- A+
1 管道命令(pipe)介绍
众所周知,bash命令执行的时候会输出信息,但有时这些信息必须要经过几次处理之后才能得到我们想要的格式,此时应该如何处置?这就牵涉到 管道命令(pipe) 了。管道命令使用的是|这个界定符号。另外,管道命令与连续执行命令是不一样的,这点下面我们会说明。
我们先来看一个管道命令的例子。假设我们需要看/etc目录下有多少文件,那么可以利用ls /etc来查看,不过由于文件数量太多,导致一口气就将屏幕塞满了,而不知道前面输出的内容是啥:
root@orion-orion:~ ls -al /etc root@qi total 944 drwxr-xr-x 1 root root 4096 Feb 19 11:38 . drwxr-xr-x 1 root root 4096 Nov 23 2021 .. drwxr-xr-x 3 root root 4096 Jun 5 2021 .java ... drwxr-xr-x 2 root root 4096 Jul 24 2018 xfce4 此时,我们可以使用less命令的协助:
root@orion-orion:~ ls -al /etc | less total 944 drwxr-xr-x 1 root root 4096 Feb 19 11:38 . drwxr-xr-x 1 root root 4096 Nov 23 2021 .. drwxr-xr-x 3 root root 4096 Jun 5 2021 .java : 如此一来,使用ls命令输出的内容就能够被less读取,并且利用less的功能,我们就能够前后翻动相关的信息了。其中的关键就是这个管道命令|。管道命令|仅能处理前一个命令传来的标准输出信息,而对于标准错误信息并没有直接处理能力。那么整体的管道命令可以使用下图表示:
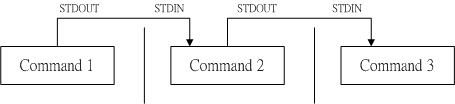
在每个管道后面接的第一个数据必定是命令,而且这个命令必须要能够接受标准输出的数据才行,这样的命令才可为管道命令。例如less、grep、sed、awk等都是可以接受标准输入的管道命令,而ls、cp、mv就不是管道命令,因为它们并不会接受来自stdin的数据。总结一下,管道命令主要有两个需要注意的地方:
- 管道命令仅会处理标准输出,对于标准错误会予以忽略;
- 管道命令必须要能够接受来自前一个命令的数据成为标准输入继续处理才行(这也是其与连续执行命令之不同)。
如果我们强行让标准错误为管道命令所用,那么可以使用
2>&1将标准错误2>重定向到标准输出1>。
接下来我们选取grep、sed、awk这三个用于文本处理的管道命令来进行介绍。这三个命令可谓是Linux下操作文本的三大利器,合称Linux文本处理三剑客。
2 行选取命令grep
grep命令可以一行一行地分析信息,若某行含有我们所需要的信息,则就将该行拿出来。简单的语法如下:
grep [-acinv] [--color=auto] '查找字符' filename 它的选项与参数如下:
-a:将二进制文件以文本文件的方式查找数据。-c:计算找到'查找字符'的次数。-i:忽略大小写的不同,所以大小写视为相同。-n:顺便输出行号。-v:反向选择,亦即显示出没有'查找字符'内容的那些行。
下面展示几个例子。
范例一:将last当中,有出现root的那一行就显示出来。
root@orion-orion:~ last | grep 'root' root pts/2 10.249.252.8 Mon Apr 6 06:08 - 09:02 (02:54) root pts/1 10.249.252.8 Mon Apr 6 06:05 - 06:08 (00:03) root pts/1 10.249.252.8 Mon Apr 6 03:13 - 06:05 (02:51) ... root pts/1 :1 Tue Jul 24 06:44 - 06:45 (00:00) root pts/1 172.17.0.1 Tue Apr 10 14:23 - 14:23 (00:00) root pts/1 127.0.0.1 Tue Apr 10 08:57 - 08:57 (00:00) 这里前3行是我们校内的局域网IP(以10.249打头),172.17.0.1是Docker中默认网桥docker0的IP地址,127.0.0.1为本地回环地址。
范例二:与范例一相反,只要没有root的就取出。
root@orion-orion:~ last | grep -v 'root' person pts/1 127.0.0.1 Tue Apr 10 08:54 - 08:54 (00:00) 范例三:在last的输出信息中,只要有root就取出,并且仅取第一栏:
root@orion-orion:~ last | grep "root" | awk '{print $1}' root root root ... 这里用到了我们后面要讲的awk命令,这一命令用于将一行分为多个字段来处理,我们后面将会详细介绍。
范例四:取出/etc/adduser.conf内含UID的那几行,且将找到的关键字部分用特殊颜色显示出来:
root@orion-orion:~ grep --color=auto "UID" /etc/adduser.conf root@qi # FIRST_SYSTEM_[GU]ID to LAST_SYSTEM_[GU]ID inclusive is the range for UIDs # package, may assume that UIDs less than 100 are unallocated. FIRST_SYSTEM_UID=100 LAST_SYSTEM_UID=999 # FIRST_[GU]ID to LAST_[GU]ID inclusive is the range of UIDs of dynamically FIRST_UID=1000 LAST_UID=29999 可以看到找到的关键字部分用红色显示(当然这里的代码块看不出来效果,需要在终端进行渲染)。注意,在我的Ubuntu 18.04系统中默认的grep已经主动使用--color=auto选项在alias中了,因此不用手动加--color=auto也会标红(事实上,在我本地的Mac系统中也是如此)。
3 行操作命令sed
前面我们说过,grep命令可以解析一行文字,若该行含有某关键词就会将其整行列出来。接下来我们要讲的sed命令也是一个管道命令(可以分析标准输入),它还可以对特定行进行新增、删除、替换等。sed的用法如下:
sed [-nefr] [操作] 它的选项与参数如下:
-n:使用安静(silent)模式。在一般的sed用法中,所有来自stdin的数据一般都会被列出到屏幕上,但如果加上-n参数后,则只有经过sed选择的那些行才会被列出来。-e:使sed的操作结果由屏幕输出,而改变原有文件(默认已选该参数, 与-i的直接修改文件相反)。-f:从一个文件内读取将要执行的sed操作,-f filename可以执行filename中写好的sed操作。-r:sed的操作使用的是扩展型正则表达式的语法(默认是基础正则表达式语法)。-i:直接修改读取的文件内容,而不是由屏幕输出。
关于其中的[操作]部分,其格式如下:
[n1[,n2]]function n1, n2:不一定会存在,一般代表选择进行操作的行数,比如我的操作需要在10到20行之间进行,则写为10, 20[操作名称]。
具体地,对行的操作函数function包括下面这些东西:
a:新增,a的后面可以接字符,这些字符将被添加在n1/n2的下一行;c:替换,c的后面可以接字符,这些字符可以替换n1,n2之间的行;d:删除,因为是删除,所以d后面通常不需要接任何东西;i:插入,i的后面可以接字符,这些字符将被添加在n1/n2的上一行;p:打印,亦即将某些选择的行打印出来。通常p会与参数sed -n一起运行。s:替换,可以直接进行替换的工作,通常这个s的操作可以搭配正则表达式。
下面我们来举几个例子进行说明。
以行为单位的新增/删除功能
范例一:查看/etc/passwd文件的内容并且在每一行前面加上行号,同时将2-5行删除。
root@orion-orion:~ cat -n /etc/passwd | sed '2,5d' 1 root:x:0:0:root:/root:/bin/zsh 6 games:x:5:60:games:/usr/games:/usr/sbin/nologin 7 man:x:6:12:man:/var/cache/man:/usr/sbin/nologin 8 lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin ... 可以看到sed的操作为2,5d,也即删除2~5行,所以显示的数据就没有2~5行。此外,请注意原本应该是要执行sed -e才对,不过这里没有-e也行,因为已经默认选了。同时也要注意sed后面接的操作务必以两个单引号''括住。
我们将范例变一下,如果要删除第2行,那么可以使用cat -n /etc/passwd | sed '2d' ;如果是要删除第3到最后一行,则是cat -n /etc/passwd | sed '3,$d',这里美元符号$代表最后一行。
范例二: 承接上题,在第2行后(亦即是第3行)加上drink tea字样。
root@orion-orion:~ cat -n /etc/passwd | sed '2a Drink tea?' 1 root:x:0:0:root:/root:/bin/zsh 2 daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin Drink tea? 3 bin:x:2:2:bin:/bin:/usr/sbin/nologin ... 如果想要加在第2行前面,将新增操作改为插入操作,即cat -n /etc/passwd | sed '2i Drink tea?'就行了。
范例三:继续承接上题,现在我们想要在第2行后面加上两行字,例如Drink tea or...与Drink beer?
root@orion-orion:~ cat -n /etc/passwd | sed '2a Drink tea or... root@qi Drink beer?' 1 root:x:0:0:root:/root:/bin/zsh 2 daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin Drink tea or... Drink beer? 3 bin:x:2:2:bin:/bin:/usr/sbin/nologin 这里的重点在于我们可以不只增加一行,可以增加很多行,但每一行之间必须以反斜杠来进行新行的增加。
以行为单位的替换与显示功能
刚刚是介绍如何新增与删除行。接下来我们看看如何进行整行的替换。
范例四:我想将2~5行的内容替换为No 2-5 number。
root@orion-orion:~ cat -n /etc/passwd | sed '2,5c No 2-5 number` 1 root:x:0:0:root:/root:/bin/zsh No 2-5 number 6 games:x:5:60:games:/usr/games:/usr/sbin/nologin ... 除此之外,sed还有很有趣的功能,以前我们想要列出第11~25行,得用head -n 20或tail -n 10之类的命令来处理,很麻烦。而sed则可以直接取出你想要的那几行,这是通过行号来识别的。例如下面这个范例:
范例五:仅列出/etc/passwd文件内的第5-7行。
root@orion-orion:~ cat -n /etc/passwd | sed -n '5,7p' 5 sync:x:4:65534:sync:/bin:/bin/sync 6 games:x:5:60:games:/usr/games:/usr/sbin/nologin 7 man:x:6:12:man:/var/cache/man:/usr/sbin/nologin 注意,这里必须要加-n表示安静模式。如果不加-n改为sed 5,7p,那么第5-7行会重复输出:
root@orion-orion:~ cat -n /etc/passwd | sed '5,7p' 1 root:x:0:0:root:/root:/bin/zsh 2 daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin 3 bin:x:2:2:bin:/bin:/usr/sbin/nologin 4 sys:x:3:3:sys:/dev:/usr/sbin/nologin 5 sync:x:4:65534:sync:/bin:/bin/sync 5 sync:x:4:65534:sync:/bin:/bin/sync 6 games:x:5:60:games:/usr/games:/usr/sbin/nologin 6 games:x:5:60:games:/usr/games:/usr/sbin/nologin 7 man:x:6:12:man:/var/cache/man:/usr/sbin/nologin 7 man:x:6:12:man:/var/cache/man:/usr/sbin/nologin 8 lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin ... 部分数据的查找并替换的功能
除了整行的处理模式之外,sed还可以对某行进行部分数据的查找和替换。基本上sed的查找与替换与vi相当的类似,它的格式如下所示:
sed 's/要被替换的字符/新的字符/g' 接下来我们来看一个取得IP数据的范例,我们将该任务拆解为多步,一段一段地处理。
步骤一:先观察原始信息,利用/sbin/ifconfig查询IP是什么?
root@orion-orion:~ /sbin/ifconfig eth0 eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:0c inet addr:172.17.0.12 Bcast:172.17.255.255 Mask:255.255.0.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:49498631 errors:0 dropped:0 overruns:0 frame:0 TX packets:41131666 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:51467728818 (51.4 GB) TX bytes:40995045195 (40.9 GB) 我们希望用关键词识别出172.17.0.12,这是我所用学校服务器的内网私有IP地址。
步骤二:利用关键字配合grep选取出inet所在的那关键的一行。
root@orion-orion:~ /sbin/ifconfig eth0 | grep 'inet ' inet addr:172.17.0.12 Bcast:172.17.255.255 Mask:255.255.0.0 好了,现在只剩下一行了,但我们想只留下IP地址addr:172.17.0.12而将其它部分统统删除。
步骤三:先将IP前面的部分予以删除(用到正则表达式)。
root@orion-orion:~ /sbin/ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g' addr:172.17.0.12 Bcast:172.17.255.255 Mask:255.255.0.0 这里正则表达式中的^表示待查找的字符串在行首;.表示一定有一个任意字符,*表示重复前一个字符0到无穷多次,连在一起的.*就表示任意字符重复任意次;//之间为空,也就表示删除的意思。
步骤四:将IP后面的部分也予以删除。
root@orion-orion:~ /sbin/ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g' | sed 's/ *Bcast.*$//g' addr:172.17.0.12 这里' *'表示空格重复任意次;.*表示任意字符重复任意次;$表示待查找的字符串在行尾。
我们再来继续研究sed与正则表达式的配合练习。假设我们只要/etc/adduser.conf 文件中UID存在的那几行数据,但是有#在内的注释我们不要,而且空白行我们也不要,那么应该如何处理?可以通过这几个步骤来实践看看:
步骤一:先用grep将关键字UID所在行取出来。
root@orion-orion:~ cat /etc/adduser.conf | grep 'UID' # FIRST_SYSTEM_[GU]ID to LAST_SYSTEM_[GU]ID inclusive is the range for UIDs # package, may assume that UIDs less than 100 are unallocated. FIRST_SYSTEM_UID=100 LAST_SYSTEM_UID=999 # FIRST_[GU]ID to LAST_[GU]ID inclusive is the range of UIDs of dynamically FIRST_UID=1000 LAST_UID=29999 步骤二:删除掉注释之后的内容:
root@orion-orion:~ cat /etc/adduser.conf | grep 'UID' | sed 's/#.*$//g' FIRST_SYSTEM_UID=100 LAST_SYSTEM_UID=999 FIRST_UID=1000 LAST_UID=29999 这样原本注释的内容都变成了空白行,接下来我们删除空白行:
root@orion-orion:~ cat /etc/adduser.conf | grep 'UID' | sed 's/#.*$//g' | sed '/^$/d' FIRST_SYSTEM_UID=100 LAST_SYSTEM_UID=999 FIRST_UID=1000 LAST_UID=29999 注意这里的^$表示行首^和行尾$之间没有字符,也即空白行。
直接修改文件内容(危险操作)
sed的能耐可不止于我们上面所说的,它甚至可以直接修改文件的内容,而不必使用管道命令或数据流重定向。不过这个操作会修改到原始的文件,所以请你千万不要随便拿系统配置文件来测试。我们下面使用regular_express.txt文件来测试(文件可以去鸟哥的官网下载:regular_express.txt)。
root@orion-orion:~ cat regular_express.txt root@qi "Open Source" is a good mechanism to develop programs. apple is my favorite food. Football game is not use feet only. this dress doesn't fit me. ... go! go! Let's go. # I am VBird 范例六:利用sed将regular_express.txt内每一行结尾若为.则换成!。
root@orion-orion:~ sed -i 's/.$/!/g' regular_express.txt root@orion-orion:~ cat regular_express.txt "Open Source" is a good mechanism to develop programs! apple is my favorite food! Football game is not use feet only! this dress doesn't fit me! ... go! go! Let's go! # I am VBird 上面的-i选项可以让你的sed直接去修改后面所接的文件内容而不是由屏幕输出。
范例七:利用sed直接在regular_express.txt最后一行加入# This is a test。
root@orion-orion:~ sed -i '$a # This is a test' regular_express.txt root@orion-orion:~ tail regular_express.txt ... go! go! Let's go! # I am VBird # This is a test 由于$代表的是最后一行,而a的操作是新增,因此是该文件最后新增。
sed的-i选项可以直接修改文件内容,因此这功能非常有帮助。比如如果你有一个100万行的文件,你要在第100行加某些文字,此时使用vim可能会疯掉,因为文件太大了。此时就可以利用sed来直接修改与替换,而不需要使用vim去修改了。
4 字段操作命令awk
相较于sed常常对一整行进行操作,awk则倾向于将一行分为多个字段来处理。因此,awk相当适合处理小型的文本数据,其运行模式通常是这样的:
awk '{条件类型1{操作1} 条件类型2{操作2} ...}' filename awk后接两个单引号并加上大括号{}来设置想要对数据进行的处理操作。awk可以处理后续接的文件,也可以读取来自前一个命令的标准输出。如前面所说,awk主要是将每一行分为多个字段来处理,而默认的字段分隔符为空格键或[Tab]键。举例来说,我们用last将登陆者的数据取出来(仅取出前3行):
root@orion-orion:~ last -n 3 root pts/292 10.249.45.37 Wed Mar 29 06:55 - 09:14 (02:19) root pts/292 10.249.45.37 Tue Mar 28 13:17 - 16:14 (02:56) root pts/292 10.249.45.37 Tue Mar 28 12:35 - 13:17 (00:42) wtmp begins Tue Apr 10 08:54:45 2018 若我想取出账号与登陆者的IP,且账号与IP之间以[Tab]隔开,则会变成这样:
root@orion-orion:~ last -n 3 | awk '{print $1 "t" $3}' root@qi root 10.249.45.37 root 10.249.45.37 root 10.249.45.37 注意,awk的所有后续操作都是以单引号括住的,而awk的格式内容如果想要以print打印时,记得将非变量的文字部分使用双引号括起来,因为单引号已经是awk命令的固定用法了。此外,因为这里无论哪一行我们都要处理,因此就不需要有条件类型的限制。
另外,由上面的例子我们看到,在awk的括号内,每一行的每个字段都有变量名称($1,$2等)。在上面的例子中,root位于第1栏,故其变量名称为$1;而10.249.45.37是第3栏,故它是$3,后面以此类推。还有个变量比较特殊,那就是$0,它表示一整行数据。由此可知,刚刚上面5行当中,整个awk的处理流程就是:
- 一次性读入第1行整行的数据并存入
$0,然后将其拆分为多个字段并写入$1、$2、$3等变量当中。 - 根据
条件类型的限制,判断是否需要进行后面的操作(在上面这个例子中没有条件类型)。 - 完成所有操作与条件类型。
- 若还有后续行的数据,则重复上面1~3的步骤,直到所有的数据都读完为止。
经过这样的步骤,我们看到了awk是以行为一次处理的单位,而以字段为最小的处理单位。好了,那么如何快速地获得我们的数据有几行几列呢?这就需要awk的内置变量的帮忙。
| 变量名称 | 代表意义 |
|---|---|
NF |
每一行(也即$0)所拥有的字段总数 |
NR |
目前awk所处理的是第几行数据 |
FS |
目前的分割字符,默认是空格键 |
我们继续以上面last -n 3的例子来做说明,如果我想要:
- 列出每一行的账号(也就是
$1); - 列出目前处理的行数(就是
awk内的NR变量); - 并且说明该行有多少字段(也就是
awk内的NF字段);
则可以这样:
root@orion-orion:~ last -n 5 | awk '{print $1 "t lines: " NR "t columns: " NF}' root lines: 1 columns: 10 root lines: 2 columns: 10 root lines: 3 columns: 10 lines: 4 columns: 0 wtmp lines: 5 columns: 7 注意,在awk内的NR、NF等变量要用大写,且不需要有美元符号$。
接下来我们来看一看所谓的“条件类型”。
awk 的逻辑运算字符
既然要用到“条件”的类别,那么自然就需要一些逻辑运算,如下所示:
| 运算单元 | 代表意义 |
|---|---|
> |
大于 |
< |
小于 |
>= |
大于或等于 |
<= |
小于或等于 |
== |
等于 |
!= |
不等于 |
注意,逻辑运算即所谓的大于、小于等于等判断式上面,习惯上用==而不是=来表示,=符号在awk操作这里留给了变量赋值用。
我们来看下面一个例子。比如在/etc/passwd中是以冒号:来作为字段的分隔,该文件中第一字段为账号,第三字段为UID。如下所示:
root@orion-orion:~ cat /etc/passwd | less root@qi root:x:0:0:root:/root:/bin/zsh daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin bin:x:2:2:bin:/bin:/usr/sbin/nologin ... dnsmasq:x:115:65534:dnsmasq,,,:/var/lib/misc:/bin/false 那假设我要查看第三栏小于10的数据,并且仅列出账号与第三列,那么可以这样做:
root@orion-orion:~ cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "t " $3}' root:x:0:0:root:/root:/bin/zsh daemon 1 bin 2 ... 诶,不过怎么第一行没有正确地显示出来?这是因为我们在读入第一行的时候,那些变量$1、$2等等默认还是以空格键做为分割,所以虽然我们定义了FS=":",但却仅能在第二行后才开始生效。那怎么办呢?我们可以预先设置awk的变量,利用BEGIN这个关键词,这样做:
root@orion-orion:~ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "t " $3}' root 0 daemon 1 bin 2 ... 接下来我们来看如何用awk来完成计算功能。
假设我们有一个薪资数据表文件为pay.txt,内容如下:
root@orion-orion:~ cat pay.txt Name 1st 2nd 3th VBird 23000 24000 25000 DMTsai 21000 20000 23000 Bird2 43000 42000 41000 如何来计算每个人1st、2nd、3th的总额呢?而且我们还需要格式化输出。我们可以这样考虑:
- 第一行只是表头,所以第一行不进行求和而仅需要对表头进行打印(也即
NR==1时处理)。 - 第二行以后进行求和(
NR>=2以后处理)。
root@orion-orion:~ cat pay.txt | awk 'NR == 1 {printf "%10s %10s %10s %10s %10sn", $1, $2, $3, $4, "Total"} NR >= 2 {total = $2 + $3 + $4; printf "%10s %10d %10d %10d %10.2fn", $1, $2, $3, $4, total}' Name 1st 2nd 3th Total VBird 23000 24000 25000 72000.00 DMTsai 21000 20000 23000 64000.00 Bird2 43000 42000 41000 126000.00 上面的例子有几个重要事项应该要先说明:
awk的命令间隔:所有awk的操作,亦即在{}里的操作,如果有需要多个命令辅助时,可利用分号;间隔。- 逻辑运算中,如果是“等于”的情况,请务必使用
==; - 格式化输出时,在printf的格式设置中,务必加上
n,才能分行(这里注意可以和Python的print函数和shell的echo函数做对比,此二者自带换行); - 与bash shell中的变量不同,
awk中的变量可以直接使用,不需要加上$符号。
另外,awk的操作内{}也是支持if( 条件 )的,比如上面的命令也可以写为:
root@orion-orion:~ cat pay.txt | awk '{if (NR == 1) printf "%10s %10s %10s %10s %10sn", $1, $2, $3, $4, "Total"} NR >= 2 {total = $2 + $3 + $4; printf "%10s %10d %10d %10d %10.2fn", $1, $2, $3, $4, total}' Name 1st 2nd 3th Total VBird 23000 24000 25000 72000.00 DMTsai 21000 20000 23000 64000.00 Bird2 43000 42000 41000 126000.00 第一种写法相较于第二种写法更好,因为比较有统一性。
除此之外,awk还可以帮我们进行循环计算,不过那属于比较高级的单独课程了,这里就不再多加以介绍。
5 习题
情景模拟题一
通过grep配合子命令$(command)来从大量文件中查找含有星号*的文件与内容。
- 我们先来看如何在
/etc下面找出含有星号*的文件与内容。
root@orion-orion:~ grep '*' /etc/* 2> /dev/null /etc/adduser.conf:#NAME_REGEX="^[a-z][-a-z0-9_]*$" /etc/bash.bashrc:#xterm*|rxvt*) /etc/bash.bashrc:#*) ... 注意,这里单引号''内的型号是正则表达式的字符,但由于我们要找的是星号,因此需要加上转义符;而/etc/*的那个*是bash通配符中的“万用字符”,在这里代表拥有任意多个字符的文件名。
不过在上述的这个例子中,我们仅能找到/etc下第一层子目录的数据,无法找到次目录的数据。如果想要连同完整的/etc此目录数据,就得要这样做:
root@orion-orion:~ grep '*' $(find /etc -type f) 2> /dev/null Binary file /etc/ld.so.cache matches /etc/xdg/xfce4/xinitrc: for i in ${XDG_CONFIG_HOME}/autostart/*.desktop; do /etc/xdg/xfce4/xinitrc: x|xno*) /etc/xdg/xfce4/xinitrc: *) ... 如果只想列出文件名而不想列出内容的话,可以加个-l参数:
root@orion-orion:~ grep -l '*' $(find /etc -type f) 2> /dev/null /etc/ld.so.cache /etc/xdg/xfce4/xinitrc /etc/xdg/Thunar/uca.xml /etc/skel/.bashrc ... - 又是文件数量会太多,比如如果我们要找的是全系统
/的话:
root@orion-orion:~ grep '*' $(find / -type f) 2> /dev/null 芜湖,一运行这个命令,由于要打印的东西太多,终端直接卡死。这下该如何是好呢?此时我们可以通过管道命令以及xargs来处理。比如,让grep每次仅能处理10个文件名,我们可以:
a. 先用find去找出文件;
b. 用xargs将这些文件每次丢10个给grep来作为参数处理;
c. grep实际开始查找文件内容;
所以整个做法会变成这样:
root@orion-orion:~ find / -type f 2> /dev/null | xargs -n 10 grep '*' Binary file /sbin/chcpu matches Binary file /sbin/sulogin matches Binary file /sbin/pivot_root matches ... 然而,从输出的结果看,数据量实在非常庞大,如果我们只想知道文件名的话也可以给grep加上-l参数:
root@orion-orion:~ find / -type f 2> /dev/null | xargs -n 10 grep -l '*' /sbin/chcpu /sbin/sulogin /sbin/pivot_root ... 情景模拟题二
使用管道命令配合正则表达式建立新命令与新变量。我们想要建立一个名为myip的新命令,这个命令能够将我系统的IP识别出来并显示。而且我们想要有个新变量MYIP来记录我们的IP。
处理的方式如下所示:
- 首先根据我们前面所讲的
ifconfig、sed与awk来取得我们的IP:
root@orion-orion:~ ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g' | sed 's/ *Bcast.*$//g' addr:172.17.0.12 - 接着,我们可以将此命令利用
alias指定为myip,如下所示:
root@orion-orion:~ alias myip="ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g' | sed 's/ *Bcast.*$//g'" root@orion-orion:~ myip addr:172.17.0.12 - 最终,我们可以通过变量设置来处理
MYIP。
root@orion-orion:~ MYIP=$(myip) ~/orion-orion echo $MYIP addr:172.17.0.12 - 如果每次登陆都要生效,可以将
alias与MYIP设置的那两行写入你的~/.bashrc即可。
参考
- [1] 鸟哥. 鸟哥的 Linux 私房菜: 基础学习篇(第四版)[M]. 人民邮电出版社, 2018.




