- A+
- 1.复制普通文件
- 2.linux查看ip的方式
- 3.linux登录之后的命令提示符
- 4.创建linux普通用户
- 5.vim编辑器, 文本编辑器
- vim替换
- 常用退出应用程序命令行:
- exit
- quit
- q
- deactive
- tengine
- 为什么要用nginx结合uwsgi
- #### 通过$ python3 manage.py collectstatic 收集所有你使用的静态文件保存到STATIC_ROOT!
- nginx配置来了!!!
- nginx配置如下:
- 安装启动redis数据库
- 问答
- redis的主从复制故障修复
- 查看redis主库,查看是否会自动的主从故障切换
- 安装ruby
- linux的容器技术
- 应用场景
- 互联网公司的技术栈
- vmware虚拟化技术
- docker vs 传统虚拟机
- 运行一个centos的docker容器
- 运行一个web内容的docker容器
- dockerfile的作用是创建一个docker镜像
- dockerfile的实际应用,创建一个flask镜像,基于这个flask镜像,运行web容器
- docker的web应用:
- dockerfile其他指令
- 修改容器内web程序页面
- 创建nginx镜像
- docker的私有仓库
- docker的公有仓库
- 生产者.py
- 消费者.py (可以运行多个消费者)
- 生产者.py
- 消费者.py(支持ack)
- 配置持久化的队列, 方式如下
- 运行依赖包:
- 1.环境准备, 两台服务器, 一个是master, 一个是minion
- 2.在两台机器上, 分别配置hosts文件, 配置本地dns服务器(dnsmasq 小型dns服务器)
- 3.在两台机器上, 分别配置好yum源, 下载saltstack软件
- 4.分别修改两个软件的配置文件,需要互相指定对方
- 写出你见过的配置文件格式
- master利用python的api操作两台minion关机
Linux
绝对和相对路径
绝对路径: 以根目录为起点的路径
相对路径: 不是以/这个根目录为源头划分的
xshell快捷键:
-
ctrl + l 清屏
-
ctrl + d 退出登录
-
ctrl + shift + r 快速重新连接
-
win + 空格 切换输入法
用户篇:
# 更改用户名 hostnamectl set-hostname <新的用户名> # 登出 logout 零碎Note:
linux的变量赋值不得有空格, 有空格就识别为参数了, example:
name = "zzy"#错误 name="zzy"#正确 更改主机名的命令
hostnamectl set-hostname 你想要的主机名 #重新登陆永久生效 动态链接库
LD_LIBRARY_PATH是Linux环境变量名,该环境变量主要用于指定查找共享库(动态链接库)时除了默认路径之外的其他路径 寻找最近的命令
#自下而上寻找最近的命令执行 !ps 代表执行时间最近的一条ps命令
poweroff 关机
reboot 重启
vim /etc/motd 编辑开机提示语
目录结构:

命令:
change directory cd命令:更改目录的意思 . 当前工作的目录 .. 上一级工作的目录 -上一次工作的目录 ~ 当前系统登录的用户家目录 list ls命令:列出文件对象 -a:显示出所有内容以及隐藏的文件(ALL) -l:列出文件详细信息 -h:与人类可阅读的方式输出文件大小 --full-time:以完整的时间格式输出 -t:根据最后修改时间排序文件 -F:在不同文件结尾,输出不同的特殊符号 以/结尾的就是文件夹 以*结尾的就是可执行文件 以@结尾的就是软连接,快捷方式 普通文件类型,结尾什么都没有 -d:显示文件夹本身信息,不输出其中的内容 -r:reverse 逆向排序 -S:针对文件大小进行排序 -i:显示文件的inode信息(文件身份证号码,存储了文件的元信息[文件的大小,位置,权限...]) 扩展: ll == ls -l linux隐藏文件, 以.开头例如: .secret pwd命令: print word directory 打印工作目录的意思,会输出当前所处的一个绝对路径 su:用户切换命令 语法 su - 用户名 # 完全的环境变量用户切换 logout: # 退出当前用户 新建目录
makedir make directory # 创建文件夹 语法: mkdir 文件夹名 参数用法: -p:递归创建文件夹 例如:mkdir - p /zzy/zzys/zzyss 移动目录
'move mv zzy ym # 表示把zzy重命名为ym mv ./zzy/ym ./ # 表示把当前目录下zzy里面的ym移动到当前目录(./) 新建文件
touch命令 touch zzy.txt zzy.exe touch alex{1..100} 创建多个文件方式 -t:修改文件的时间 示例:[touch -t zzy.txt 20220606] man 手册,解释linux的命令如何使用 man ls man 1.复制普通文件
cp zzy.txt '示例: cp mjj.txt ./oldboy/ #复制放入其他文件夹,保留源文件名 cp mjj.txt ./oldboy/mjj2.txt #复制文件并放入其他文件夹,且改名 cp mjj.exe mjj.png ./mjj/ #复制多个文件到指定文件夹中 cp -r mjj mjj2 #复制整个文件夹(递归赋值) 2.linux查看ip的方式
ifconfig # 查看网卡信息 ip addr show # 显示出ip网卡的信息 3.linux登录之后的命令提示符
[root@localhost ~]# 当前系统登陆的用户名 root @ 占位符 localhost 当前主机名 ~ 当前你所在的路径 # 超级用户的身份提示符 $ 普通用户的身份提示符 4.创建linux普通用户
useradd zzy <enter> # 创建的用户信息会放在 /etc/passwd这个文件下 passwd zzy #修改用户密码 5.vim编辑器, 文本编辑器
vi #如同win的记事本 vim #如同notepad++ 支持编程的编辑器 6.vim使用流程:
1.vim file_name // 此时进入了一个命令模式, 等待你输入相关的命令
2.如果你要编辑,就输入字母 i , 代表插入, 编辑(insert)
3.写完代码后, 退出编辑模式, 按
4.此时回到了命令名, 输入冒号 : 进入底线命令模式, 输入 :wq (w:写入)(q:退出)
:wq! 强制写入文本且退出vim
:q 不写入直接强制退出
:w! 只保存写入, 不退出
echo "zzy" # 向命令行输出一条消息 7.linux命令语法格式
linux命令 空格 参数(可有可无) 空格 你要操作的对象
linux参数的作用, 就是更好的服务于开发人员, 显示的更友好
ls -a #显示全部文件, 包括隐藏文件 ls -la #以列表形式详细输出文件信息 8.递归创建文件夹信息
mkdir --help man mkdir 中文man手册: 'http://linux.51yip.com' mkdir -p --------需求:创建s19文件夹, 下级有男同学, 女同学, 且女同学有个girl mkdir -p /tmp/s19/{nantongxue,nvtongxue/girl} 9.linux安装tree命令
yum install terr # linux-包管理器 10.linux特殊符号的含义
~ 用户家目录 - 上一次的工作目录 . 当前目录 .. 上一级目录 ./ 当前工作目录 > 重定向覆盖输出符号 w-模式 --example: echo "zzy" > zzy.txt --解释:等于写入zzy这句话到zzy.txt文件中, 如果zzy不存在则创建这个文件, 等同于py中的w模式 >> 重定向追加输出符号 a-模式 --example: echo "zzy" >> zzy.txt --解释:等于追加zzy这句话到zzy.txt文件中, 不会覆盖之前的内容 << 重定向追加写入符号(EOF->End Of File) --example: cat >>shi.txt<<EOF >#!coding:utf-8 >print('hello world') >EOF --解释:EOF一般会配合cat能够多行文本输出, 第一行为命令, 2,3行为输入的文本, 最后EOF代表结束. cat命令-文本
cat -n /etc/passwd # 查看文本并显示行号 11.more less
用于查看很大的文本, cat读取文件, 是一次性读取, 非常占内存, 用于读取小文本
more zzy.txt # 分页形式查看文本文件, 每次按下<enter>相当于下一页 12.linux下的搜索命令
`语法: find 从哪找 -name 你要找的文件名 `参数: -name 指定文件名字 -type 自定文件类型 f 文本类型 d 文件夹类型 `example: find / -name heeh.txt # 全局搜索 find /zzy1997 heeh.txt # 局部搜索 `解释: 可以从根目录寻找, 也可以从目标文件的上面的任何一级目录寻找 `进阶1: 找出zzy1997目录下的所有txt文件 find /zzy1997 -name *.txt # 通配符 `进阶2: 找出zzy1997目录下的所有python相关的文件信息 find /zzy1997 -name `进阶3: 找出zzy1997目录下的与python相关的文件, 目录 find ./ python -type d -name python* #找目录 find ./ python -type f -name python* #找文件 `查看命令的历史记录: history 13.linux管道符的用法
`语法: 第一条命令 | 第二条命令 `用于: 常用于查看linux进程信息 查看linux端口信息 `查看进程信息: ps -ef | grep python `查看linux端口信息: netstat -tunlp | grep 3306 #确认mysql是否启动了3306端口 netstat -tunlp | grep 8000 #验证django是否正常启动 `ip: 表示计算机在网络中地址的号码 0~255 ip范围 192.168.16.37 192.168.16.xx 这是大家的windows地址 `port: 表示应用服务的端口 80 http web服务端口 443 https 加密的http 3306 mysql 8000 django 22 ssh协议用的端口 ... #STDOUT:标准输出 #STDIN:标准输入 14.过滤字符串命令, 过滤文本信息
语法: grep 参数 你要过滤的字符串 你要操作的文件 参数: -i 忽略大小写 -v 是反转搜索结果 题目: 过滤调settings.py中无用的信息(空白行, 注释行) grep -v "^#" settings.py | grep -v "^$" 注意: $是null的意思 15.从文件的起始和结尾阅览内容
语法: head -5 <file_name> # 看文件的前5行 tail -5 <file_name> # 看文件的后5行 携带参数: tail -f <file_name> # 实时监测文件信息(flush) 16.运维开发的职责
后端开发, crm开发, 面向的是谁, 你的产品, 面向人类
运维开发做什么事? 运维+开发, 面向的是机器
监控平台开发, 主流监控软件 zabbix, nagios, 监控软件, 监控服务器状态
cmdb资产平台开发
运维堡垒机开发, 保护服务器安全
容器管理平台, 如: docker容器技术
17.别名alias
前言: 如何做到当你输入rm, 就提示用户, 你个大傻x, 求你别用rm了. 语法: alias # 显示各种命令的详情 alias rm="remove" # 把rm命令的名字变为remove alias rm="echo 哈哈哈" #把rm命令的-i提示语变成->哈哈哈 取消别名: unalias rm # 取消rm的别名设置 alias rm="rm -i" #或者重新赋值回之前默认的名称 18.远程传输命令
可以在两台linux之间互相传递文件
语法: scp <你想传输的内容> <你想传到的地方> # 上传 scp <你想要的内容> <存放的目录> # 下载 可选参数: scp <arg> -r 递归复制整个目录 -v 详细方式输出 -q 不显示传输进度条 -c 允许压缩 example: scp word.txt zzy@192.168.44.128:/tmp #上传 scp root@192.168.44.128:/tmp/word.txt /opt #下载 19.如何统计/var/log文件夹大小(查看文件夹大小)
方式1: ls -lh #详实的显示当前文件信息,和大小单位 方式2: du 命令 -h 显示 kb mg gb 单位 -s 显示合计大小 example: du -sh /var/log # 显示var/log文件夹合计大小并带单位显示 20.linux的任务管理器
top 21.给文件加锁 解锁
chattr +a 文件名 #给文件加锁 lsattr 文件 # 查看文件隐藏属性 22.linux的时间同步
date #查看当前系统时间 ntpdate -u ntp.aliyun.com #和阿里云的时间服务器同步(-u: update) 23.wget命令
```web get在线下载一个资源 wget url #下载资源到本地 '递归深层 wget -r -p http:luffycity.com # 递归, url递归深层爬取 24.linux和windows互传文件的软件 lrzsz
yum install lrzsz -y 命令: rz #接收文件(从win中接收文件) sz # =发送给文件(发送linux文件给win) example: sz csdn.png 可以从win中拖文件到shell命令行直接发送文件到linux端 25.linux下如何安装python3
1.yum安装
2.rpm包安装,需要手动解决依赖关系,很恶心
3.源代码编译安装(公司都用这种方式), 可以自定义软件版本, 以及功能扩展
编译安装python3的步骤:
1.下载python3的源代码 wget https://www.python.org/ftp/python/3.10.7/Python-3.10.7.tgz 2.解压缩源代码 tar -xf Python-3.10.7.tgz # tar是解压缩的命令 # -x是解压参数 # -f指定一个解压缩文件的名字 3.必须解决编译安装所需的软件依赖,比如OS的gcc等 yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel -y 4.解决了软件依赖关系, 就可以编译安装了 1.释放makefile,释放编译文件 cd Python-3.10.7/ ./configure --prefix=/opt/python310/#告诉编译器,python3安装到哪里(prefix: 指定安装路径) 2.执行make指令,开始编译,编译完成后进行安装 make && make install 3.配置python310环境变量 echo $PATH #显示系统环境变量 pwd #获取当前python.exe位置 -> /opt/python310/bin PATH="/opt/python310/bin://usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin" #添加python环境变量 # 但以上方式都是临时生效(临时赋值), 一旦重启linux就会销毁, 永久生效需要写入到linux 全局变量配置文件中/etc/profile vim /etc/profile #在最底行写入以下配置即可(相当于签订协议) PATH="/opt/python310/bin://usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin" # 然后读取配置文件生效(给协议盖章生效) source /etc/profile Tips: [ PATH: 每个command其实都存在一个目录里如/usr/local/bin... 可以用 which ls来查看-> alias ls='ls --color=auto' /usr/bin/ls 在Linux下很多命令是用python2写的,请不要擅自更改python为python3, 这样会导致很多命令无法使用, 必须使用python3或python3.x来运行你想要的版本 ] 26.linux切换用户
su <user_name> su root su zzy 在python中一个文件夹下有__init__.py文件, 那么这个目录我们称之为包
linux下进行django开发 1.创建django项目 django-admin startproject my_site 2.修改django配置 127.0.0.1 #本机回环地址, 只能自己访问到自己, 每台机器都有 0.0.0.0 #代表绑定这台机器所有的网卡,所有人均可访问(因为一台机器有不同的ip地址) 192.168.44.148 vlan0 vlan1 ... '关闭linux防火墙' iptables -F #清空防火墙规则 systemctl stop firewalld #禁用防火墙 systemctl disable firewalld #禁用防火墙永久 修改settings.py 参数allowed_host允许为 -> "*" 3.运行django项目 python3 manage.py runserver 0.0.0.0:8000 #如果项目启动在这个地址上, 绑定了这个机器的所有ip, 自己可以通过 127.0.0.1:8000 4.编写一个下课试图, 返回一个大家51快乐, 玩的嗨皮 27.网络
1.管理网络的命令
如果发现自己没有ip地址 1.保证vmware的网络小电脑亮着,如同插上了网线 2.管理网络的文件夹路径: /etc/sysconfig/network-scripts/ 3.查看管理网络的文件内容 ifcfg-ens33 这个就是网卡的配置文件了 4.确保一个参数是yes ONBOOT="yes" #代表机器启动时,就加载ip地址 5.通过命令重启网卡 systemctl restart network 系统服务管理命令 重启 网络服务 2.启停网卡的快捷命令
ifup ifdown 3.linux的用户限权篇
qq群角色分配
超级用户: 群主 root
拥有超级用户权限的人: 管理员 sudo 加上你的命令 (临时提权)
渣渣用户: 普通成员
权限的目的:便于管理
创建用户
useradd
更改用户密码
passwd <用户名>
root用户就是皇帝, 他的皇宫就在/root
普通用户,只有一个小破房子, 还是统一管理的地方/home
普通用户信息都存放到了/etc/passwd
4.查看linux用户的身份id信息
语法: id <用户名> #查看用户身份id 效果: [root@localhost etc] id zzy uid=1000(zzy) gid=1000(zzy) 组=1000(zzy),10(wheel) 解析: uid 用户id号码 gid group id 用户组 id groups 组id好码 系统超级用户uid默认是0 系统常用服务的用户 系统more会创建mysql用户,去执行mysql这个软件,他的id是从1-999之间 root创建的普通用户, 默认id是从1000开始的 用户组:一组同样身份信息的用户 用户, 普通用户 5.root可以随便更改别人的密码, 普通用户不行
6.用户切换
root可以随意切换普通用户 普通用户切换必须输入密码 su - zzy #切换用户(全切换,包括环境变量信息......) 7.临时提权的命令
1.修改sudoers配置文件, 把你想提权的用户写入进去 vim /etc/sudoers 2.写入如下信息, 可以定位到那一行 ## Allow root to run any commands anywhere zzy ALL=(ALL) ALL #允许zzy在任何地方, 执行任何命令 8.删除用户
userdel删除用户 参数: -f 强制删除用户 -r 同时删除用户及家目录 userdel -r pyyu tips: 如果直接 userdel zzy ,只会删除zzy用户在/etc/passwd存放的用户信息, 而用户的家目录会保留 9.linux的文件权限
'文件拥有者分为三类 属主 users 属组 group 其他人 other '权限主要分三重身份: * user/owner 文件使用者,文件属于哪个用户 * group 属组,文件属于哪个组 * others既不是user, 也不是group, 就是other, 其他人 -rw-r--r--. 1 root root 0 1月 11 16:55 haha.txt 限权 文件链接数 属主 属组 文件大小 修改日期时间 文件名 '什么是限权: 在Linux中每个文件都有所属的所有者,和所有组,并且规定了文件的所有者,所有组以及其他人对文件的, 可读, 可写, 可执行等权限. 对于目录的权限来说,可读是读取目录文件列表,可写是表示在目录内新增,修改,删除文件,可执行表示可以进入目录 '文件读写执行命令: cat 读 vim echo 写 ./文件 直接运行可执行文件, 以绝对路径和相对路径 sh first.sh #用linux自带的shell脚本执行 '文件夹的读写执行: ls 读 touch 写入文件到文件夹 cd 允许进入文件夹, 代表可执行 'linux的文件分类: - 普通文本 d 文件夹/目录 l 软连接 '文件/文件夹的权限: r read可读,可以用cat命令查看 w write写入,可以编辑或删除这个文件 x executable 可以执行 '实例解释-> -rw-r--r--. 1 root root 0 1月 11 16:55 haha.txt #-表示文本文件, rw指这个文件的属主root用户是可读可写但不可执行, 中间的r--表示只读(属组)root这个组的成员都可以读,后面两个--表示没权限,后面r--指的是其他人对这个文件的权限是只读. 10.更改文件权限
chmod 权限 文件/文件夹权限 -rw-r--rw-. 1 rrot root 79 May 5 09:58 nihao.txt '解析: - 普通文本 rw- 指的是root用户 可读可写不可执行(因为这是个文本文件无法执行) r-- 指的是root组里的成员, 只读 rw- 指的是其他人 可读可写 不可执行 '实例: `如何取消所有人对此文件(nihao.txt)的权限: chmod u-r,u-w,u-x nihao.txt #改属主的权限 chmod g-r,g-w,g-x nihao.txt #改属组的权限 chmod o-r,o-w,o-x nihao.txt #改其他人的权限 `让文件:nihao.txt 所有角色拥有全部权限 chmod 777 nihao.txt 限权分为: r 4 w 2 x 1 限权计算最高是4+2+1=7 最底是0 `练习chmod, 实现如下效果: ---xr---wx. 1 root root 79 May 5 09:58 nihao.txt chmod 143 nihao.txt -r--r---wx. 1 root root 79 May 5 09:58 nihao.txt chmod 443 nihao.txt tips:
| 权限分配 | 文件所有者 | 文件所属组 | 其他用户 |
|---|---|---|---|
| 权限项 | 读|写|执行 | 读|写|执行 | 读|写|执行 |
| 字符表示 | r|w|x | r|w|x | r|w|x |
| 数字表示 | 4|2|1 | 4|2|1 | 4|2|1 |
11.更改文件的属主/属组
chown <用户名> <要操作的文件> #更改文件属主 chgrp <用户组> <要操作的文件> #更改文件属组 12.软连接
语法: ln -s 目标文件 快捷方式(绝对路径) 13.linux的命令提示符
PS1变量 echo $PS1 #显示命令提示符 PS1="[u@h w t]$" #修改命令提示符 pyyu: 可以自行调整全局变量/etc/profile文件用于永久生效 PS1='[u@h Wt]$' d 日期 H 完整主机名 h 主机名第一个名字 t 时间24小时制HHMMSS T 时间12小时制 A 时间24小时制HHMM u 当前用户账号名 v BASH的版本 w 完整工作目录 W 利用basename取得工作目录名 # 下达的第几个命令 $ 提示字符,root为#,普通用户为$ PS1 > 变量名 $PS1 > 查看变量内容 PS1=新内容 重新赋值 变量赋值,查看 name='chaoge' echo $name PS1显示ip地址 export PS1="[u@h `/sbin/ifconfig ens33 | sed -nr 's/.*inet (addr:)?(([0-9]*.){3}[0-9]*).*/2/p'` w]$" 14.linux的打包,解压的命令
tar命令: '参数: -A或-catenate 新增文件已存在的备份文件 -B 设置区块大小 -c或--create 建立新的备份文件 -C <目录> 这个选项用在解压缩,若要在特定的目录解压缩, 可以使用这个选项 -d:记录文件的差别; -x或--extract或--get:从备份文件中还原文件; -t或--list:列出备份文件的内容; -z或--gzip或--ungzip:通过gzip指令处理备份文件; -Z或--compress或--uncompress:通过compress指令处理备份文件; -f<备份文件>或--file=<备份文件>:指定备份文件; -v或--verbose:显示指令执行过程; -r:添加文件到已经压缩的文件; -u:添加改变了和现有的文件到已经存在的压缩文件; -j:支持bzip2解压文件; -v:显示操作过程; -l:文件系统边界设置; -k:保留原有文件不覆盖; -m:保留文件不被覆盖; -w:确认压缩文件的正确性; -p或--same-permissions:用原来的文件权限还原文件; -P或--absolute-names:文件名使用绝对名称,不移除文件名称前的“/”号; -N <日期格式> 或 --newer=<日期时间>:只将较指定日期更新的文件保存到备份文件里; --exclude=<范本样式>:排除符合范本样式的文件。 '重要: -c 打包 -x 解包 -z 调用gzip目录取压缩文件,节省磁盘空间 -v 显示打包过程 '实例: 压缩当前的所有内容到alltmp.atr这个文件中, 这里不节省磁盘空间 tar -cvf alltmp ./* 压缩tmp下的zzy文件夹为zzy.tar.gz tar -zcvf zzy.tar.gz zzy 解压的方式 tar -zxvf 压缩文件的名字.tar.gz 打包文件,并且压缩文件大小的用法 tar -zcvf 压缩文件的名字.tar.gz 15.django程序起来,如何检测呢?
1.去浏览器检测是否可以访问, 127.0.0.1:8000 2.确认django的端口是否启动 netstat -tunlp | grep 8000 2.确认django的进程是否存在 ps -ef | grep python 16.杀死进程的命令
kill 进程id kill -9 进程id #强制杀死进程 17.支持正则的kill命令(慎用)
pkill 进程的名字 pkill -9 进程名字 #强制杀死 18.显示磁盘空间大小
df df -h 以单位显示 19.什么是DNS(域名解析系统),其实就是一个超大的网络电话簿
dns就是域名解析到ip的一个过程, 大型公司,用的dns服务名叫做bind软件 提供dns服务的公司有: 119.29.29.29 腾讯 223.5.5.5 阿里 223.6.6.6 阿里 8.8.8.8 谷歌的 114.114.114.114 114公司的 linux的dns配置文件如下: vim /etc/resolv.conf 里面定义了dns服务器地址 linux解析dns域名 nslookup 域名 20.dns解析流程,当你在浏览器输入一个url,有了那些解析
pythonav.cn:80/index.html 解析流程: 1.浏览器首先在本地机器操作dns缓存中查找是否有域名-ip的对应记录 2.去/etc/hosts文件中寻找是否写死了域名解析记录 3.如果hosts没写,就取/etc/resolv.conf配置文件中寻找dns服务器地址 4.如果找到了对应的解析记录,就混存到本dns缓存中 /etc/hosts 本地强制dns的文件 21.linux的定时任务
语法: 分 时 日 月 周 * * * * * 命令的绝对路径 实例: #每分钟执行一次命令 * * * * * 命令的绝对路径 #每小时的3,15分组执行命令 3,15 * * * * 命令的绝对路径 #晚上的8-11点的第3和第15分钟执行 3,15 20-23 * * * 命令的绝对路径 #每晚的21:30执行命令 30 21 * * * 命令的绝对路径 #每周六,周日的1:30执行命令.(7或0都可以代表周日) 30 1 * * 6,7 命令的绝对路径 #某周一到周五的林晨一点,清空/tmp目录的所有文件 00 1 * * 1-5 /usr/bin/rm -rf /tmp/* #每晚的21:30重启nginx 30 21 * * * /usr/bin/systemctl restart nginx #每月的1,10,22日的4:45重启nginx 45 16 1,10,22 * * /usr/bin/systemctl restart nginx #每个星期一的上午8点到11点的第3和第15分钟执行命令 3,15 8-11 * * 1 22.linux的软件包管理
软件包的格式(了解即可): win: exe mac: dmg linux: rpm 安装软件的方式: 1.yum安装(自动搜索你想要的软件包,以及他的依赖关系,自动解决下载) 2.源代码编译安装 3.手动安装rpm包(手动解决依赖关系) rpm命令的使用方式: 安装 rpm -ivh xxx.rpm #i安装,v显示详细过程,h进度条显示 升级 rpm -Uvh xxx.rpm 卸载 rpm -e xxx.rpm linux配置阿里云的yum源, 配置步骤如下
1.找到阿里的镜像站: https://opsx.alibaba.com/mirror 2.通过命令在线下载yum源(-) wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo 下载epel,选择epel(RHEL 7) wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo # 在线下载repo仓库文件,并且重命名,放到/etc/yum.repos.d/这个目录 下-O就是改名,且下载到指定位置 3.备份默认的yum仓库 Linux的yum仓库地址说 -> /etc/yum.repos.d 在这个目录的第一层文件夹下,名字以*.repo结尾的都会被识别为yum仓库 例如 -> /etc/yum.repos.d/xxx.repo 配置: cd /etc/yum.repos.d mkdir backrepo mv * ./backrepo 4.测试安装mariadb数据库(其实就是MySQL) yum install mariadb-server mariadb -y 5.启动数据库 systemctl start mariadb 6.可以测试访问mysql数据库了 mysql -uroot -p 7.更新yum缓存 yum clean all && yum makecache 系统服务管理命令(只有通过yum安装的软件,才可以用系统服务管理命令)
1.如果是centos6就是 service nginx start 3.如果是centos7就是 systemctl start/stop/restart nginx 230130
作业
作业 1.配置好阿里云yum源 生成yum缓存 下载nginx,并启动nginx服务,使用浏览器访问nginx页面 2.备份原来的yum源,原本是centos.repo国外的数据缓存 3.下载阿里云的yum源文件,两条wget命令下载repo仓库文件 4.清空原本的yum缓存, yum clean all 5. yum makecache生成yum缓存 6. yum install nginx -y yum源的工作目录是? /etc/yum.repos.d/ 在这个目录下所有名字是*.repo的文件,就会背识别为仓库文件 2.下载lrzsz工具,方便win和linux互传文件 yum install lrzsz -y 3.如何手动启动网卡?(如果发现自己没有ip地址) 语法: ifup 网卡名 实例: ifup ens33 ifup eth0 systemctl start network 4.linux的超级用户是什么?如何查看用户身份信息? root id root 5.简述linux的用户管理 useradd zzy 添加用户 userdel zzy 删除用户 passwd zzy 更改用户密码 1.用户角色有 usergroup other 2.超级root 普通用户是root创建的 3.root超级用户uid是0,普通用户uid从1000开始 普通用户执行命令权限不足时可以配置sudo命令即可 6.如何使用普通用户登录 ssh 7.在linux下如何切换用户 su -用户名 8.如何使用root身份执行普通用户的命令?请详细说明配置步骤 1.修改/etc/sudoers文件 2.找到: root ALL=(ALL) ALL zzy ALL=(ALL) ALL 3.保存退出即可 4.sudo ls /root 5.可以使用visudo命令提供语法检测,更正规 9.简述linux的文件权限有哪些? r w x 4 2 1 777 10.linux文件权限的755,700是什么意思? -rwxr-xr-x -rwx------ 11.如何修改test.py文件权限为700 chmod 700 test.py 12.如何修改test.py属组是oldboy? chgrp oldboy test.py 13.已知test.py文件权限是rwxr--r--,如何修改权限为rw-rw-rw chmod 666 test.py 14.linux如何建立软连接? ln -s opt/python3/bin /usr/local/python3 ln -s 目标绝对路径 快捷方式绝对路径 15.linux的PS1变量是什么?如何修改 PS1是控制命令提示符的 PS1='{u@h wt}$' (变量赋值临时生效) 系统全局环境配置文件, 针对每一个用户 /etc/profile 16.centos7用什么命令管理服务? systemctl centos6: service 17.linux解析dns的命令是什么? nslookup www.oldboydu.com cat /etc/resolv.conf 18.将/tmp/下所有内容压缩成all_log.tar.gz并且放到/home下 tar -zcvf /home/All.log.taar.gz /tmp/* -z调用gzip压缩指令 -c进行打包 -v显示过程 -f指定一个文件,这个参数必须写在最后 19.解压缩Python源码包Python-3.7.0b3.tgz tar -zxvf Python-3.7.0b3.tgz 20.查看mysql端口状态 netstat -tunlp | grep 3306 #查到记录了,说明机器开放了3306端口,mysql启动了 21.如何查看nginx的进程 ps -ef | grep "nginx" 22.如何杀死nginx进程 kill nginx的pid pkill nginx 23.如何修改linux中文 1.保证linux的编码是utf-8 2.保证你登陆的xshell也是utf-8 3.中文统一对应 24.如何统计/var/log大小 du -sh /var/log 25.tree是什么作用? 以树状图显示文件夹内容 26.如何给linux添加一个dns服务器记录 dns服务器记录在 /etc/resolv.conf 文件里 可以用echo追加,也可以vim编辑添加 但注意只能添加最多两条记录 27.每月,5,15,25天的晚上5点50重启nginx * * * * * 50 17 5,15,25 * * /usr/bin/systemctl restart nginx 28.每周3到周5的深夜11点备份/var/log/放到/tmp目录下 00 23 * * 3-5 /usr/bin/cp -r /var/log/ /tmp 29.每天早上6.30清空/tmp内容 * * * * * 30 6 * * * /usr/bin/rm -rf /tmp/* 30.每个周三下午6点到8点的第5,15分钟执行命令 command 5,15 18-20 * * 3 command 31.编译安装软件有哪些步骤? 注意要解决软件依赖关系 1.下载软件源码 2.解压缩源码包 3.进入源码包目录 4.编译三部曲 释放makefile, 执行configure脚本, 并且指定安装路径 开始编译, 执行make指令 编译安装 make install 32.如何修改python3环境变量, 以及软连接 #软连接方式: ln -s /opt/python310/bin/python3.10.7 /usr/bin/python3 #配置PATH变量 33.请在linux上启动ob_crm, windows上进行访问,进行登录 1.如何代码在码云上可以git clone 2.如果在win上可以通过lrzsz发送到linux 3.如果是压缩文件,进行解压缩,生成代码文件 4.修改配置文件,allow_hosts=["*"] 5.如果用的是mysql, 还得提前启动mysql,并且注意settings.py数据库连接配置 6.迁移数据库 7.解决所有crm依赖的模块, 如django, pymysql 8.启动,注意ip地址和端口的问题 9.pip装的包,发给到解释器的site-packages目录下 10.yum安装的软件,是自动安装的路径, 可以通过rpm -ql查询安装路径 11.如果向指定路径安装用源码包编译安装 34.一月一日的4点重启nginx 00 4 1 1 * /usr/bin/systemctl restart nginx 35.每月4号与每周一到周三的11点重启nginx 00 11 4 * 1-3 /usr/bin/systemctl restart nginx 36.每小时重启一次nginx? 0 * * * * /usr/bin/systemctl restart nginx 37.每天10:00,16:00重启nginx 00 10,16 * * * /usr/bin/systemctl restart nginx 38.如何查看系统发行版信息? cat /etc/os-release 39.系统全局环境变量的配置文件? /etc/profile 40.系统用户的环境变量配置文件是? 修改~/.bash_profile(首选),将影响当前用户. 在~/.bash_profile文件中添加 41.如何查看内存大小信息? cat /proc/meminfo | grep MemTotal free -m 42.如何查看cpu核数? cat /etc/proc/cpuinfo top <键入1> lscpu 43.如何停止centos7防火墙服务,并且禁止防火墙开机自启? #防火墙作用: 保护服务器的流量网络安全, 允许/禁止 ip地址段和端口的出入流量 systemctl stop firwalld.service #关闭防火墙服务 systemctl disable firwalld.service #紧张防火墙开机自启 iptables -f #清空防火墙规则 vim
移动光标: w(e) 移动光标到下一个单词 b 移动到光标上一个单词 数字0 移动到本行开头 $ 移动光标到本行结尾 H 移动光标到屏幕首行 M 移动到光标到屏幕中间一行 L 移动光标到屏幕的尾行 gg 移动光标到文档的首行 G 移动光标到文档尾行 ctrl+f 下一页 ctrl+b 上一页 `. 移动光标到上一次的修改行 查找: /change 在整篇文档中搜索change字符串,向下查找 ?change 在整篇文档中搜索change字符串,向上查找 *查找整个文档,匹配光标1所在的单词,按下n查找下一处,N上一处 # 查找整个文档,匹配光标所在的所有单词,按下n查找下一处,N上一处 gd 找到光标所在单词匹配的单词,并停留在非注释的第一个匹配上 % 找到括号的另一半!! 略... ------------------------------------------------------------ 设置vim的tab键为4个空格 vim /etc/vimrc 底部写入以下内容: set ts=4 ----------------------------------------------------------- vim替换
# Vim替换字符串命令的语法 # Vim替换字符串命令的基本语法是 :[range]s/目标字符串/替换字符串/[option],其中range和option字段都可以缺省不填。 # 下面介绍VIM替换字符串各个变量的含义: range:表示搜索范围,默认表示当前行; range字段值1,10表示从第1到第10行; %表示整个文件(相当于1,$); 而.,$代表从当前行到本文件的末尾 s:substitute的简写,表示执行替换字符串操作; option:表示操作类型,默认只对第一个匹配的字符进行替换; option字段值g(global)表示全局替换; c(comfirm)表示操作时需要确认; i(ignorecase)表示不区分大小写; vim替换字符串的这些选项可以组合使用 命令行补充:
在命令行中tab代表补全 双tab代表显示提示
方向上 补全上一条指令
方向下 回到下一条指令
ctrl + c 强制结束进程
ctrl + insert 复制
shift+ insert 粘贴
常用退出应用程序命令行:
exit
quit
q
deactive
python虚拟环境
1.python虚拟环境, 用于解决python的环境依赖冲突的问题,仅仅是多个解释器的分身,多个解释器的复制,和操作系统无关 2.python虚拟环境的工具有很多:virtualenv, pipenv, pyenv 3.virtualenv可以在系统中建立多个不同并且相互不干扰的虚拟环境 注意: 确保python3成功的安装,并且PATh配置在第一天路劲 virtualenv的学习安装使用 1.下载安装 pip3 install virtualenv 2.安装完毕,就可以使用命令创建虚拟环境使用了 #这个命令在哪敲,就会在那生成 virtualenv --no-site-packages --python=python3 venv #参数解释 --no-site-packages #没有任何的第三方包,用于构建干净的环境 --python=python3 #指定python虚拟环境的本体,是py的哪个版本 venv 就是一个虚拟环境的文件夹,是虚拟python解释器 3.创建完毕venv虚拟环境,就可以激活使用了 进入venv/bin目录下 source activate #source是读取指令,读取这个activate脚本中的内容,激活虚拟环境 4.验证虚拟环境是否正确 which pip3 which python3 都来自与venv路径,就是对了 5,使用虚拟环境,分别构建django1和django2的平台 注意, 开启2个linux窗口 步骤1:分别下载两个venv1 venv2, 用于运行不同的django virthualenv --python=python3 venv1 virthualenv --python=python3 venv2 步骤2:这两个虚拟环境,都得单独激活去使用 source venv1/bin/activate #激活虚拟环境 source venv2/bin/activate #激活虚拟环境 deactivate #退出虚拟环境 保证本地开发环境和线上一致性的步骤
1.导出本地python的环境的所有模块 pip3 freeze > requirements.txt 2.将这个依赖文件发送给服务器linux requiements.txt 3.服务器linux上,构建虚拟环境,安装这个文件,即可 pip3 install -r requirements.txt virtualenvwrapper的学习使用
1.安装 pip3 install virtualenvwrapper 2.配置环境变量,每次开机都加载这个工具,注意的是配置的是个人环境配置变量配置文件 export WORKON_HOME=~/Envs # 设置virtualenv的统一管理目录 export VIRTUALENVWRAPPER_VIRTUALENV_ARGS='--no-site-packages' #添加virtualenv的参数,生成干净隔绝的环境 export VIRTUALENVWRAPPER_PYTHON=/usr/local/python3/bin/python3 #指定python解释器,虚拟环境以谁去分身 export /usr/local/python3/bin/virtualenvwrapper.sh #执行virtualenvwrapper安装脚本 3.此时退出linux终端回话,重新登录,rangvirtualenvwrapper工具生效 4.学习virtualenvwrapper命令,管理虚拟环境 mkvirtualenv 虚拟环境的名字 #创建虚拟环境, 存放目录是统一管理的 workon 虚拟环境的名字 #可以在任意目录直接激活虚拟环境(切换) 例如从venv1, 切换到venv2 deactivate #退出虚拟环境 rmvirtualenv 虚拟环境的名字 #删除虚拟环境 lsvirtualenv #列出所有虚拟环境 cdvirtualenv #进入虚拟环境的目录 cdsitepackages #进入虚拟环境的第三方包 mkvirtualenv -p /opt/python3.6.4/binpython3.6 #指定python版本安装 nginx
nginx web server
1.静态网站,静态虚拟主机的作用 就是不变化的网页,静态的html,css,js的页面, 以及各种图片视频的资源 有一些草根站长,放一些小说, 图片等等... 2.动态网站 指的是,可用于数据库打交道,数据交互的网页,网页内容根据数据库的数据变化 登录功能,有注册功能的... 并且有编程语言支持的 3.nginx的并发非常强悍 轻松支持10w+并发连接数 tnginx 4.常见web服务器有哪些? win下 -> IIS服务器 linux下 -> nginx apache lighthttp apache采用多进程方式非常吃系统资源 nginx采用异步非阻塞, 轻量级, 稳定丰富的功能, 系统资源消耗低且高并发 5.web服务器 nginx 这样的软件 web服务器它自己不支持变成, 仅仅是页面返回, nginx + lua web框架的概念 django flask tornado web逻辑框架 支持程序员自己写代码,进行逻辑处理 6.nginx是web服务器, 反向代理服务器, 邮件代理服务器, 反向代理,负载均衡, 支持高并发的一款web服务器 7.nginx安装方式 1.yum 2.rpm手动 3.源代码编译安装,选择这个,支持自定义的第三方功能扩展,比如自定义安装路劲,支持https,支持gzip资源压缩 8.选择源码编译安装 1.下载淘宝nginx(tengine)的源码包 wget http://tengine.taobao.org/download/tengine-2.3.0.tar.gz 2.解压缩源码包 tar -zxvf tengine-2.2.0.tar.gz 3.进入源码目录开始编译安装 ./configure make&&make install 4.配置淘宝nginx的开发环境 PATH="/usr/local/python3/bin://usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/opt/tngx230/sbin" 读取/etc/profile source profile 5.启动nginx,不得再启动第二次 nginx #启动 nginx -s reload #平滑重启nginx,重新读取nginx配置文件 nginx -s stop #停止nginx进程 nginx -t #对配置文件信息进行语法检测 6.学习nginx的目录配置文件信息 client_body_temp html sbin conf logs scgi_temp fastcgi_temp proxy_temp uwsgi_temp #解释目录 conf 存放nginx配置文件的 html 存放前端文件目录, 首页文件就在这里 logs 存放nginx运行日志,错误日志的 sbin 存放nginx执行脚本的 7.部署一个web站点 修改index.html文件, 即可查看新页面内容 8.nginx配置文件学习 见下一个nginx代码块 9.nginx的错误页面优化 打开nginx.conf里面的如下参数 error_page 404 /404.html; 10.nginx的访问日志功能 打开如下功能参数 log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log logs/access.log main; 11.nginx限制访问功能 就是nginx.conf中 找到location参数,写入如下信息 location / { deny 192.168.44.189; #禁用某个用户的ip地址 deny 192.168.16.0/24; /24子网掩码地址 255.255.255.0 root html; #定义网页根目录的,是nginx目录下的html index index.html index.htm; #指定首页文件的名字 } 12.nginx的状态信息功能, 检测当前有多少个链接数 再nginx.conf下打开一个参数即可 #当你的请求来自于 192.168.16.37/ location /status { #开启nginx状态功能 stub_status on; } 使用linux的压测命令,给nginx发送大量的请求 ab命令 安装方式 yum install httpd-tools -n requetst #执行的请求数,即一共发起多少请求. -c concurrency #请求并发数. -k #启用HTTP KeepAlive功能, 即在一个http会话中执行多个请求 url格式必须如下 ab -kc 1000 -n 100000 http:/192.168.44.160/ 13.多虚拟主机,在一台服务器上运行多个网络页面 基于多域名的虚拟主机实现, 其实就是读个server标签 环境准备, 1个linux服务器, 192.168.44.160 2个域名, 写入hosts文件,强制 www.s19dnf.com www.hanju.com 修改nginx.conf, 也就是写两个平级的server, 并且更改server_name 14.nginx的反向代理功能 1.见过生活中的代理 客户端(请求资源) -> 代理(转发资源) -> 服务端(提供资源) 客户端和nginx `示例: nginx与django联合, nginx负责静态页面, 当请求为动态需要涉及到数据库操作, nginx将转发请求给django, 由django负责. 正向代理: 多人连接到proxy,由proxy去访问再提供给用户 反向代理: 配置nginx实现反向代理的步骤: 环境准备两台机器 192.168.43.156 充当资源服务器, 提供一个页面 192.168.43.6 充当代理服务器的角色(转发请求, 反向代理的功能也是nginx提供的) --修改如下配置(nginx.conf) #当你的请求来自于192.168.43.156/这样的url时就进入如下路径 匹配 location / { #当请求进来这个路径匹配,这个nginx代理角色,直接转发给>资源服务器 proxy_pass 192.168.43.156; } 3.测试访问反向代理的页面 nginx反向代理原理图
client端访问 --> ng2(代理服务器) --> 找ng1拿取资源 --> 回馈给用户 nginx配置文件内容如下:
#全局变量写在最外层 #user nobody; worker_processes 4; events { worker_connections 1024; } #定义nginx核心功能的参数 http { include mime.types; default_type application/octet-stream; #定义nginx访问日志格式的 #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; #access_log "pipe:rollback logs/access_log interval=1d baknum=7 maxsize=2G" main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; 图片压缩资源压缩 #gzip on; nginx主页面功能都是server参数提供的 server被称作是虚拟主机 server { #nginx监听的端口 listen 80; #填写服务器的域名, 或者ip, 或者localhost server_name localhost; #路径匹配, 当你的请求来自于192.168.16.37/就进入以下的location路劲匹配 location / { root html; #定义网页根目录的,是nginx目录下的html index index.html index.htm; #指定首页文件的名字 } #错误页面 #当请求返回404错误码的时候, 就给用户看到一个页面 #这个404.html放在网页根目录下 error_page 404 /404.html; # redirect server error pages to the static page /50x.html error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } } nginx知识点
支持高并发,能支持几万并发连接 资源消耗少,在3w并发连接下开启10个nginx线程消耗内存不到200m 可以做http反向代理和负载均衡 支持异步网络i/o事件模型epoll tengine
由淘宝网发起的web服务器项目,在nginx基础上,针对大量访问网站的请求,添加了很多高级功能和特性.tengine的性能和稳定性已经在大型网站如淘宝天猫商城得到很好的验证.他的最终目的是打造一个高效,稳定,安全,易用的web平台 nginx参数篇
worker_processes 4; # 设置工作进程数 内容小结
1.编译安装tengine服务
编译三部曲 1.解决软件编译安装所需的依赖 2.下载软件源代码包, 并且解压缩出源码包内容 3.进入源码包目录, 执行./configure --prefix=安装绝对路径, 释放编译文件, makefile 4.调用linux的编译器 make && make install 开始安装软件 2.nginx的核心工作目录
conf 存放nginx.conf的目录, 功能配置都在这 logs 存放err.log access.log html (网页根目录) 存放index.html 404.html 3.nginx提供web服务器页面的功能参数就是server{ }虚拟主机标签
#server虚拟主机,nginx会自上而下的加载, 因为可能有多个虚拟主机 #虚拟主机定义了网站的端口, 域名, 网页内容存放路径 server { listen 80; server_name www.s19dnf.com; location / { root /opt/dnf/; index index.html index.html; } } #nginx支持多虚拟主机,也就是通过多个server标签实现的 server { listen 80; server_name www.s19dnf.com; location / { root /opt/dnf/; index index.html index.html; } } #nginx会根据用户访问的url域名进行server_name域名匹配,然后选择返回不同的 虚拟主机内容 4.还有剩余的功能配置
404页面 在虚拟主机server{}标签中定义error_log参数 error_page 404 /404.html; 访问日志功能, 放在http{}标签中, 代表全局作用域, 对所有虚拟主机生效,写在单独的虚拟主机中, 就是局部变量 log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; 5.反向代理功能参数
在虚拟主机中,找到location{}标签,然后写入 proxy_pass 你想代理的服务器ip地址; Nginx实现负载均衡, 动静分离的效果
1.环境准备
192.168.43.157 资源服务器 提供dnf页面 192.168.43.6 资源服务器 (讲道理,应该是192.168.xx.xx一样的代码配置,一样的页面) 192.168.43.186 充当代理服务器,以及负载均衡的作用 2.分别配置三台机器
192.168.43.157 资源服务器, 提供dnf页面 192.168.43.6 资源服务器,提供小猫咪页面 192.168.43.187 负载均衡的配置 3.nginx.conf修改为如下配置
1.添加负载均衡池, 写入web服务器地址: upstream mydjango { #负载均衡的方式默认是轮询, 1s一次 server 192.168.43.157; server 192.168.43.6; } ----------------------------------- upstream mydjango { #带weight加权 server 192.168.43.157 weight=2; server 192.168.43.6 weight=7; } ----------------------------------- upstream mydjango { #按ip_hash分配 ip_hash; server 192.168.43.157; server 192.168.43.6; } 4.负载均衡的配置方式
location / { proxy_pass http://mydjango; } 5.动静分离的配置
1.配置动态请求的服务器
192.168.43.6 充当静态服务器,返回小猫咪的页面,以及一些图片资源
需要安装nginx即可
#nginx.conf 配置如下 #当请求来自于192.168.43.6/时,就进入如下路径匹配,返回日剧页面 location / { root html; index index.html index.htm; } #当请求时192.168.43..140/xx.jpg这样的媒体资源,就进入如下location返回/opt/nginx1223/html/images location ~* .*.(png|jpg|gif|jpeg)$ { root /opt/nginx1223/html/images; } 2.配置静态请求的服务器
192.168.43.157 运行django页面
1.先后台运行django页面 python3 manage.py runserver 0.0.0.0:8000 & 2.修改nginx配置, 可以转发, 动静的请求 upstream mydjango { server 192.168.43.157:8000; } upstream mystatic { server 192.168.43.6; } server { listen 80; server_name 192.168.43.157; #当外部请求,是192.168.43.157时就进入如下location,返回django页面反向代理 #charset koi8-r; #access_log logs/host.access.log main; #access_log "pipe:rollback logs/host.access_log interval=1d baknum=7 maxsize=2G" main; location / { proxy_pass http://mydjango; } #当外部请求时, 192.168.43.157:80/xx/jpg #就转发给那台静态资源服务器去处理 location ~ .*.(png|jpg|gif|jpeg)$ { proxy_pass http://mystatic; } 3.在负载均衡器上,配置请求转发
192.168.43.187 配置负载均衡动静分离的配置
1.定义一个upstream地址池,进行请求分发 upsrteam地址池,进行请求分发 upstream myserver { server 192.168.43.157; server 192.168.43.6; } 2.通过location进行请求分发的工作 location / { proxy_pass http://myserver; } 负载均衡的规则
### 调度算法 概述 * 轮询 |按时间顺序逐一分配到不同的后端服务器(默认) * weight |加权轮询, weight值越大,分配到的访问几率越高 * ip_hash |每个请求按访问的hash结果分配,这样来自同一ip的固定访问一个后端服务器 * least_conn |最少链接数,那个机器链接数少就分发 ----------------------------------------------------------- 注意轮询,是假设1s内有两个人请求, 那么则均衡配分. 前两种方式最常用 ob_crm项目部署
django自带了socket服务端吗?wsgiref这个是python自带的socket模块,django默认用的是wsgiref的单机socket模块
Python manage.py runserver 这是调试命令,测试django是否有问题的
最终上线是uwsgi + django的方式
为什么要用nginx结合uwsgi
1.nginx支持静态文件处理性能更好
2.nginx的埃军和特性,让网站并发更高
3.并且反向代理特性,用户访问80,即可访问到8000的应用
4.uwsgi支持多进程的方式,启动django,性能更高
5.nginx转发请求给uwsgi,应该用uwsgi_pass,实现了uwsgi协议的请求转发
如果出现错误: pytho app application not found
就是你的uwsgi没找到uwsgi.py这个文件对象 application = get_wsgi_application()
wsgiref: python自带的web服务器 gunicorn: 用户linux的python wsgi Http服务器,常用于各种django,flask结合部署服务器 mode_wsgi: 实现了apache与wsgi应用程序的结合 uWsig: c语言开发,快速,自我修复,开发人员友好的WSGI服务器,用于python web应用程序的专业部署和开发 配置步骤
## 1.nginx+uwsgi+虚拟环境+mysq+supervisor 环境准备, 一台linux(192.168.43.157) ### 第一步,先准备后端代码 ob_crm ### 第二部:安装py2解释器,以及虚拟环境工具virtualenvwrapper ### 第三部,学习uwsgi命令, 通过uwsgi启动ob_crm ## 1.激活虚拟环境,在虚拟环境下安装所需的模块 安装如下内容即可 Django==1.11.20 django-multiselectfield==0.1.12 PyMySQL==1.0.2 pytz==2022.7.1 ## 2.安装这个文件 [linux] pip3 install -i https://pypi.douban.com/simple -r requirements.txt ## 3.安装uwsgi命令 pip3.6 install uwsgi ## 4.学习uwsgi启动django的命令 uwsgi --http :8000 --module mysite.wsgi --py--autoreload=1 --http 指定http协议 :8000 指定启动端口 ### --module 指定django的wsgi.py的文件地址 指定你的django项目第二层目录名,下面的wsgi.py --py-autoreload=1 开启uwsgi的热加载功能 1代表ture开启的意思 所以咱们用的命令应该是如下: 1.必须进入项目目录 /opt/teaching_plan/ob_crm 2.使用命令启动ob_crm(uwsgi不解析django的静态文件) uwsgi --http :8000 --module ob_crm.wsgi 用ob_crm这个目录去查找wsgi这个脚本文件 3.让你的项目支持热加载 由于uwsgi的启动参数过多,我们会选则配置文件的方式,启动项目
uwsgi.ini 这个文件的名字,可以手动创建的
1.创建uwsgi.ini写入如下参数
# mysite_uwsgi.ini file [uwsgi] # Django-related settings # the base directory (full path) # 填写你项目的绝对路径,第一层 chdir = /opt/teaching_plan/ob_crm/ # Django's wsgi file # 找到django的那个我wsgi.py文件 # 根据上面一条参数,的相对路径来写 module = ob_crm.wsgi # the virtualenv (full path) # 虚拟环境的绝对路径 home = /root/Envs/ob_crm # process-related settings # master 主进程 master = true # maximum numver of worker processes # 根据你的cpu核数来定义 processes = 4 # the socket (use the full path to be safe # 指定你的django启动在什么地址上并且是什么协议 # 如果你用了nginx反向代理, 请用socket参数 socket =0.0.0.0:8000 # 如果未使用nginx反向代理, 想要直接使用django, 用这个参数: # http = 0.0.0.0:8000 # ... with appropriate permissions - may be needed # chmod-socket = 664 # clear environment on exit vacuum =true #开启热加载 py_autoreload = 1 2.通过配置文件启动项目
uwsgi --ini uwsgi.ini 3.收集django的所有静态文件统一管理,丢给nginx解析
1.设置django项目的settings.py文件
STATIC_ROOT = '/opt/s19static' # 收集到任意一个目录里 STATIC_URL='/static/' STATICFILES_DIRS=[ os.path.join(BASE_DIR, 'static'), ] 上述的参数STATIC_ROOT用在哪?
2.执行命令收集文件
#### 通过$ python3 manage.py collectstatic 收集所有你使用的静态文件保存到STATIC_ROOT!
STATIC_ROOT 文件夹 是用来将所有STATICFILES_DIR中所有的文件夹中的文件, 以及app中static的文件都复制过来 # 把这些文件放到一起是为了用nginx等部署的时候更方便 nginx配置来了!!!
1.nginx的反向代理
2.nginx解析静态文件的功能
location / { uwsgi_pass 127.0.0.1:8000; include uwsgi_params; } location /static { #给静态文件目录设置别名,可以让其源目录访问到真实的静态目录 alias /opt/s19static; } 进程管理工具supervisor的使用
supervisor其实就是在帮咱们去执行命令
1.安装supervisor,通过pip直接按照
pip3 install supervisor 2.生成supervisor的配置文件
echo_supervisord_conf > /etc/supervisor.conf
3.修改配置, 写入你管理ob_crm的命令参数
vim /etc/supervisor.conf #直接进入最低行, 写任务 [program:s19_ob_crm] command=/root/Evns/ob_crm/bin/uwsgi --ini /opt/teaching_plan/ob_crm/uwsgi.i ni stopasgroup=true ;默认为flase,进程被杀死时, 是否这个进程组发送stop信号, 包括子进程 killasgroup=true ;默认为false, 向进程发送kill信号,包括子进程 4.通过命令启动supervisor 同时启用ob_crm
supervisorctl #管理命令 supervisord #服务端命令 启动服务端的命令
supervisor -c /etc/supervisor.conf 通过客户端命令管理ob_crm
[root@localhost conf]# supervisorctl -c /etc/supervisor.conf s19_ob_crm FATAL can't find command '/root/Evns/ob_crm/bin/uwsgi' 任务名 状态 [program:s19_ob_crm] command=/opt/python3.6.4/bin/uwsgi --ini /opt/teaching_plan/ob_crm/uwsgi.ini stopasgroup=true killasgroup=true 访问成功如下:
[root@localhost ob_crm]# supervisorctl -c /etc/supervisor.conf s19_ob_crm RUNNING pid 57569, uptime 0:01:37 supervisor> #此结果我足足等了一天了多,不知是什么bug,如果我写虚拟环境的目录,他总是找不到命令,于是我只能写上物理环境中的命令uwsgi来启动.哎哎哎 supervisor命令行操作
1.停止任务
supervisor> stop s19_ob_crm s19_ob_crm: stopped 2.查看任务状态
supervisor> status s19_ob_crm STOPPED Feb 16 10:31 PM 3.启动/停止所有的任务
supervisor> start all #开启所有任务 s19_ob_crm: started --------------------------------------------------------- supervisor> stop all #关闭所有任务 s19_ob_crm: stopped 部署内容回顾
整篇端口设计:
vue(静态文件夹dist) 也就是nginx返回vue页面,端口为80,也是nginx.conf提供的 server{}虚拟主机提供的 | 反向代理端口 8500 ,是通过nginx实现的,nginx.conf中编写一些参数,接口速率限制,爬虫验证,封停ip地址 | django后台地址 9000 1.部署了crm
nginx + uwsgi + django + virtualenv + supervisor + mariadb 项目账密:alex;alex3714 2.部署一个前后端分离项目
vue(js框架)(nginx返回vue页面) + django rest freamwork(提供api接口的框架)(后端) + virtualenv + sqlite + redis(k-y型数据库)(存放课程信息,登录的账号密码) `后端部署过程: 1.准备后端代码-django wget https://files.cnblogs.com/files/pyyu/luffy_boy.zip 2.解压缩代码 unzip luffy_boy.zip 3.修改django的settings.py配置文件(允许所有主机登录) ALLOWED_hosts = ["*"] 4.由于这个路飞代码用的是sqlite,所以不需要配置mysql数据库了 5.创建路飞项目的虚拟环境,运行代码 mkvirtualenv s19luffy_boy 6.解决路飞运行,所需模块依赖 pip3.6 freeze >> requitements.txt #导出模块的命令 #提示 #我已经给你准备好了这个文件的信息 ......略 7.安装uwsgi, 运行路飞的后端,支持多进程的django #命令运行方式 uwsgi --http : 8000 --module luffy_boy.wsgi #配置文件方式如下 vim uwsgi.ini #写入如下内容: [uwsgi] # Django-related settings # the base directory (full path) # 填写你项目的绝对路径,第一层 chdir = /opt/s19luffy/luffy_boy # Django's wsgi file # 找到django的那个我wsgi.py文件 # 根据上面一条参数,的相对路径来写 module = luff_boy.wsgi # the virtualenv (full path) # 虚拟环境的绝对路径 home = /root/Envs/s19luffy_boy # process-related settings # master 主进程 master = true # maximum numver of worker processes # 根据你的cpu核数来定义 processes = 4 # the socket (use the full path to be safe # 指定你的django启动在什么地址上并且是什么协议 # 如果你用了nginx反向代理, 请用socket参数 socket =0.0.0.0:9000 # 如果未使用nginx反向代理, 想要直接使用django, 用这个参数: # http = 0.0.0.0:8000 # ... with appropriate permissions - may be needed # chmod-socket = 664 # clear environment on exit vacuum =true #开启热加载 py_autoreload = 1 8.启动路飞后端 uwsgi --ini uwsgi.ini `前端部署过程: 1.准备前端代码-vue wget https://files.cnblogs.com/files/pyyu/07-luffy_project_01.zip 2.解压缩代码包 unzip 01-luffy_project_01.zip 未更改过的vue代码,长这样 build config index.html package.json(vue包信息) package-locak.json README.md src static` 3.下载nodejs解释器,用于编译vue代码 4.解压缩node的源代码包 node如同python3.6是一个解释器 npm如同pip是一个包管理工具 5.配置node的环境变量PATH 写入path中:/opt/s19luffy/node-v8.6.0-linux-x64/bin 修改vue向后台发送地址的接口, 必须修改... 批量替换接口地址 sed -i "s/127.0.0.1:8000192.168.43.157:8500/g" api.js sed #处理文本信息的命令 -i 将替换结果插入到文本中 s/你想替换的内容/替换之后的内容/global全局替换 6.安装vue模块 npm install 7.模块安装完毕后,进行编译打包,生成dist静态文件夹 8.编译打包vue完成之后,会生成一个dist静态文件夹,里面存放了路飞首页所有内容,交给nginx即可 nginx配置如下:
1.支持vue的页面虚拟主机
location / { root /opt/s19luffy/07-luffy_project_01/dist; index index.html try_files $url $url/ /index.html; #保证首页刷新不出现404 } 2.反向代理的虚拟主机
server { listen 8500; server_name192.168.43.157; location / { uwsgi_pass 192.168.43.157:9000; include uwsgi_params } } 安装启动redis数据库
1.通过yum简洁的安装
yum install redis -y 2.通过yum安装的软件如何启动
systemctl start redis 3.可以查看redis数据库信息
redis-cli 登陆数据库 4.查看购物车信息
key * mariadb就是centos下的mysql,开源免费,用法与mysql是一模一样
1.阿里云的yum仓库和mariadb的yum仓库,其实就是两个不同的url提供了2两不同的yum仓库,软件版本可能较低,不会实时更新.如果你要
如果选择阿里云的yum仓库,安装命令如下
yum install mariadb-server mariadb -y 如果你要选择最新的mariadb软件,请配置官方yum源
安装命令如下
yum install mariaDB-server MariaDB-client 2.安装好mysql之后就可以启动使用了,注意要先初始化数据库
mysql_secure_installation 3.学习mysql的授权命令
允许mysql服务端可以远程连接的命令 grant all privileges on *.* to root@'%' identified by '168168956'; #允许root用户在任意的主机地址都可以登录mysql服务端 flush privileges; #立即刷新权限表 # 参数说明: ALL PRIVILEGES表示赋给远程登录用户的权限,ALL PRIVILEGES表示所有的权限,可以单独或组合赋select,update,insert,delete权限; .:第一个*表示要赋权的数据库名,表示全部数据库了,第二个表示数据库下的表名,同理,*表示全部表,也可以根据需求限制表; sariel表示要赋权的用户; %表示远程登录的IP,如果要限制登录IP的话,这里就添允许登录的IP,比如192.18.1.99等,%表示不限制IP); 000000是用户远程登录的密码。 ———————————————— 版权声明:本文为CSDN博主「gblfy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/weixin_40816738/article/details/124766572 4.客户端远程登录服务端的命令
mysql -uroot -p -h 192.168.43.157 5.mysql的备份与恢复
#备份 mysqldump -u root -p --all-databases > /opt/alldb.sq #恢复 1.mysql -uroot -p < /opt/alldb.sql 2.登录mysql之后,source读取db文件 ----------------------------------------- 高版本导出的数据库和低版本无法兼容会报这个错误: Unknown collation: 'utf8mb4_0900_ai_ci' mysql主从同步的配置
1.环境准备,两台linux,分别安装好mariadb两台数据库
2.先从master主库开始配置
1.先停止数据库服务 systemctl stop mariadb 2.修改mysql配置文件(/etc/my.cnf.d/server.cnf),支持binlog日志 server-id=1 log-bin=s19-bin-log 删除软件时一定要删除干净,直接yum remove无法删除干净会会很麻烦 mariadb启动报错也有可能是配置文件导致,my.cnf 3.重启mysql配置文件,支持binlog日志
server-id=1 log-bin=s19-bin-log 4.重启mysql数据库,让binlog日志文件生效
systemctl restart mariadb 5.创建一个用户,用于主从同步
create user 's19'@'%' identified by '168168956'; s19是用户名 %是允许所有ip登录 168168956是密码 6.给这个账号授予复制的权限
grant replication slave on *.* to 's19'@'%'; 7.导出当前数据库,发送给从库,保证数据一致
mysqldump -uroot -p --all-databases > /opt/mydb.sql 从库配置如下:
1.修改mysql配置文件,加上身份id, vim /etc/my.cnf
[mysqld] server-id=10 read-only=true 2.重启从库的mysql
systemctl restart mariadb 3.从库导入主库的数据,保证起点一致性
4.配置主从同步的关键参数
change master to master_host='192.168.43.157', master_user='s19', #用于同步的数据库用户 master_password='168168956', #密码 master_log_file='s19-bin-log.000001', #指定主库的日志文件 master_log_pos=564; 5.开启主从同步
start slave 6.查看主从同步的状态
show slave statusG 7.去主库写入数据,查看从库的实时数据同步
redis(NoSQL)(not only sql)
mysql关系型数据库,文件型数据库
redis数据库学习(nosql 不仅仅是sql),内存型数据库
1.redis的安装方式, yum安装, 源码编译安装
查看是否用yum安装了redis rpm -qi redis 2.选择源码编译安装redis 需要先卸载redis(yum安装的)
yum remove redis -y 3.下载redis的源代码, 编译安装, 指定安装路径
wget http://download.redis.io/releases/redis-4.0.10.tar.gz 4.解压缩源代码,编译安装
tar -zxvf redis-4.0.1.tar.gz 进入源代码目录,开始编译安装 这里不需要configure,直接make&&make install 直接装在了当前的redis源码目录下,配置文件,启动命令,都在当前目录下了 /opt/redis-4.10.0/redis.conf 因为源代码包以及有Makefile文件了 redis的可执行命令如下,解释:
./redis-benchmark //用于进行redis性能测试的工具 ./redis-check-dump //用于修复出问题的dump.rdb文件 ./redis-cli //redis的客户端 ./redis-server //redis的服务端 ./redis-check-aof //用于修复出问题的AOF文件 ./redis-sentinel //用于集群管理 5.如何安全的启动redis
1.更改默认的redis启动端口
2.给redis启动添加密码
3.开启redis的安全机制(必须用密码验证,才能登陆数据库)
修改redis.conf配置文件内容
bind 0.0.0.0 #redis绑定的地址 protected-mode yes #redis安全模式 port 6379 #redis的端口 daemonize yes #后台运行redis requirepass 168168956 #redis的密码 6.指定redis配置文件启动数据库
redis-server redis.conf 7.指定端口和主机登录
redis-cli -p 6379 -h 192.168.43.157 登录之后,通过auth指令验证码 auth 168168956 #在登录命令中添加密码 redis-cli -p 6379 -h 192.168.43.157 -a 168168956 8.远程python连接python服务端
import redis conn = redis.Redis(host='192.168.43.157', port=6379, password='168168956') conn.set('name', 'zzy') >>>True conn.get('name') >>>b'zzy' 9.redis的数据库类型使用
redis是一种高级的key:value存储系统, 其中value支持数据类型: 字符串(strings): set key value # 设置name为key,值是apple set name apple #设置name的值 get name #获取name的值 append name "zzy"#追加string mset name1 zzy name 2 wxy name3 hhx #设置多个键值对 mget name1 name2 name3#获取多个键值对 del name#删除key incr #递增+1 decr #递增-1 散列(hashes): 字典key-value: hset #设置为散列值 hget # 获取散列值 hmset #设置多对散列值 hmget #获取多对散列值 hsetnx #如果散列已经存在,则不设置(防止覆盖key) hkeys #返回所有keys hvals #返回所有values hlen #返回散列包含的域(field)的数量 hdel #删除散列指定的域(field) hexists #判断是否存在 列表(lists): lpush list 1 2 3 4 5 #从列表左边插 rpush list 5 4 3 2 1 #从列表右边插 lrange list 0 -1 #获取一定长度的元素(start end) ltrim list 0 2 #截取一定长度列表(0,1,2) lpop #删除最左边一个元素 rpop #删除最右边一个元素 lpushx/rpushx #key存在则添加值,不存在不处理 集合(sets): 无序去重的数据类型 sadd/srem #添加/删除元素 sadd set 1 2 3 4 srem set 1 2 3 4 sismember set #判断是否为set的一个元素 smembers set #返回集合所有成员 sdiff set set2 #返回一个集合和其他集合的差异 sinter set set2 #返回几个集合的交集 sunion set set2 #返回几个集合的交集 有序集合(sorted sets): #都是以z开头的命令 zadd mid_test 70 "alex" #添加有序集合 zrange score 0 -1 #升序 zrevrange score 0 -1 #逆序 zrank score zzy #查看有序集合里任意成员排名 keys * # 查看机器所有的key type key # 显示key的类型 expire key # 给key加上过期时间 ttl key # 查看key的剩余过期时间 -1永不过期 -2代表key不存在 persist # 取消key的过期时间 exists key # 检测key是否存在 1存在 0不存在 del key # 删除key dbsize # 计算key的数量 演示板
#为结果 127.0.0.1:6379> lpush paidui jay she yanzi zzy wuyuetian sudalv hebe #(integer) 7 127.0.0.1:6379> lrange paidui 0 -1 #1) "hebe" #2) "sudalv" #3) "wuyuetian" #4) "zzy" #5) "yanzi" #6) "she" #7) "jay" lpush总是last push的值在最上面也是最前面 rpush总是first push的值在最上面也是最前面 Pub/Sub(发布/订阅)-redis发布订阅
psubscribe publish pubsub punsubscribe subscribe unsubscribe redis的数据持久化
背景: 进程被杀死,服务器断电,内存中数据被杀死数据都会释放,数据丢失,如果redis没有持久化,数据丢失 1.redis支持两种数据持久化
AOF(append-only log file): 记录服务器执行的所有变更操作命令(例如 set del等),并在服务器启动时,通过重新执行这些命令还原数据集 优点: 最大程度保证数据不丢 确定: 日志记录非常大 AOF持久化模式: 1.在配置文件中定义功能参数即可使用aof: daemonize yes port 6379 logfile /data/6379/redis.log dir /data/6379 appendonly yes appendfsync everysec 2.指定aof配置文件启动: redis-server s19-aof.conf 3.启动redis服务端,查看aof日志变动,并且aof数据持久化 RDB: 定期自动或手动执行把redis内存中的数据保存在磁盘上的一个二进制文件中,redis可以通过这个文件还原当时数据库的状态.类似于快照 1.基于内存快照的持久化 持久化数据是个压缩的二进制文件 通过save指令可以手动出发持久化 也可通过配置时间出发持久化 redis.conf: port 6379 daemonize yes logfile /data/6379/redis.log dir /data/6379 #数据存放地址 dbfilename dbmp.rdb bind 0.0.0.0 save 900 1 save 300 10 save 60 10000 创建数据文件夹: mkdir -p /data/6379 3.指定支持持久化的redis配置文件启动: redis_server s19-rdb.conf 4.测试写入redis数据: set name haha save #触发持久化 此时就会生成一个dump.rdb数据文件在/data/6379目录 5.此时就算重启 数据也不会丢失: 注意必须指定配置文件启动 rdb有缺点,可能会造成数据丢失,但是持久化速度最快 问答
'reids持久化方式有哪些?有什么区别? rdb: 基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能 aof: 一追加方式记录redis操作日志文件.可以最大程度保证redis数据安全类似于mysql的binlog 'redis不重启,切换RDB备份到AOF备份' 确保redis版本在2.2以上,通过config set 命令,达到不重启redis服务,从rdb持久化切换到AOF 1.实验准备: rdb的redis数据库写入数据 2.在登陆了rdb的数据库当中进行切换aof命令如下: 3.配置aof的方式如下,通过config set命令设置aof的功能: 127.0.0.1:6379> config set appendonly yes OK 127.0.0.1:6379> config set save "" OK 4.还得修改配置文件,以后再次开启服务永远都是aof: vim s19-rdb.conf ''' appendonly yes appendfsync everysec ''' redis的主从同步功能
1.redis支持多实例的功能,通过配置文件生效,多实例的概念
写多个配置文件,指定文件启动,端口区分数据库,就是多实例了.
redis-6379.conf 主库
port 6379 daemonize yes pidfile /data/6379/redis.pid loglevel notice logfile "/data/6379/redis.log" dbfilename dump.rdb dir /data/6379 protected-mode no redis-6380.conf 从库1
port 6380 daemonize yes pidfile /data/6380/redis.pid loglevel notice logfile "/data/6380/redis.log" dbfilename dump.rdb dir /data/6380 protected-mode no slaveof 0.0.0.0:6379 redis-6381.conf 从库2
port 6381 daemonize yes pidfile /data/6381/redis.pid loglevel notice logfile "/data/6381/redis.log" dbfilename dump.rdb dir /data/6381 protected-mode no slaveof 0.0.0.0:6379 创建数据文件夹:
mkdir -p /data/{6379,6381,6381} 分别启动三个redis数据库实例,默认已经是主从关系了
redis-server redis-6379.conf redis-server redis-6380.conf redis-server redis-6381.conf 检查redis的主从关系
redis-cli -p 6379 info repliction redis-cli -p 6380 info repliction redis-cli -p 6381 info repliction redis的主从复制故障修复
现在是1主2从的状态,假设6381挂掉了有没有影响? 1.手动杀死主库: kill调 2.选择一个从库为新的主库,例如6380是主,6381是从: 登录6380数据库,输入: slaveof no one 3.去登陆6381从库,s: slaveof no one redis高可用之哨兵功能
Redis-Sentinel: 当用redis作master-slave的高可用时,如果master本身宕机,redis本身或客户端都没有实现主从切换的功能 而redis-sentinel就是一个独立运行的进程,用于监控多个mster-slave集群, 自动发现master宕机,进行自动切换slave > master sentinel主要功能如下: 不时的监控redis是否良好运行,如果节点不可达就会对节点进行下线表示 如果被标识的是主节点,sentinel就会和其他的sentinel节点"协商", 如果其他节点也为主节点不可达, 就会选举一个sentinel节点来完成自动故障转义. 在master-slave进行切换回, master_redis.conf, slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置, sentinel.conf的监控目标会随之调换 ---------------------------------------------------- sentinel实际上就是保安(也可以有多个)来检测你的redis是否挂调 1.配置哨兵sentinel功能
#环境准备 三个redis实例,准备一主两从的架构 redis-6379.conf: ''' port 6379 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/opt/data/6379" #要先建立数据文件哦 ''' -------------------------------------------------- redis-6380.conf ''' port 6380 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/opt/data/6380" slaveof 0.0.0.0 6379 ''' -------------------------------------------------- redis-6381.conf ''' port 6381 daemonize yes logfile "6381.log" dbfilename "dump-6381.rdb" dir "/opt/data/6381" slaveof 0.0.0.0 6379 ''' -------------------------------------------------- 分别启动三个redis数据库 检查三个redis身份信息 redis-cli -p 6379 info replication ... ... --------------------------------------------------- 三个redis-sentinel配置文件,运行三个哨兵进程 redis-sentinel-26379.conf 配置如下,其他节点仅仅是端口的不同 ''' port 26379 dir /opt/data/26379 logfile "26379.log" sentinel monitor s19msredis 0.0.0.0 6379 1 sentinel down-after-millisecondas s19msredis 30000 sentinel parallel-syncs s19msredis 1 sentinel failover-timeout s19msredis 180000 daemonize yes #后台运行 ''' ---------------------------------------------------- 分别启动三个哨兵 redis-sentinel redis-sentinel-26379.conf redis-sentinel redis-sentinel-26380.conf redis-sentinel redis-sentinel-26381.conf ---------------------------------------------------- '此时验证redis redis-cli -p 26379 info sentinel#查看哨兵是否成功 '出现如下信息则正确: master0:name=s19msredis,status=ok,address=0.0.0.0:6379,slaves=2,sentinels=3 查看redis主库,查看是否会自动的主从故障切换
redis-cluster集群搭建
1.环境准备6个redis节点配置 redis-7000.conf redis-7001.conf redis-7002.conf redis-7003.conf redis-7004.conf redis-7005.conf #其他节点仅仅是端口的不同 ''' port 7000 daemonize yes dir "/opt/redis/data" logfile "7000.log" dbfilename "dump-7000.rdb" cluster-enabled yes cluster-config-file nodes-7000.conf cluster-require-full-coverage no ''' ---------------------------------------------------------- 分别启动6个节点 redis-server redis-7000.conf ...... 此时redis的集群还未分配槽位slots,我们需要下载ruby的脚本,创建这个16384个槽位分配 安装ruby
1.下载ruby的源码包 wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz 2.解压缩源码包目录 tar -zxvf ruby-2.3.1.tar.gz 3.进入ruby源码包目录 ./configure --prefix="/opt/ruby" make && make install 4.配置ruby的环境变量 PATH="" 5.读取PATH环境变量 source /etc/profile 6.下载ruby的包管理工具gem #ruby安装操作reedis的包模块 gem install -l redis-3.3.0.gem 7.一句命令分配redis集群的槽位(*) --replicas 1这个意思是每一个主库,只有一个从库 这个redis-trib.rb命令, 默认不会添加环境变量,直接用绝对路径去创建, find /opt -name redis-trib.rb #查看这个脚本的绝对路径 /opt/redis-4.0.10/src/redis-trib.rb create --replicas 1 0.0.0.0:7000 0.0.0.0:7001 0.0.0.0:7002 0.0.0.0:7003 0.0.0.0:7004 0.0.0.0:7005 8.此时槽位以及分配好了,此时可以写入集群数据了 登录某一个节点,写入数据,查看结果 redis-cli -p 7000 -c #以集群方式运行 tips:如若再次启动集群需清理 /opt/redis/data/目录下的缓存文件 Docker
linux的容器技术
*使用go语言编写的软件 *安装简单 性能优越 *将应用程序打包在一个容器内,打包在一个文件里,运行这个文件就会生成一个虚拟容器 应用场景
web应用程序的自动化和打包发布: 自动化测试和持续集成,发布: 在服务型环境中部署和调整数据库或其它应用: dev 开发
ops 运维
互联网公司的技术栈
老企业(贵): java + jquery + oracle(甲骨文数据库) + redhat(红帽os) + svn(代码版本控制) + mencached(缓存数据库) + apache 互联网企业(省钱)(开源免费软件): python/... + nodejs + vue + centos7 + git + redis + nginx + mysql + rabbitmg +docker vmware虚拟化技术
个人学习版本: vmware workstaion(性能较低,只能运行10几个虚拟机) 企业版本虚拟化: vmware svphere(运行esxi虚拟化服务器) 256GB的物理服务器可以虚拟化出100多个linux 缺点: 虚拟机的局限性,在于每一台都是完整的操作系统,要分配系统资源. docker vs 传统虚拟机
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为MB | 一般为GB |
| 性能 | 接近原生 | 弱 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
解决环境部署问题的办法:
# 1.虚拟化模板克隆 ## docker的三大生命周期(*) 1.容器 2.镜像 3.仓库 基于docker镜像(操作系统镜像) 运行处 容器实例(操作系统+应用 ) ##dvd系统镜像.iso ## docker镜像如同类的关系,基于镜像运行处容器(类的实例化) ```python class Student(): def __init__(self): print('安装python3') print("安装python模块依赖") print('安装虚拟环境......') print('休息一下') s1=Student() s2=Student() s3=Student() s4=Student() # docker镜像 可以在dockerhub下载,也可以通过dockerfile构建镜像 # docker容器 基于docker镜像,可以运行出的实例 # docker仓库 存储docker镜像的地方,就是一个仓库,公网的仓库是dockerhub,还有私人的仓库 centos7安装docker
1.yum安装,阿里云,腾讯云,清华源,最正确的官方yum仓库(版本更新,下载很慢) yum install docker -y 2.启动docker systemctl start docker systemctl status mysql #验证docker是否启动 docker --version 3.docker的命令学习,对镜像,容器的管理命令
1.获取镜像
2.运行镜像
3.对容器进行管理
配置docker加速器,加速镜像下载查找
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io #这里还得修改docer的命令 /etc/docker/daemon.json 编辑如下: ''' { "registry-mirrors": [ "https://bjtzu1jb.mirror.aliyuncs.com", "http://f1361db2.m.daocloud.io", "https://hub-mirror.c.163.com", "https://docker.mirrors.ustc.edu.cn", "https://reg-mirror.qiniu.com", "https://dockerhub.azk8s.cn", "https://registry.docker-cn.com" ] } ''' ------------------------------------------------------------ 或者: ''' { "registry-mirrors" : [ "https://8xpk5wnt.mirror.aliyuncs.com" ] } ''' 镜像: 增删查 docker search 镜像名 #其实是去docker hub搜索镜像 docker search hello-world #搜索docker镜像 docker pull hello-world #下载docker镜像 docker image ls #查看当前机器的docker镜像 docker images #同上 ------------------------------------------------- docker rm 镜像名/镜像id #删除容器记录(只能删除挂掉的容器记录) docker rm `docker ps -aq` #一次性删除所有docker容器记录,只能删除挂掉的记录 [利用反引号运行(这条命令的结果)作为参数] docker rmi -f 镜像id #强制删除镜像force -------------------------------------------------- docker run -d centos /bin/sh -c "while true;do echo hello centos; sleep 1;done" # 在后台运行docker容器 -------------------------------------------------------- docker logs 容器id #查看容器内日志信息 docker logs -f 容器id # 实时查看刷新容器日志信息 -------------------------------------------------------- docker exec -it 容器id /bin/bash #用exec指令,进入到容器系统内 docker exec -it 容器id /bin/bash #进入一个人已经在运行的docker容器中 -------------------------------------------------------- -i 交互式shell的命令方式 -t 开启一个终端去运行 docker run -it ubuntu /bin/bash 容器: 增删改查 docker run 镜像名/镜像id #运行docker镜像,生成容器记录 docker run 不存在的镜像名 #会先docker pull下载,然后自动运行 docker container ls #列出当前机器的所有容器(正在运行的容器,正在运行的dockee进程) docker ps #查看docker进程,docker容器记录的 docker ps -a #查看dockers所有的进程,以及挂掉的进程 '运行一次镜像,就会生成一个容器记录 'docker容器必须有正在运行的进程, 否则容器就会挂掉 运行一个centos的docker容器
1.下载docker镜像,且是centos的镜像 docker pull centos 2.运行centos镜像,生成容器 docker run centos #这个容器没有任何后台的进程,所以直接挂掉 --------------------------------------------------------- '情景提示,当遇到如下报错情况,解决方案如下: ''' [root@localhost docker]# docker run centos WARNING: IPv4 forwarding is disabled. Networking will not work. [root@localhost docker]# systemctl restart docker [root@localhost docker]# docker run centos [root@localhost docker]# ''' ---------------------------------------------------------- 3.运行一个后台有进程的容器 docker run -d centos /bin/sh -c "while true;do echo hello centos; sleep 1;done" -d damonize 后台运行的意思 centos 指定一个镜像去运行 /bin/sh 指定centos的解释器 -c 指定一段shell语法 while循环,然后打印hello centos;每一秒睡眠一次; do和done是闭合关系 ------------------------------------------------------------- 提交自定义的docker镜像
1.准备一个centos的docker容器,默认没有vim的 docker run -it centos /bin/bash/ #c创建启动一个docker容器,且是centos系统的 2.退出docker容器空间,然后提交这个容器,生成一个新的镜像文件 docker commit 你想要提交的容器id 你想要创建的镜像名 3.查看你创建的镜像 docker images 4.导出你提交的镜像,成为一个压缩文件 docker save zzy/s19-centos-vim > /opt/myimage.tar.gz 5.把这个压缩文件,传递给其他人,其他人导入这个镜像文件,然后运行,默认就携带了vim编译器 docker load < /opt/myimage.tar.gz 运行一个web内容的docker容器
docker run -d -P training/webapp python app.py -d 后台运行 -p 小写字母参数意思是指定映射端口: -p 8001:8000 -P 大写字母P参数意思是随机映射一个端口 用户 xxx.xxx.xxx.xx:8000 --> 我的服务器 xxx.xxx.xxx.xx:8000 如果是直接运行在物理机的8000端口,就直接响应 用户 xxx.xxx.xxx.xx:8000 --> 我的服务器 xxx.xxx.xxx.xx:8000 访问的不再是物理机上的进程而是容器内的进程 --> 容器内的一个进程和端口 dokcerfile的学习
dockerfile的作用是创建一个docker镜像
1.docker镜像仓库下载(不可控制docker镜像内容) 2.把其他人发来的docker镜像进行导入(不可控,镜像内容也是其他人定制的) 3.dockerfile通过脚本自定义docker镜像(把部署过程写入到一个脚本当中,学习dockerfile的指令,去部署即可) #每一个app运行,必须得有一个系统作为载体 from scratch #制作base image 基础镜像,尽量使用官方的image作为base image from centos #使用base image from ubuntu:14.04 #带有tag的base image ------------------------------------------------------------- label version="1.0" #容器元信息,帮助信息,Metadata,类似于代码注释 LABEL maintainer="yu_uuu@163.com" # 告诉别人这个dockerfile是谁写的 ------------------------------------------------------------- #万能指令,去执行你输入的命令 #对于复杂的RUN命令,避免无用的分层,多条命令用反斜杠换行,合成一条命令! RUN yum update && yum install -y vim Python-dev #反斜杠换行 RUN /bin/bash -c "source $HOME/.bashrc;echo $HOME" # 可以用run指令,告诉docker,去自动的装哪些程序依赖 WORKDIR /root #相当于linux的cd命令,改变目录,尽量使用绝对路径!!!不要用RUN cd WORKDIR /test #如果没有就自动创建 WORKDIR demo #在进入demo文件夹 RUN pwd # 打印结果应该是/tets/demo ------------------------------------------------------------- ADD and COPY ADD hello / #把本地文件添加到镜像中,把本地的hello可执行文件拷贝到镜像的/目录 ADD指令用于把物理机上的文件添加到容器空间内,并且还有解压缩的 作用 ADD /opt/zzy.jpg /opt/ #把物理机的linux /opt下的一张jpg图片,传输到容器空间内的/opt目录下 | | | | ADD 与 COPY -优先使用copy -add除了copy功能还有解压功能 copy指令的作用是把物理机的文件拷贝到容器控件内不解压 添加远程文件/目录使用curl或wget | | | ENV #环境变量,尽可能使用ENV增加可维护性 ENV MYSQL_VERSION 5.6 #设置一个mysql常量 RUN yum install -y mysql-server="${MYSQL_VERSION}"#变量 ENV 指令用于定义变量 dockerfile的实际应用,创建一个flask镜像,基于这个flask镜像,运行web容器
1.准备flask的代码 myfalsk.py 内容如下,基于py2运行代码: ''' ''' 2.准备dockerfile的编写 ''' FROM centos #yicentos为基础操作系统 COPY CentOS-Base.repo /etc/yum.repos.d/ #修改容器内的yum元,把本地的repo文件,传输到容器内的yum仓库目录下 COPY epel.repo /etc/yum.repos.d/ #同上,用于安装yum源 COPY myflask.py /opt/ #把本地的flask代码文件,拷贝到容器空间内 RUN yum clean all #让容器执行这个命令,清空原本的yum缓存 RUN yum install python-setuptools -y #centos默认没人easy_install RUN easy_install flask #容器自动的执行 安装flask模块的命令 WORKDIR /opt #切换容器内的工作目录 EXPOSE 8080 #开发容器内的8080端口,提供给宿主机去映射 CMD ["python", "s19-flask"] #容器去执行这一段指令 ''' Dockerfile内容: FROM centos COPY CentOS-Base.repo /etc/yum.repos.d/ COPY epel.repo /etc/yum.repos.d/ COPY myflask.py /opt/ RUN yum clean all RUN yum install python-setuptools -y RUN easy_install flask WORKDIR /opt EXPOSE 8080 CMD ["python", "s19-flask"] ------------------------------------------------------------- Dockerfile内容(New): FROM centos:7.8.2003 RUN curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo; RUN curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/epel-7.repo; RUN yum makecache fast; RUN yum install python-devel python-pip -y RUN pip install flask COPY app.py /opt WORKDIR /opt EXPOSE 8080 CMD ["python", "app.py"] ------------------------------------------------------------- 编译遇到问题或者无法解决的bug poweroff关闭虚拟机 然后再次手动开启之后ssh连接 2023-02-25 19:30 docker的web应用:
docker run -d -P training/webapp python app.py 运行一个doucker容器进程 #后台运行一个python web代码且进行端口映射 查看容器进程, 结果是宿主机的32768端口,映射到了5000端口 [root@localhost ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 66be7f71911b training/webapp "python app.py" 2 hours ago Up 2 hours 0.0.0.0:32768->5000/tcp distracted_heyrovsky 1.创建,且运行一个web容器 docker run -d -P training/webapp python app.py 2.查看容器的端口映射关系 docker port 容器id 3.访问宿主机的32768,即可访问到容器的5000应用 4.启停这个容器应用 docker start 容器id docker stop 容器id 5.指定端口映射关系 docker run -d -p 8888:5000 training/webapp python app.py -p宿主机端口 6.修改镜像名 docker tag 镜像id 要改的名字 7.临时不错,运行docker容器时,添加上名字 docker run --name 容器名 运行镜像名 8.基于自定义flask镜像, 生成容器实例 dockerfile指令
from 指定基础镜像 maintainer 指定维护信息, 可以没有 run 你想让他干啥(在命令前面加上run即可) add copy文件并自动解压 workdir 设置当前工作目录类似于cd命令 volumn 设置卷, 挂在主机目录 expose 开放端口 cmd 指定容器启动后要干的事情 dockerfile其他指令
copy 复制文件
env 环境变量
entrypoint 容器启动后执行的命令
docker build . #构建镜像文件 docker build --no-cache -t "镜像名"
修改容器内web程序页面
1.重新编码修复 注意flask的host-port与外部绑定的端口一定要一样
2.进入容器中修复 docker exec -it 容器id/容器名 /bin/bash 修改容器内程序 退出容器重启容器才可以生效. exit docker restart 容器id/name 创建nginx镜像
1.建立一个目录存放Dockerfile文件 mkdir /learn_docker 2.进入目录并创建Dockerfile文件 cat <<EOF > /learn_docker/Dockerfile FROM nginx RUN nginx RUN echo '<meta charset=utf8> zzy happle nginx' > /usr/share/nginx/html/index.html EOF docker的私有仓库
我的dockerhub登陆邮箱/用户名/密码
2744726697@qq.com
zzym
ZZy168168956
1.下载docker官方提供的私有仓库镜像(提供了私有仓库的功能) docker run -d -p 5000:5000 -v /opt/data/registry:/var/lib/registry registry # -v的作用是, 数据卷挂在,文件夹映射的关系 # 类似于端口映射的关系, 打开了两个操作系统之间的管道 http://192.168.43.157:5000/v2/_catalog 存放数据的API(就是一段提供数据的url)地址 ------------------------------------------------------- docker pull registry #下载私有仓库镜像 2.修改docker的配置文件,支持非https的方式上传镜像 vim /etc/docker/daemon.json 3.还得修改docker的启动配置文件 修改如下文件 /lib/systemd/system/docker.service vim /lib/systemd/system/docker.service # 编辑这个文件, 添加如下参数 [Service] EnvironmentFile=-/run/containers/registries.conf EnvironmentFile=-/etc/docker/daemon.json 4.重新加载docker服务 systemctl daemon-reload 5.重启docker服务 systemctl restart docker 6.由于重启了docker,所有的容器都挂掉了 docker run --privileged=true -d -p 5000:5000 -v /opt/data/registry:/var/lib/registry registry 7.推送本地镜像文件到私有仓库中 docker push 192.168.43.157:5000/s19-registry 8.如何区分私有共有 私有仓库前面是ip和端口 共有仓库前面是dockerhub官网的用户名 ------------------------------------------------------- >运行结果是一串id代表无误 >如果遇到报错如下 >dial tcp 192.168.43.157:5000: connect: connection refused >代表没有运行也就是没开放端口 >正确运行网页显示结果如下 >{"repositories":["s19-registry"]} >修改参数可以只修改daemon.json -------------------------------------------------------
docker的公有仓库
1.登录dockerhub,在linux命令行中输入:
docker login2.输入你正确的账号密码
3.可以推送到你本地的镜像文件,到dockerhub了
注意要保证的image的tag是账户名, 如果镜像名字不对,需要改一下tag
docker tag zzy/my_flask_web zzym/flask_web 语法是: docker tag 仓库名 zzy/仓库名
内容回顾
docker一个容器技术
docker的生命周期,三大概念
容器,镜像,仓库
容器是镜像的实例化
仓库有dockerhub共有仓库, docker registory私有仓库,存放镜像的地方
常用doker管理镜像的命令
doker rmi 镜像id
docker rm 容器id
docker ps -a 显示出所有运行过的容器记录
docker ps 查看正在运行的容器进程
docker images 查看所有镜像文件
docker container ls 列出所有容器进程
docker pull 镜像名 在线拉取这个镜像文件
docker search 镜像
docker run -d后台运行 -p指定端口映射 -P随机端口映射 -it(交互式开启一个终端) -v 数据卷挂载(宿主机和容器之间的映射) 镜像名
docker exec -it 正在运行的容器id 交互式命令操作,进入容器空间
docker logs -f 实时查看容器内日志
docker save 导出镜像
docker load 导入镜像
docker commit 提交本地容器记录,保存为一个新的镜像
docker stop 停止容器
docker start 启动容器
docker tag 现有名 带标签的镜像名
docker build . 找到当前目录的Dockerfile 进行构建生成新的镜像
systemctl start docker 启动docker
docker push 推送本地镜像到共有/私有仓库, 如何区分往哪推, 通过你镜像名来区分
docker login 登录dockerhub账户
End-Less
消息队列
实现了消息队列功能的软件rabbitmq,在linux如何安装呢
rabbitmq很吃资源, 需要至少2g内存
实操
1.配置好yum源
2.下载rabbitmq服务端,erlang编程语言
yum install erlang rabbitmq-server -y启动命令:
systemctl start rabbitmq-server3.配置以下rabbitmq的web插件
rabbitmq-plugins enable rabbitmq_management4.创建rabbitmq的登录账号密码
rabbitmqctl add_user zzy 1681689565.设置用户为管理员权限
rabbitmqctl set_user_tags zzy administrator6.对休息队列进行授权,可以读写
rabbitmqctl set_permissions -p "/" zzy ".*" ".*" ".*"7.重启rabbitmq,让配置生效
service rabbitmq-server restart #centos6 systemctl rabbitmq-server restart #centos78.下载python操作rabbitmq的模块
pip3 install pika #注意最新的模块, 参数传入方式变了9.实现生产消费者模型的代码
no_ack, 不确认回复的代码机制如下:
生产者.py
import pika #创建配置.使用rabbitqm用户名密码登录 #去邮局去邮局,必须有身份验证 credentials = pika.PlainCredentials('zzy','168168956') #新建连接,这里localhost可以更换为服务器ip #找到这个邮局,等于连接上服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.43.157',credentials=credentials)) #创建频道 #建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接 channel=connection.channel() #声明一个队列,用于接收消息队列名字叫做'水浒传' channel.queue_declare(queue='水浒传') #注意在rabbitmq中,消息想要发生给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=""),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据 channel.basic_publish( exchange='', routing_key='水浒传', body='武松一拳打死了两只小老虎') print("以及发送了消息") connection.close()消费者.py (可以运行多个消费者)
import pika #建立与rabbitmq的连接 credentials = pika.PlainCredentials("zzy", "168168956") connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.43.157',credentials=credentials)) channel = connection.channel() channel.queue_declare(queue="水浒传") def callbak(ch, method, properties, body): #不确认的机制下, 如果消费走了数据, 且代码报错,数据会丢失,正确的应该是确认机制 #int('hehe') print('消费者接收到了任务: %r' % body.decode('utf8')) #有消息来临,立即执行callbak,没有信息则夯住,等待消息 #老百姓开始去邮箱取邮件了,队列名字是水浒传 #no_ack机制, 不确认机制 ,消费走了不需要给服务端确认, 服务器直接标记消息清楚 channel.basic_consume("水浒传",callbak, True) #开始消费,接收消息 channel.start_consuming()no_ack 机制
no_ack=True 不确认机制, 不需要给服务端一个确认回复, 服务端直接标记消息清楚, 有可能造成消息丢失 no_ack=Flase 确认机制, 你消费走了数据, 还得给服务端发一个确认回复, 让给服务端可以正确标记消息清楚,保证消息不丢失一个生产者,多个消费者, 默认是轮询机制
ack机制
生产者.py
import pika #创建配置.使用rabbitqm用户名密码登录 #去邮局去邮局,必须有身份验证 credentials = pika.PlainCredentials('zzy','168168956') #新建连接,这里localhost可以更换为服务器ip #找到这个邮局,等于连接上服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.43.157',credentials=credentials)) #创建频道 #建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接 channel=connection.channel() #声明一个队列,用于接收消息队列名字叫做'水浒传' channel.queue_declare(queue='王者荣耀') #注意在rabbitmq中,消息想要发生给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=""),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据 channel.basic_publish( exchange='', routing_key='王者荣耀', body='敌人还有5秒钟到达战场:') print("以及发送了消息") connection.close()消费者.py(支持ack)
import pika #建立与rabbitmq的连接 credentials = pika.PlainCredentials("zzy", "168168956") connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.43.157',credentials=credentials)) channel = connection.channel() channel.queue_declare(queue="王者荣耀") def callbak(ch, method, properties, body): #int('hehe') print('消费者接收到了消息: %r' % body.decode('utf8')) #有消息来临,立即执行callbak,没有信息则夯住,等待消息 #老百姓开始去邮箱取邮件了,队列名字是水浒传 #no_ack=False 代表确认要给服务端,回复消息 channel.basic_consume("王者荣耀",callbak, False) #开始消费,接收消息 channel.start_consuming()End-less
消息队列的持久化
背景: 默认队列不支持持久化, rabbitmq重启之后, 所有队列消失
配置持久化的队列, 方式如下
1.声明队列时,加上持久化的参数
持久化的生产者.py
import pika #建立和服务端的连接部分 credentials = pika.PlainCredentials('zzy','168168956') connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.43.157',credentials=credentials)) channel=connection.channel() #声明一个队列(创建一个队列) #默认此队列不支持持久化,如果服务器挂掉,数据丢失 #durable=True #开启持久化, 必须新开启一个队列, 原本的队列已经不支持持久化了 ''' 实现rabbitmq持久化条件 delivery_mode=2 使用durable=True声明queue是持久化 ''' channel.queue_declare(queue='LOL', durable=True) channel.basic_publish( exchange='', routing_key='LOL', body='made fack', properties=pika.BasicProperties( delivery_mode=2, #代表消息是持久的 ) ) connection.close()总结一下rabbitmq-server
消息队列支持持久化的队列,和非持久化的队列
以及消息的确认机制 ack和no_ack的区别
cmdb(资产管理收集 )
end_less
Saltstack
运行依赖包:
python zeromq pyzmp pycrypto
msgpack-python yaml jinja2
saltstack学习
1.环境准备, 两台服务器, 一个是master, 一个是minion
master 192.168.43.157 minion 192.168.43.62.在两台机器上, 分别配置hosts文件, 配置本地dns服务器(dnsmasq 小型dns服务器)
因为ip的通信, 不易识别, 其通信较慢, 配置hosts强制的本地域名解析, 通信方便 vim /etc/hosts 分别在两台机器下输入如下内容: ''' 192.168.43.6 minion 192.168.43.157 master ''' 关闭防火墙策略,以及关闭服务 (selinux 内置的linux防火墙)(IP tables是软件防火墙) (硬件防火墙 ) iptables -F #清空规则 systemctl stop firewalld #关闭网络服务器3.在两台机器上, 分别配置好yum源, 下载saltstack软件
`在master机器上: yum install satl-master -y `在minion机器上: yum install salt-minion -y4.分别修改两个软件的配置文件,需要互相指定对方
编辑master的配置文件, 这个配置文件是yaml语法的,不得有任何错误,以及无用空格
vim /etc/salt/master 把如下参数的注释符删掉interface: 0.0.0.0 publish_port: 4505 user: root ret_port: 4506 pidfile: /var/run/salt-master.pid worker_threads: 5 ssh_log_file: /var/log/salt/ssh下属minion的配置如下
vim /etc/salt/minion 把如下参数的注释符删掉master: master master_port: 4506 user: root id: master log_file: /var/log/salt/minion5.分别启动master和minion,注意了, salt-minion发送密钥给master,是在重启的一瞬间发送的
systemctl start salt-master systemctl start salt-minion6.进行master密钥认证, 管理minion
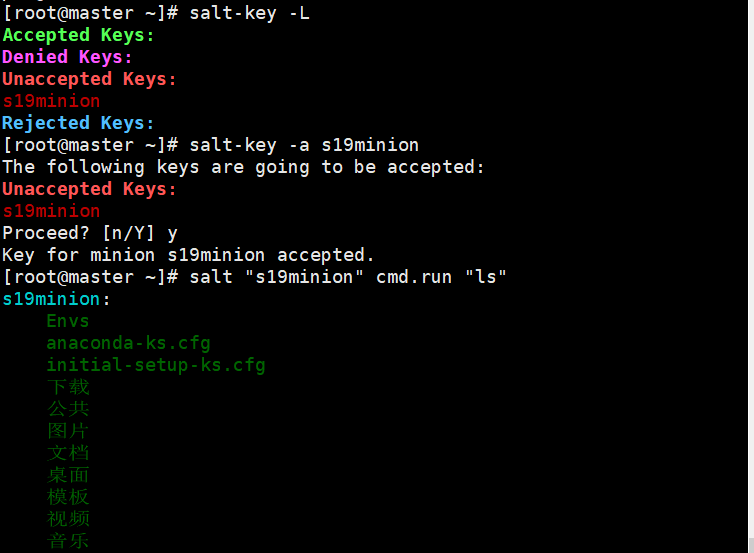
对密钥身份进行, 查看匹配
在服务端查看minion密钥信息
salt-key -f master在客户端minion查看自己的密钥信息
salt-call --local key.finger
[root@master /]# salt-key -L Accepted Keys: Denied Keys: Unaccepted Keys: master Rejected Keys:
salt-key -a minion #接受下属的密钥信息
遇事不决就重启
7.salt命令
salt-key -L #列出所有主机秘钥信息 salt-key -a #接收一个密钥id 常用参数 -A #允许所有 -D #删除所有 -a #认证指定的key -d #删除指定的key -r #注销指定的key(该状态为未被认证) # 星号代表目标匹配字符串中(所有的被管控机器) salt "*" cmd.run "你要远程执行的命令" salt "你要匹配的minion的id" cmd.run "命令" salt "你要匹配的minion的id" test.ping #检测机器是否存活 salt --out=json "*" test.ping #以json数据返回输出结果 salt "*" test.fib 50 #让所有的从机器,计算50以内斐波那契值 ---------------------------------------------------- salt提供了安装软件的模块命令, pkg模块就是调用的yum工具 salt 'slave' pkg.insatll "nginx" #所有的从机器就会执行yum install nginx ---------------------------------------------------- salt的远程管理模块 此模块调用的是yum安装的软件命令,并非自己编译安装的软件的命令 salt '*' service.satrt 'nginx' #告诉从机器执行`systemctl start nginx` salt '*' service.stop 'nginx' #告诉从机器执行`systemctl stop nginx` ---------------------------------------------------- 指定salt命令的输出格式 salt --out=json '*' cmd.run "hostname" #输出json数据可以反序列化 salt --out=YAML '*' cmd.run "hostname"#slinux的shebang 代表代码声明 例如 #!usr/bin/python写出你见过的配置文件格式
.cnf
.conf
.ini
.cfg
配置文件.xml
java常用.yml
用的yaml语法的配置文件.json
yaml语法
语法规则 大小写敏感 使用缩进表示层级关系 缩进时禁止使用tab键,只能空格 缩进的空格数不重要,相同层级是元素左侧对其即可 #表示注释行 yaml支持的数据结构 对象: 键值对,也称作映射......key: value冒号后必须有 数组:一组按次序排列的值,又称为序列 纯量:单个不可再分的值 对象:键值对yaml first_key: second_key: second_valuepython { 'first_key':{ 'second_key':'second_value', } }#yaml语法练习 'like': '五月天': -"怪兽" -"阿信" -"石头" -"玛莎" -"冠佑" '苏打绿': -"吴青峰" -"史俊威" -"龚钰琪" -"刘家凯" -"谢馨仪"End-Less
End-Less
###### salt的静态数据采集值grains, 可以在minion启动的时候,自动把自己所有的硬件资产信息,发送给给mastersalt --out=json 's19minion' grains.items #列出主机的所有信息,以json格式显示 salt 's19minion' grains.items os #列出os的信息 salt 's19minion' grains.items ipv4 #列出ipv4的信息master利用python的api操作两台minion关机
import salt local = salt.client.LocalClient() local.cmd("*", "cmd.run", ['poweroff']) # 成功结果如下 {'s19minion2': False, 's19minion': False}End-Less


linux 安装pycharm进行图形化开发
1.获取pycharm的inux版本