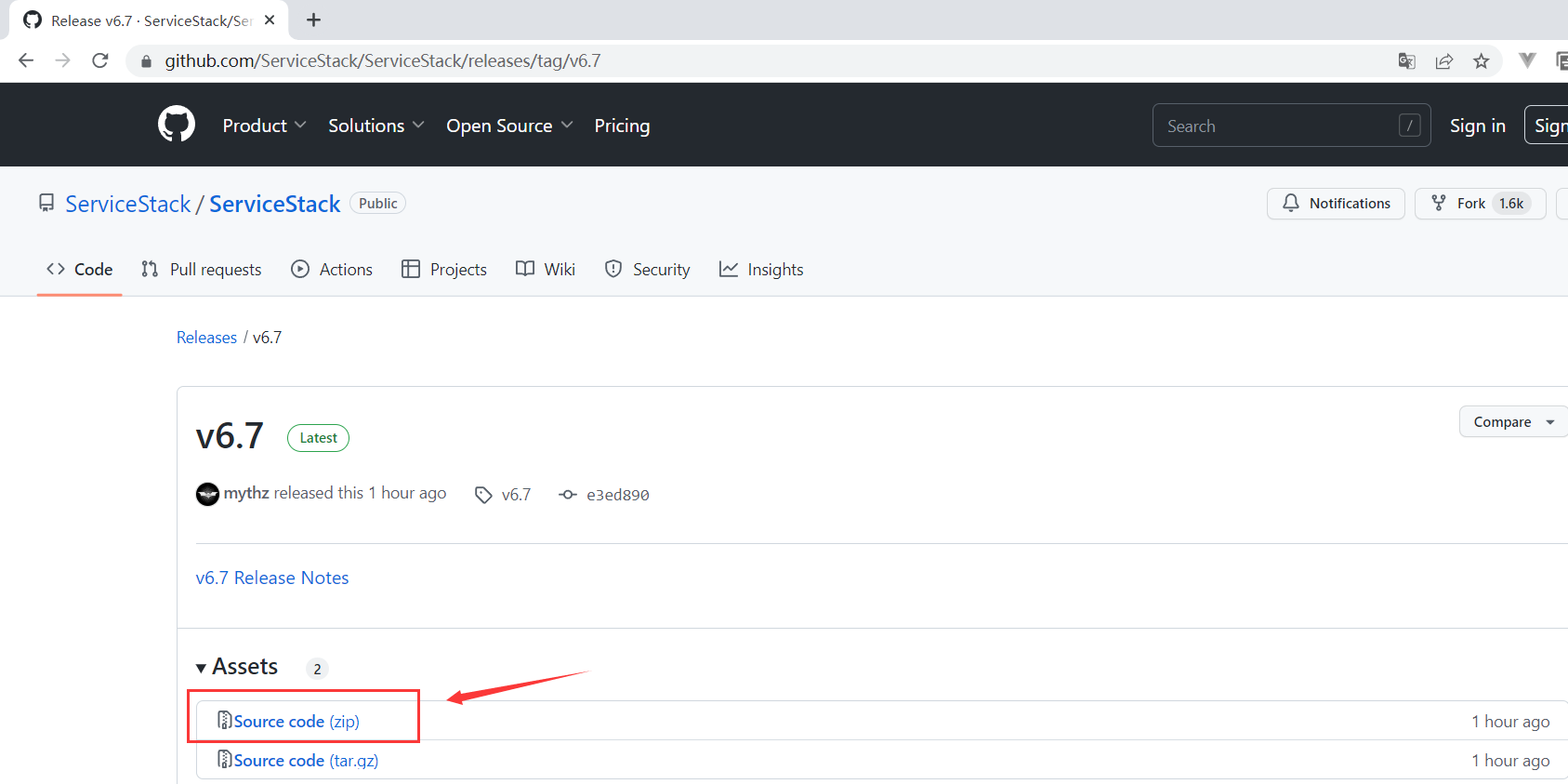
下载完成后打开对应的解决方案,如下所示:
打开后找到 LicenseUtils.cs 类:
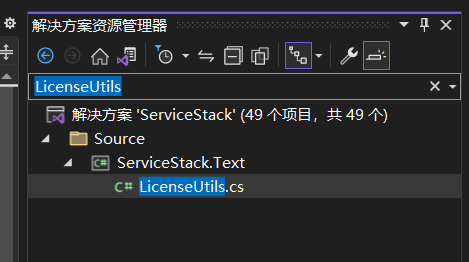
接着找到 LicenseUtils.cs 类中的 ApprovedUsage(...) 方法,修改代码如下所示:
保存成功后重新生成下 ServiceStack.Text 和 ServiceStack.Redis 这两个类库:
重新生成完成后打开 ServiceStack.Redis 类库的 bin/Debug 目录,如下所示:
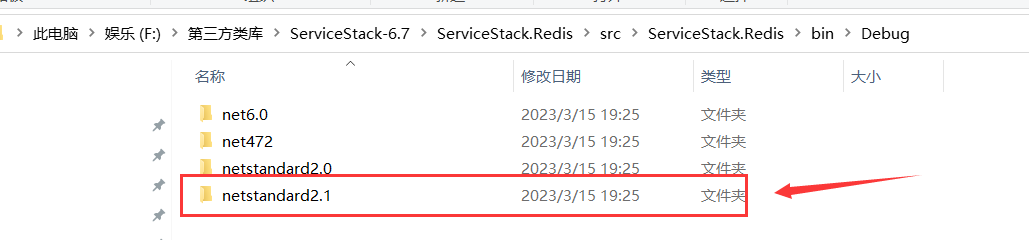
由于Demo中 TianYaSharpCore.ServiceStack 类库的目标框架为 .NET Standard 2.1 ,故此处要使用 netstandard2.1 文件夹中的动态链接库:
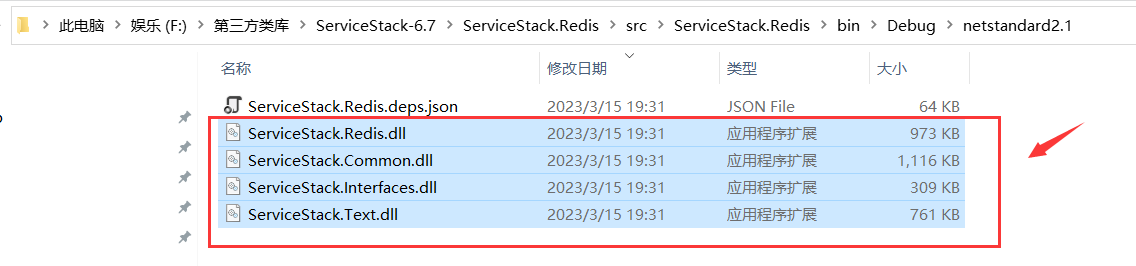
将破解好的这四个动态链接库,复制到Demo的解决方案根目录下新建的 Lib 文件夹中,如下所示:
然后将Demo中引用 NuGet 的 ServiceStack 相关程序包卸载掉,改成引用本地 Lib 文件夹中的那四个破解好的动态链接库,如下所示:
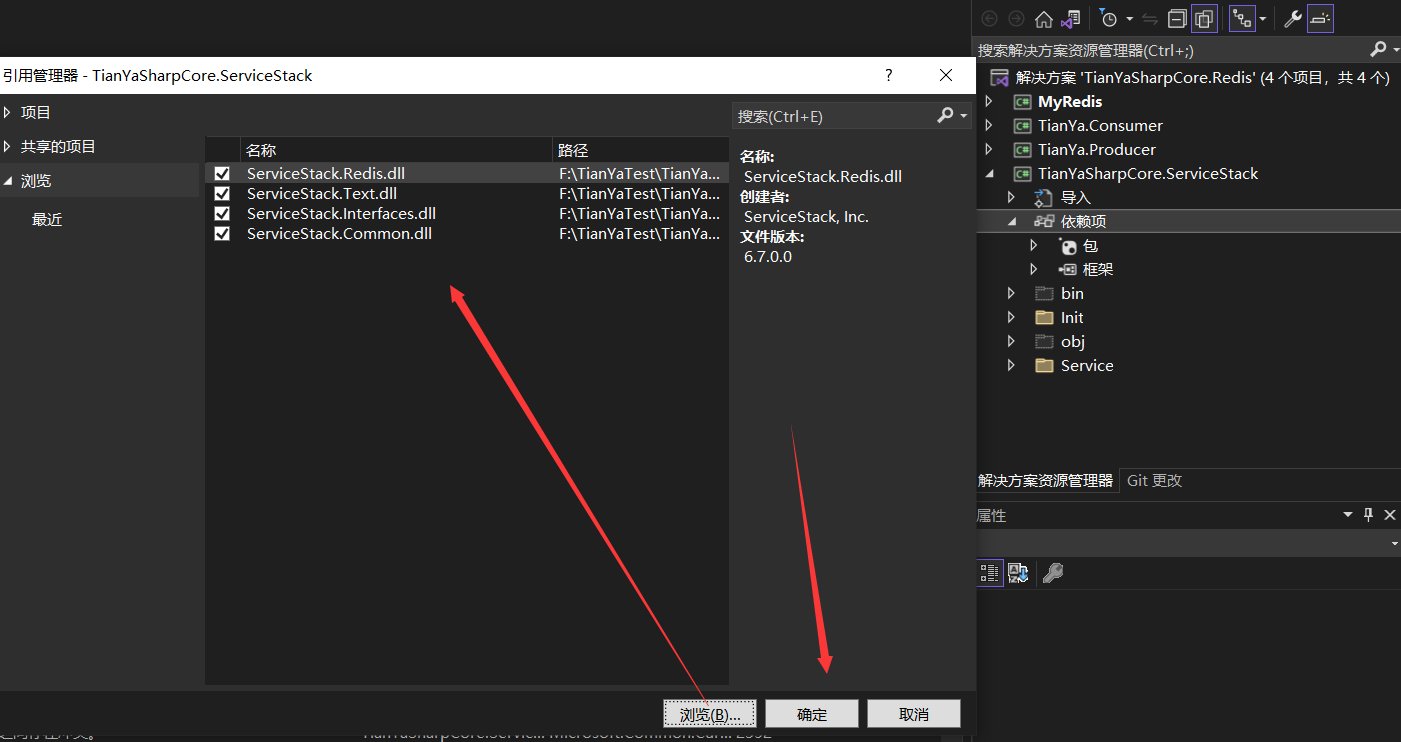
此外,还需要从 NuGet 上添加 Microsoft.Bcl.Asynclnterfaces 程序包,如下所示:
最后我们重新生成下Demo的解决方案,再次运行 MyRedis 控制台项目,运行结果如下所示:
可以发现,此时不会再抛出异常了,说明我们破解成功了。
二、布隆过滤器
1、场景介绍
1)大数据去重,比如新闻推荐场景,新闻有很多,要不要在app/网站给用户显示,看过的显然不需要显示,大量的新闻数据面前如何快速去重?
2)注册用户,用户名是否可用?
3)爬虫程序中大数据量url去重。
4)垃圾邮件/垃圾短信去重。
5)用来防止缓存穿透。
2、引子
正式开始介绍布隆过滤器之前,我们先用常规的手段去解决数据去重的问题。
例子1:我们做爬虫程序,会抓取很多的url地址,我们怎么知道某个url地址是否爬取过呢?
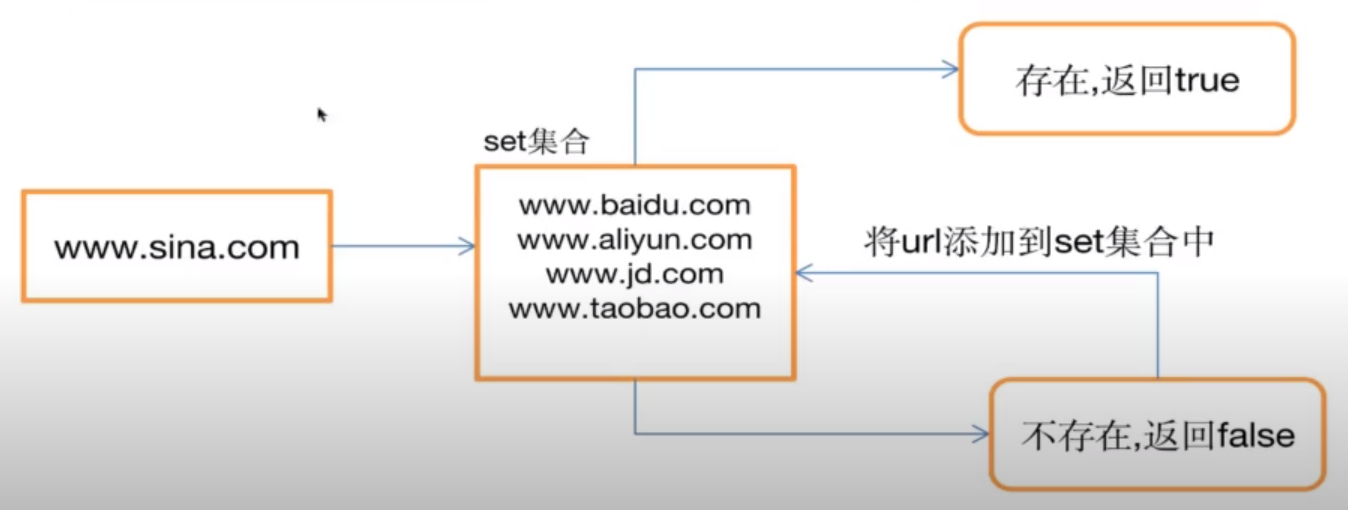
使用set集合去重,如果数据量大了,有很多的url需要存储,那么set集合需要把所有的用过的url地址存下来。假设有1亿个url地址,每个url地址有64个字符,那么存储这些数据就需要64*8*1亿个比特位(这还不考虑本身数据结构需要占用的内存),这样算下来我们就大概需要6个G的内存,内存占用几乎是不可忍受的,更别说大型互联网公司,数据量更大。也就是说用set集合来做大数据判重几乎不可取。
例子2:使用数据库判断某个用户名是否注册过?

我们采用MySQL这种带持久化的数据库,虽然解决了内存问题,但是我们需要跟MySQL服务器建立连接,MySQL服务器需要从硬盘读取判断,这个时长也是不可忍受的...
总结来说:传统方式在做大数据去重,要么有时长的问题,要么有内存占用的问题。那么我们有没有一种内存占用不那么大,时长可以忍受的方式呢?布隆过滤器闪亮登场了!
3、布隆过滤器的介绍
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误判率和删除困难。
4、过滤器原理
从上面的场景中,可以看出我们的需求很简单只是要判断一下,某条数据是否存在,而不关心这条数据的具体内容,也就是说返回一个bool值即可。而我们计算机中二进制天然的满足了这个特性,0代表false,1代表true。我们可以在内存中申请一段bit数组。(又称bitmap翻译为位图)

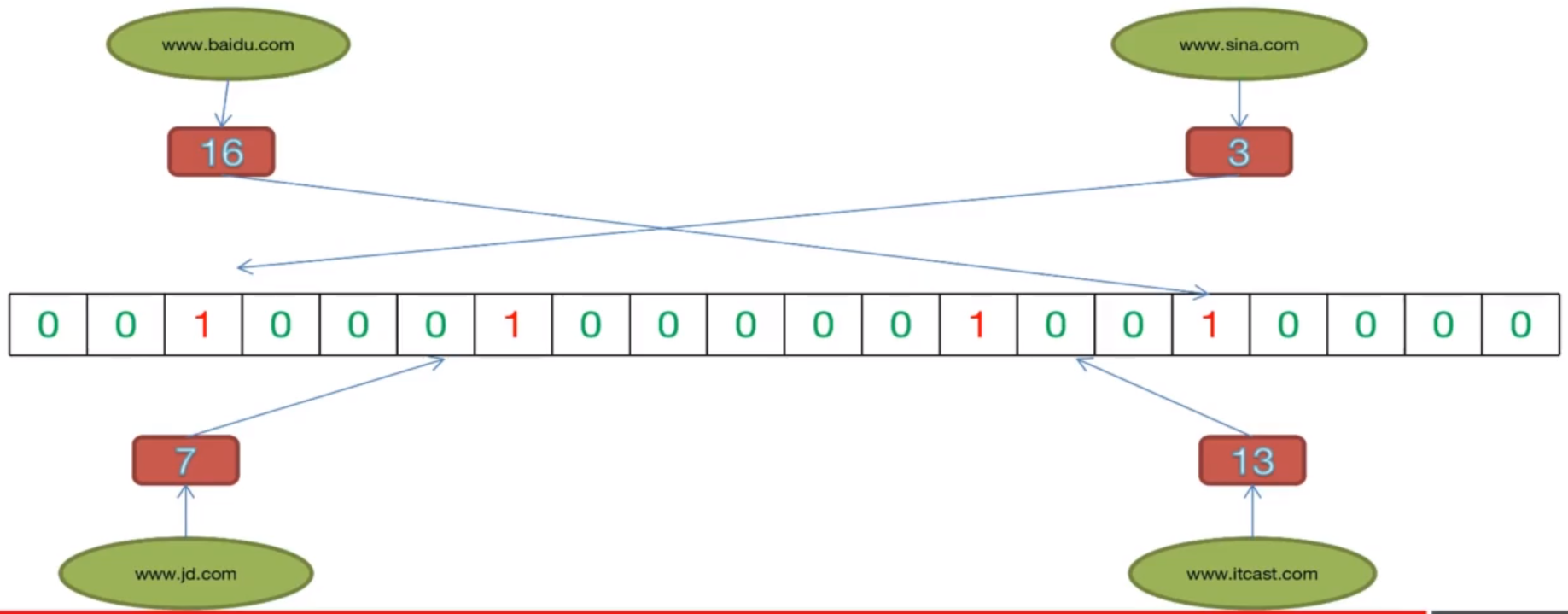
我们先按照简单的来,我们判断的是int数值是否存在,比方说1、3、6、7、13已经存在,那我们可以把对应位置的bit位,置为1,表示存在。如图:

这时候如果我们需要判断3是否存在的话,判断该位置的bit位是否为1即可。这样的话比我们声明一个int类型的数组,挨个存储,然后判断,省去了极大的空间,int值占用4个byte位也就是32个bit位,而采用这种bit数组来做,一下子省去了32倍的内存空间。
现在我们知道了,int的储存和判断方案,我们回归实际场景,比如判断一个url是否使用过。一个url是一个字符串,它不是一个int值,如何确定位置呢? 此时hash函数就派上用场了,我们可以将字符串hash出一个int值。
如图所示:
当然上图给出的是理想情况,而实际上我们很难找到一个足够好hash函数,使得到的hash值在非常小的范围内,通常一个好的hash函数算出的hash值足够随机且均匀,也就是说会随机的散列到0-integer.max_value的范围内,这是一个很大的值。
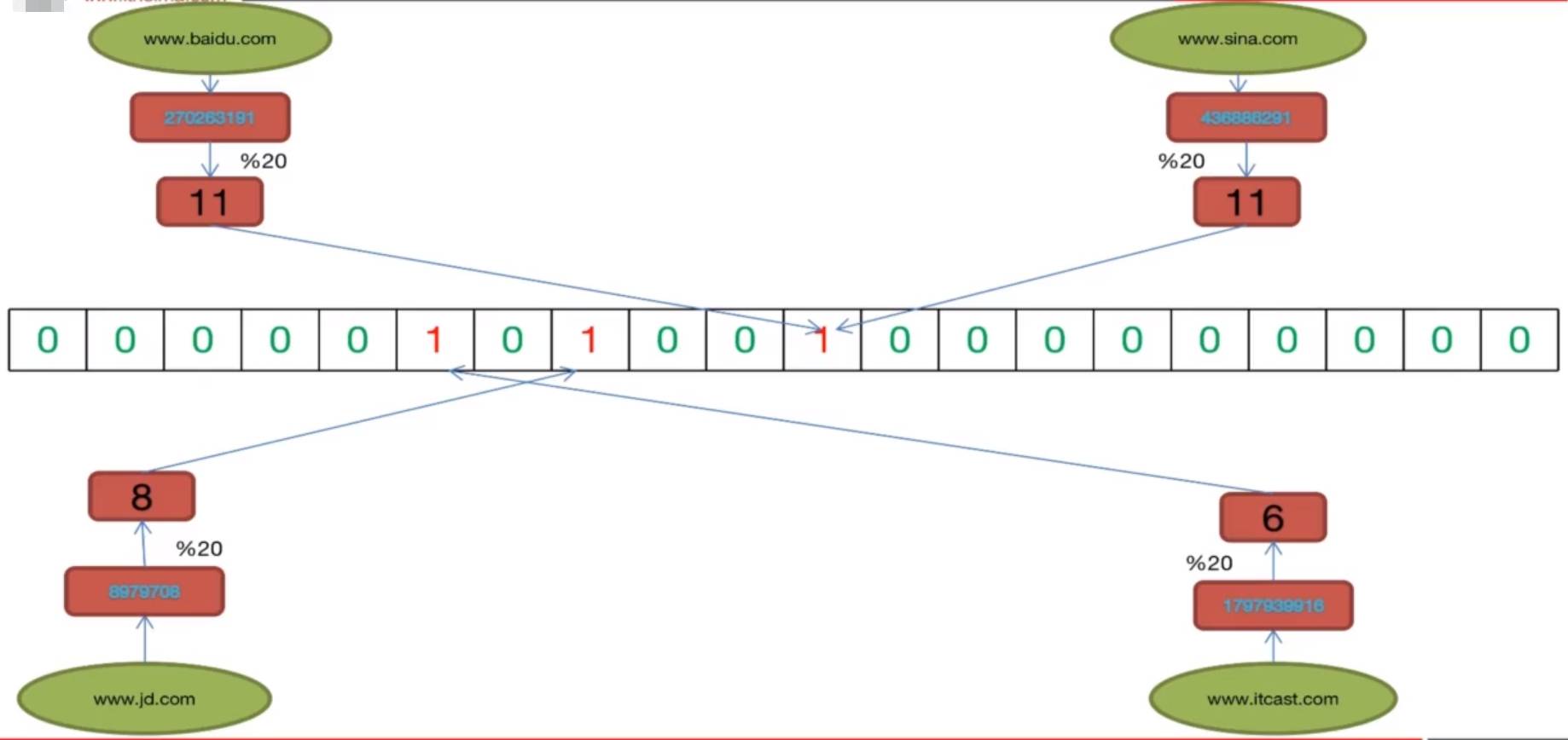
比方说www.baidu.com在java语言自带的hash函数得出的值为270263191,如果我们只有1000万个字符串需要判断,但是随便一个字符串的hash值有可能会大于1000万这个数值,所以声明1000万大小的bit位是不够用的,我们需要给出int最大值的bit位,而这会浪费大量的空间,与布隆过滤器的目标相悖。
这时候我们的取余法,就可以派上用场了,我们把得出的hash值进行对有限bit位空间(bit数组的长度)进行取余,得出位置。如图:
上图我们可以看出,使用取余法,我们可以做到在有限的空间上存储数据,达到了压缩空间的目的,但是大家可以发现这里会有一个冲突,有可能取余后我们的不同数据落到同一个位置,甚至我们的hash函数都有可能发生冲突,也就是不同的字符串算出的hash值是一样的。而且hash冲突几乎是不可避免的,这也就导致我们的位图上表示存在是有可能误判的。也就是布隆过滤器告诉你那个位置有数据了但有可能是别人放进去的,你并没有放进去。这是不可避免的,但是我们可以通过增加hash函数个数的方法来降低冲突率。如图:
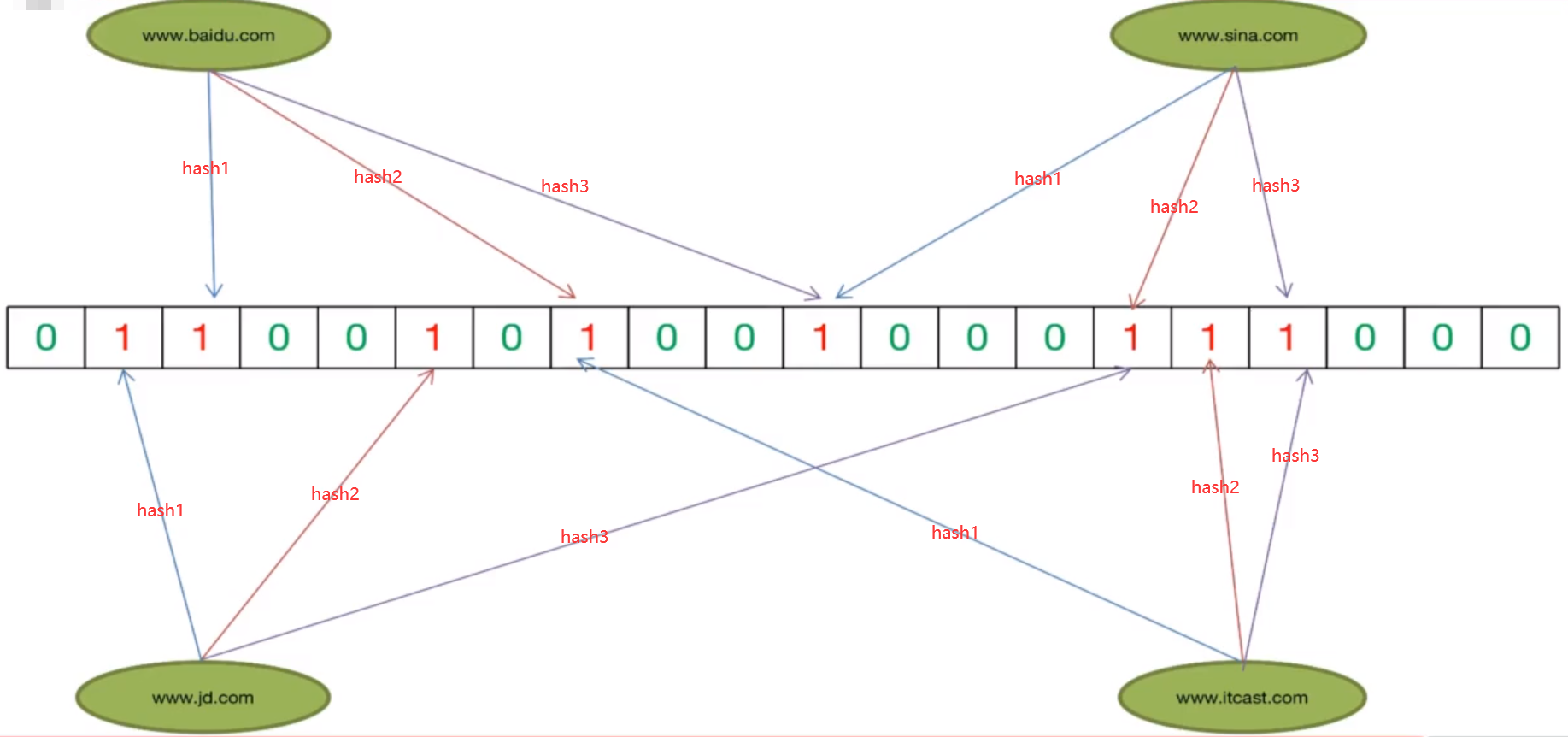
本例中采用3个不同的hash函数将同一个数据分别映射到位图的三个位置上,在判存的时候,只有当映射的这3个位置的bit值都为1时才表示该数据已存在,否则表示该数据不存在。这样可以在一定程度上降低误判率。
5、总结
布隆过滤器采用了位图数据结构,大大减少了内存占用,采用hash函数将数据映射到位图上,但是Hash函数本身就有冲突,取模节省空间也会导致冲突率的上升。解决的办法主要就是增加hash函数的个数和位图大小的上限(即加大bit数组的长度)。
至于要使用多少个hash函数合适以及位图的bit位多少合适没有非常严谨的数学证明,我们这里就不展开了。
市面上有一些现成的工具包已经给我们封装好布隆过滤器:比如google的guava包就实现了布隆过滤器。又比如redis4.0后通过插件方式提供了布隆过滤器的实现等等。。。
谨记:布隆过滤器有可能会存在误判的情况,也就是说,不存在的一定不存在,而存在的不一定会存在。
三、缓存雪崩
概念:缓存雪崩是指当缓存中有大量的key在同一时刻过期,或者Redis直接宕机了,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉。
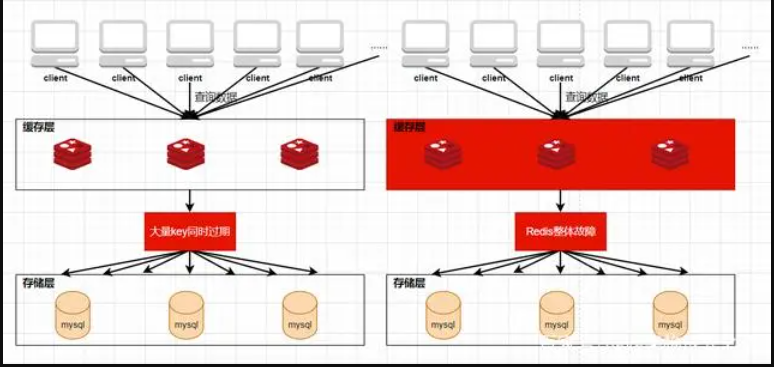
解决方案:
针对第一种大量key同时过期的情况,解决起来比较简单,只需要将每个key的过期时间打散即可,使它们的失效点尽可能均匀分布。例如:可以给过期时间加个过期因子(其实就是个随机数,比如:在1s~1000s 之间随机取一个),然后我们的实际过期时间=设置的过期时间+过期因子。
针对第二种redis发生故障的情况,部署redis时可以使用redis的几种高可用方案部署(主从复制模式、哨兵模式、集群模式)。
除了上面两种解决方式,还可以使用其他策略,比如设置key永不过期、加分布式锁等。
四、缓存穿透
概念:缓存穿透是指查询一个缓存中和数据库中都不存在的数据,导致每次查询这条数据都会透过缓存,直接查库,最后返回空。当用户使用这种不存在的数据疯狂发起查询请求的时候,对数据库造成的压力就非常大,甚至可能直接挂掉。
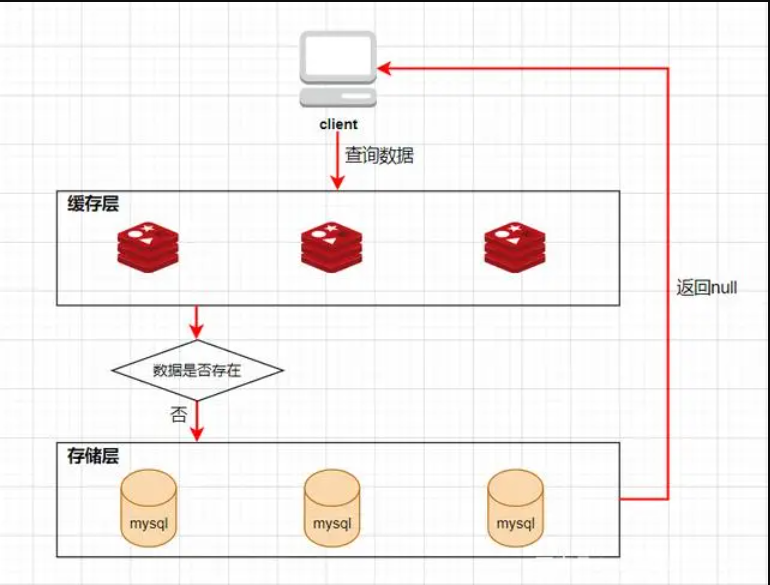
可能原因:恶意破坏。
解决方案:
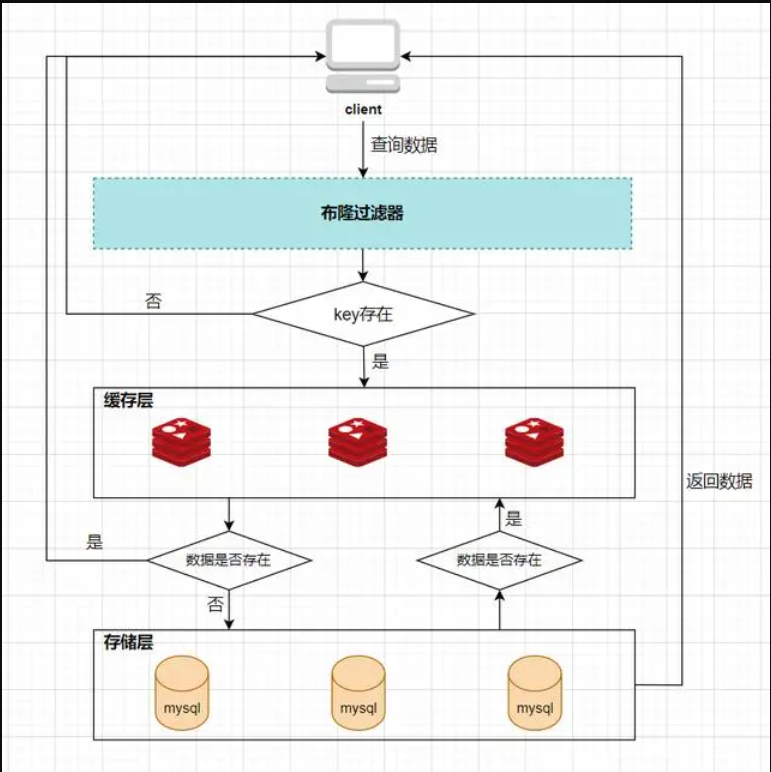
解决缓存穿透的方法一般有两种,第一种是缓存空对象,第二种是使用布隆过滤器。
第一种方法比较好理解,就是当数据库中查不到数据的时候,我缓存一个空对象,然后给这个空对象的缓存设置一个过期时间,这样下次再查询该数据的时候,就可以直接从缓存中拿到,从而达到了减小数据库压力的目的。但这种解决方式有两个缺点:(1)需要缓存层提供更多的内存空间来缓存这些空对象,当这种空对象很多的时候,就会浪费更多的内存;(2)会导致缓存层和存储层的数据不一致,即使在缓存空对象时给它设置了一个很短的过期时间,那也会导致这一段时间内的数据不一致问题。
第二种方案是使用布隆过滤器,这是比较推荐的方法。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误判率和删除困难。在初始化布隆过滤器时,需要将所有的key保存到布隆过滤器中,布隆过滤器就相当于一个位于客户端与缓存层中间的拦截器一样,负责判断key是否在集合中存在。如下图:
五、缓存击穿
概念:缓存击穿是指当缓存中某个热点数据过期了,在该热点数据重新载入缓存之前,有大量的查询请求穿过缓存,直接查询数据库。这种情况会导致数据库压力瞬间骤增,造成大量请求阻塞,甚至直接挂掉。
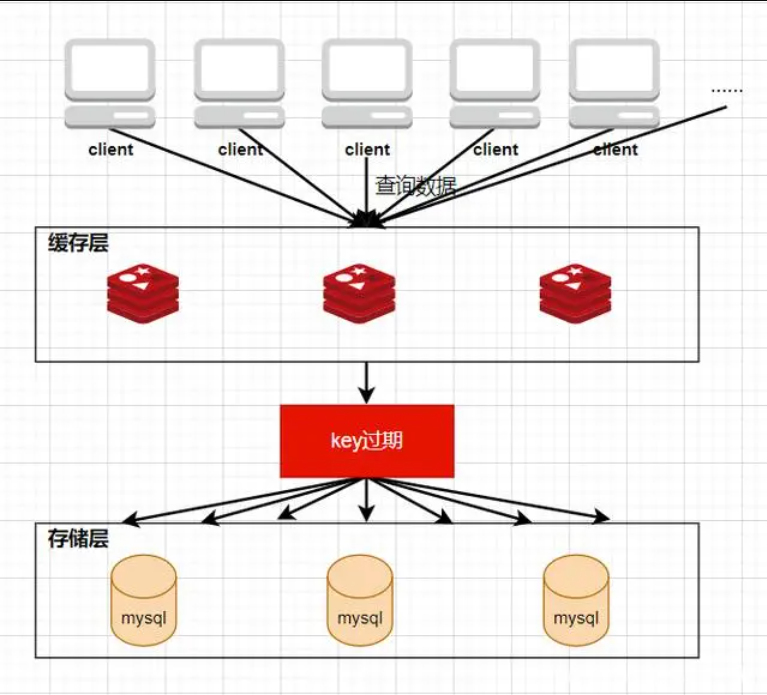
解决方案:
解决缓存击穿的方法也有两种,第一种是设置key永不过期;第二种是使用分布式锁,保证同一时刻只能有一个查询请求重新加载热点数据到缓存中,这样,其他的线程只需等待该线程运行完毕,即可重新从Redis中获取数据。
第一种方式比较简单,在设置热点key的时候,不给key设置过期时间即可。不过还有另外一种方式也可以达到让key不过期的目的,就是给key设置过期时间的时候,也要同时的在后台启一个定时任务去定时地更新这个缓存。
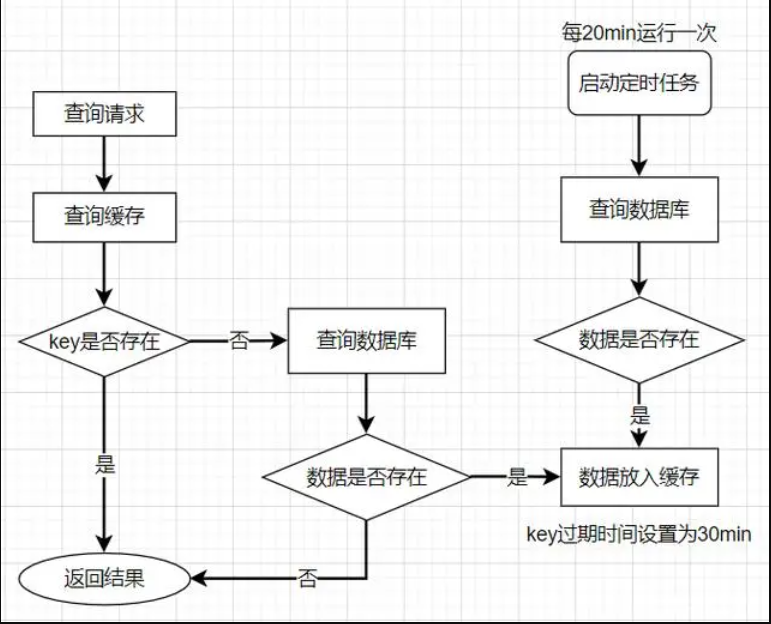
第二种方法使用加锁的方式,锁的对象就是key,这样,当大量查询同一个key的请求并发进来时,只能有一个请求获取到锁,获取到锁的线程查询数据库,然后将结果放入到缓存中,接着释放锁,此时,其他处于锁等待的请求即可继续执行,由于此时缓存中已经有了数据,所以可以直接从缓存中获取到数据返回,并不会查询数据库。
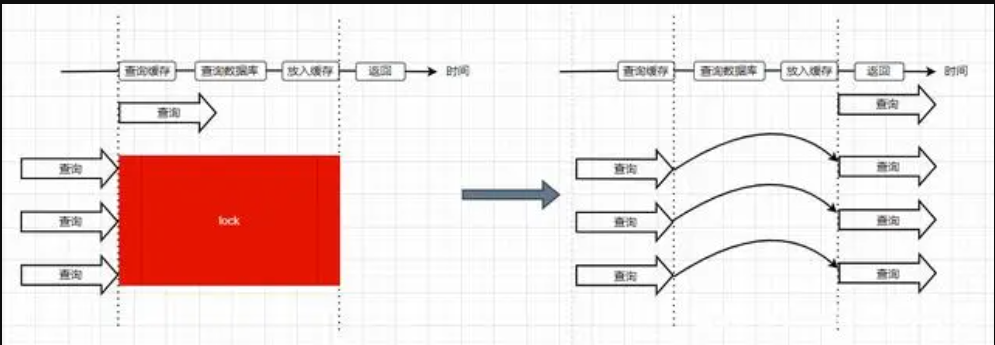
六、缓存预热
概念: 当系统上线时,缓存内还没有数据,如果直接提供给用户使用,每个请求都会穿过缓存去访问底层数据库,如果并发量大的话,很有可能在上线当天就会宕机,这种情况就叫“系统冷启动”。而缓存预热就是指系统上线后,提前将相关的缓存数据直接加载到缓存系统中。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。通常来讲,系统中一些经常使用的数据,一些高并发热点数据,可以先预热到缓存中;对于一些请求比较耗时的数据,也可以事先预热到缓存中。
解决方案:
1、直接写个缓存刷新页面,上线时手工操作下;
2、数据量不大,可以在项目启动的时候自动进行加载;
3、定时刷新缓存,缓存可能会过期,写一个程序,时不时把数据预热一下,往Redis里面写数据。
部分内容参考文献:https://baijiahao.baidu.com/s?id=1730541502423010481&wfr=spider&for=pc
Demo源码:
链接:https://pan.baidu.com/s/1RreI5HzAg-tW4WvWstm8ig 提取码:cm75
此文由博主精心撰写转载请保留此原文链接:https://www.cnblogs.com/xyh9039/p/17209010.html
版权声明:如有雷同纯属巧合,如有侵权请及时联系本人修改,谢谢!!!




