- A+
在Vue $mount过程中,我们需要把模版编译成render函数,整体实现可以分为三部分:
- parse:解析模版 template生成 AST语法树
- optimize: 优化 AST语法树,标记静态节点
- codegen: 把优化后的 AST语法树转换生成render方法代码字符串,利用模板引擎生成可执行的 render函数( render执行后返回的结果就是虚拟DOM,即以 VNode节点作为基础的树 )

Vue.js 提供了 2 个版本,一个是 Runtime + Compiler 的,一个是 Runtime only 的,前者是包含编译代码的,可以把编译过程放在运行时做,后者是不包含编译代码的,需要借助 webpack 的 vue-loader 事先把模板编译成 render函数。
下一章我们将介绍 render 和 patch 过程。关于 render函数如何生成虚拟DOM,以及如何将 vnode转化成真实DOM并挂载?

入口
Vue.prototype.$mount = function (el) { ... // 这里需要对模板进行编译 const render = compileToFunction(template) } export function compileToFunction(template) { // 1.解析模版template生成 AST语法树 let ast = parseHTML(template) // 2.优化AST语法树,标记静态节点 optimize(ast) // 3.把优化后的 AST语法树转换生成render方法代码字符串,利用模板引擎生成可执行的 render函数回的结果就是 虚拟DOM) let code = codegen(ast) code = `with(this){return ${code}}` let render = new Function(code) return render } parse
AST做的是语法层面的转化,就是用对象去描述语法本身,例如经过 parse过程后,对 html的描述如下

可以看到,生成的 AST 是一个树状结构,每一个节点都是一个 ast element,除了它自身的一些属性,还维护了它的父子关系,如 parent指向它的父节点,children指向它的所有子节点
我们也可以利用AST的可视化工具网站 - AST Exploer ,使用各种parse对代码进行AST转换
在 Vue的 $mount过程中,编译过程首先就是调用 parseHTML方法,解析 template模版,生成 AST语法树
在这个过程,我们会用到正则表达式对字符串解析,匹配开始标签、文本内容和闭合标签等
const ncname = `[a-zA-Z_][\-\.0-9_a-zA-Z]*` const qnameCapture = `((?:${ncname}\:)?${ncname})` // 匹配的是 <xxx 第一个分组就是开始标签的名字 const startTagOpen = new RegExp(`^<${qnameCapture}`) // 匹配的是 </xxxx> 第一个分组就是结束标签的名字 const endTag = new RegExp(`^<\/${qnameCapture}[^>]*>`) // 分组1: 属性的key 分组2: = 分组3/分组4/分组5: value值 const attribute = /^s*([^s"'<>/=]+)(?:s*(=)s*(?:"([^"]*)"+|'([^']*)'+|([^s"'=<>`]+)))?/ // 匹配属性 const startTagClose = /^s*(/?)>/ // 匹配开始标签的结束 > 或 /> <div id = 'app' > <br/> 使用 while 循环html字符串,利用正则去匹配开始标签、文本内容和闭合标签,然后执行 advance方法将匹配到的内容在原html字符串中剔除,直到html字符串为空,结束循环
export function parseHTML(html) { // 创建一颗抽象语法树 function createASTElement(tag, attrs) { } // 处理开始标签,利用栈型结构来构造一颗树 function start(tag, attrs) { } // 处理文本 function chars(text) { } // 处理结束标签 function end(tag) { } // 剔除 template 已匹配的内容 function advance(n) { html = html.substring(n) } // 解析开始标签 function parseStartTag() { const start = html.match(startTagOpen) if (start) { const match = { tagName: start[1], // 标签名 attrs: [], } advance(start[0].length) let attr, end // 如果不是开始标签的结束 就一直匹配下去 while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) { advance(attr[0].length) match.attrs.push({ name: attr[1], value: attr[3] || attr[4] || attr[5] || true }) } // 如果不是开始标签的结束 if (end) { advance(end[0].length) } return match } return false } // 循环html字符串,直到其为空停止 while (html) { // 如果textEnd = 0 说明是一个开始标签或者结束标签 // 如果textEnd > 0 说明就是文本的结束位置 let textEnd = html.indexOf('<') if (textEnd == 0) { // 开始标签的解析結果,包括 标签名 和 属性 const startTagMatch = parseStartTag() if (startTagMatch) { start(startTagMatch.tagName, startTagMatch.attrs) continue } // 匹配结束标签 let endTagMatch = html.match(endTag) if (endTagMatch) { advance(endTagMatch[0].length) end(endTagMatch[1]) continue } } if (textEnd > 0) { let text = html.substring(0, textEnd) // 截取文本内容 if (text) { chars(text) advance(text.length) } } } return root } 当我们使用正则匹配到开始标签、文本内容和闭合标签时,分别执行start、chars、end方法去处理,利用 stack 栈型数据结构,最终构造一颗AST树,即root
- 匹配到开始标签时,就创建一个 ast元素,判断如果有 currentParent,会把当前 ast元素 push到 currentParent.chilldren 中,同时把 ast元素的 parent 指向 currentParent,ast元素入栈并更新 currentParent
- 匹配到文本时,就给 currentParent.children push一个文本 ast元素
- 匹配到结束标签时,就弹出栈中最后一个 ast元素,更新 currentParent
currentParent:指向的是栈中的最后一个 ast节点
注意:栈中的当前 ast节点永远是下一个 ast节点的父节点
const ELEMENT_TYPE = 1 // 元素类型 const TEXT_TYPE = 3 // 文本类型 const stack = [] // 用于存放元素的栈 let currentParent // 指向的是栈中的最后一个 let root // 最终需要转化成一颗抽象语法树 function createASTElement(tag, attrs) { return { tag, // 标签名 type: ELEMENT_TYPE, // 类型 attrs, // 属性 parent: null, children: [], } } // 处理开始标签,利用栈型结构 来构造一颗树 function start(tag, attrs) { let node = createASTElement(tag, attrs) // 创造一个 ast节点 if (!root) { root = node // 如果root为空,则当前是树的根节点 } if (currentParent) { node.parent = currentParent // 只赋予了parent属性 currentParent.children.push(node) // 还需要让父亲记住自己 } stack.push(node) currentParent = node // currentParent为栈中的最后一个 } // 处理文本 function chars(text) { text = text.replace(/s/g, '') // 文本直接放到当前指向的节点中 if (text) { currentParent.children.push({ type: TEXT_TYPE, text, parent: currentParent, }) } } // 处理结束标签 function end(tag) { stack.pop() // 弹出栈中最后一个ast节点 currentParent = stack[stack.length - 1] } 当 AST 树构造完毕,下一步就是 optimize 优化这颗树
optimeize
当我们解析 template模版,生成 AST语法树之后,需要对这棵树进行 optimize优化,在编译阶段把一些 AST 节点优化成静态节点
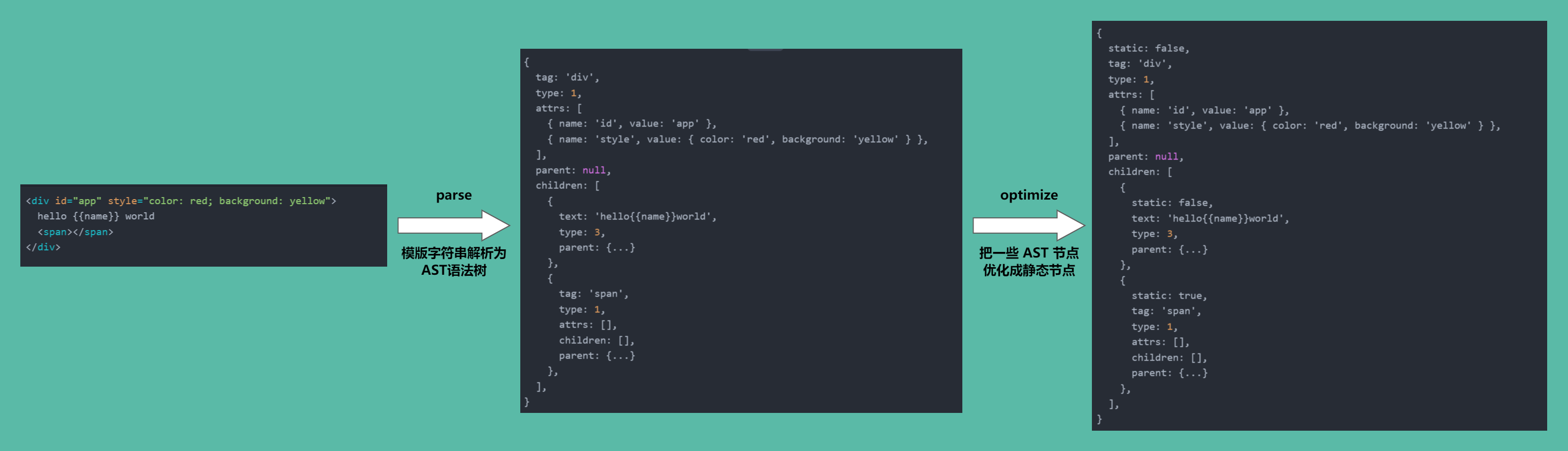
深度遍历这个 AST 树,去检测它的每一颗子树是不是静态节点,如果是静态节点则标记 static: true
为什么要有优化过程,因为我们知道 Vue 是数据驱动,是响应式的,但是我们的模板并不是所有数据都是响应式的,也有很多数据是首次渲染后就永远不会变化的,那么这部分数据生成的 DOM 也不会变化,我们可以在 patch 的过程跳过对他们的比对,这对运行时对模板的更新起到极大的优化作用。
codegen
编译的最后一步就是把优化后的 AST树转换成可执行的 render代码。此过程包含两部分,第一部分是使用 codegen方法生成 render代码字符串,第二部分是利用模板引擎转换成可执行的 render代码
render方法代码字符串格式如下

_c: 执行 createElement创建虚拟节点;_v: 执行 createTextVNode创建文本虚拟节点;_s: 处理变量
我们会在Vue原型上扩展这些方法
让我们来实现一个简单的codegen方法,深度遍历AST树去生成render代码字符串
function codegen(ast) { let children = genChildren(ast.children) let code = `_c('${ast.tag}',${ast.attrs.length > 0 ? genProps(ast.attrs) : 'null'}${ast.children.length ? `,${children}` : ''})` return code } // 根据ast语法树的 children对象 生成相对应的 children字符串 function genChildren(children) { return children.map(child => gen(child)).join(',') } const defaultTagRE = /{{((?:.|r?n)+?)}}/g // 匹配到的内容就是我们表达式的变量,例如 {{ name }} function gen(node) { if (node.type === 1) { // 元素 return codegen(node) } else { // 文本 let text = node.text if (!defaultTagRE.test(text)) { // _v('hello') return `_v(${JSON.stringify(text)})` } else { //_v( _s(name) + 'hello' + _s(age)) ... 拼接 _s return `_v(${tokens.join('+')})` } } } // 根据ast语法树的 attrs属性对象 生成相对应的属性字符串 function genProps(attrs) { let str = '' for (let i = 0; i < attrs.length; i++) { let attr = attrs[i] str += `${attr.name}:${JSON.stringify(attr.value)},` // id:'app',class:'app-inner', } return `{${str.slice(0, -1)}}` } 模板引擎的实现原理就是 with + new Function(),转换成可执行的函数,最终赋值给vm.options.render
let code = codegen(ast) code = `with(this){return ${code}}` let render = new Function(code) 尤大大亲自解读: Vue2模板编译为何使用with
with 的作用域和模板的作用域正好契合,可以极大地简化模板编译过程。用 with 代码量可以很少,而且把作用域的处理交给 js 引擎来做也更可靠
用 with 的主要副作用是生成的代码不能在 strict mode / ES module 中运行,但直接在浏览器里编译的时候因为用了 new Function(),等同于 eval,不受这一点影响




