- A+
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助
在业务中,有这么一种场景,表格下的某一列 ID 值,文本超长了,正常而言会是这样:

通常,这种情况都需要超长省略溢出打点,那么,就会变成这样:

但是,这种展示有个缺点,3 个 ID 看上去就完全一致了,因此,PM 希望能够实现头部省略打点,尾部完全展示,那么,最终希望的效果就会是这样的:

OK,很有意思的一个需求,最开始我以为只是实现一个头部超长溢出打点功能,但是随着实践,发现事情并没有那么简单,下面我们就一探究竟。
利用 direction 实现头部超长溢出打点
正常而言,我们的单行超长溢出打点,都是实现在尾部的,代码也非常简单,像是这样:
<p>Make CSS Ellipsis Beginning of String</p>
p { overflow: hidden; text-overflow: ellipsis; white-space: nowrap; }

这里,我们可以通过 direction,将省略打点的位置,从尾部移动至头部:
p { direction: rtl; }
结果如下:

简单介绍一下 direction:
direction:CSS 中的direction用于设置文本排列的方向。 rtl 表示从右到左 (类似希伯来语或阿拉伯语), ltr 表示从左到右。
另外两个与排版相关的属性还有:
writing-mode:定义了文本水平或垂直排布以及在块级元素中文本的行进方向。unicode-bidi:它与direction非常类似,两个会经常一起出现。在现代计算机应用中,最常用来处理双向文字的算法是Unicode 双向算法。而unicode-bidi这个属性是用来重写这个算法的。
OK,那么上述需求,是不是简单的添加一个 direction: rtl 就能解决问题呢?我们尝试一下。
direction: rtl 会导致使用下划线 _ 连接的数字内容排版错误
我们给上述的代码,添加一个简单的结构:
<div> 13993199751_18037893546_4477657 </div> <div> 13993199751_18037893546_4477656 </div> <div> 13993199751_18037893546_4477655 </div>
div { width: 180px; overflow: hidden; text-overflow: ellipsis; direction: rtl; white-space: nowrap; }
效果如下:

~成功了!~看似好像成功了,但是出了一点小问题!
虽然实现了头部打点,但是我们的数字结尾好像不是我们想要的结果,仔细看一下数字的结尾情况:
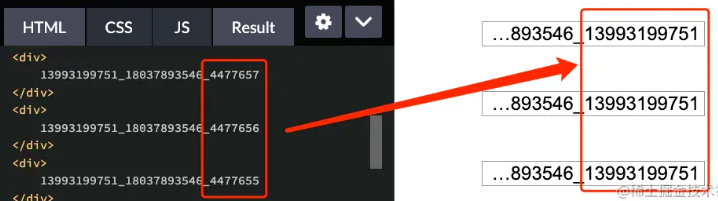
这是什么情况呢?
这是由于 direction 在处理纯数字、非纯数字文本上的规则不一致,我们再来看这么一段测试代码:
<div> 11111_22222_33333_44444 </div> <div> 11111 22222 33333 44444 </div> <div> aaaaa bbbbb ccccc dddddd eeeeee </div> <div> aaaaa_11111_22222_33333_44444 </div>
CSS 层面不考虑溢出情况,仅作用 direction: rtl 。
div { width: 240px; direction: rtl; }
在修改书写方向后,效果如下:

可以看到,这里非常核心的一点在于,对于纯数字的文本内容,数字的排列顺序也会跟着相应的书写顺序,进行反向排列!
而形如 11111_22222_33333_44444 这种用下划线连接的文本,处理的方式也会与 11111 22222 33333 44444 一样,实现了从左往右的排列,改变了原有的顺序。
多方案解决
因为我们的 ID是由纯数字加下划线组成,所以无法绕开这种展示。
那么,基于这个现状,我们可以如何去解决这个问题呢?
方案一:两次 direction 反转
方法一,既然最终展示的文案被反转了,那么我们可以尝试通过多一层的嵌套,进行二次反转可以解决问题。
代码如下:
<div class="g-twice-reverse"> <span>13993199751_18037893546_4477657</span> </div>
.g-twice-reverse { overflow: hidden; text-overflow: ellipsis; direction: rtl; white-space: nowrap; span { direction: ltr; }; }
尝试后的结果如下:

...037893546_4477657。不过不用着急,可以尝试再配合 unicode-bidi 属性试一下。最终发现,配合 unicode-bidi: bidi-override 可以实现我们想要的最终效果:.g-twice-reverse { overflow: hidden; text-overflow: ellipsis; direction: rtl; white-space: nowrap; span { direction: ltr; unicode-bidi: bidi-override; }; }
最终结果如下:

完美!这里,我们利用了两层结构:
- 外层的
g-twice-reverse正常设置从右向左的溢出省略打点 - 内容添加一层
span,利用direction: ltr和unicode-bidi: bidi-override的配合,在内部再反向反转排版规则。
当然,这里需要解释一下 unicode-bidi。
bidi-override 的作用是对文本进行覆盖,使得其中的内联元素(inline element)按照我们想要的书写方向展示。而 unicode-bidi: bidi-override 取值的作用是用于覆盖默认的 Unicode 双向算法以控制文本的显示方向。
这里,bidi-override 和 direction 在 <span> 中的组合,实现了更细粒度的文本方向处理。
方案二:通过伪元素破坏其纯数字的性质
上述的方案需要完全理解其思路还是有比较高的成本的,比较烧脑。
有没有更好理解的方案呢?我们继续尝试。
既然上面被反转排版的内容是纯数字或者由下划线连接成的数字,那么我们能不能尝试破坏其纯数字的特性?
譬如,给数组的头部添加一个看不见字母,尝试一下,这里构造两组数据对比一下:
<div class="g-add-letter"> <span>a</span> <span>546_4477657</span> </div> <div class="g-add-letter"> <span>a</span> <span>13993199751_18037893546_4477657</span> </div>
.g-twice-reverse { overflow: hidden; text-overflow: ellipsis; direction: rtl; white-space: nowrap; }
看看效果:

嘿,别说,这个方案看上去真的可行。只是添加一个 <span>a</span> 肯定是不合适的,后面维护的同学肯定一脸懵逼。并且这个 a 字母需要隐藏起来。思来想去,这不是和以前清除浮动的场景非常类似吗?这里使用伪元素再贴切不过,我们再改造下代码:
<div class="g-add-letter"> <span>546_4477657</span> </div> <div class="g-add-letter"> <span>13993199751_18037893546_4477657</span> </div>
.g-add-letter { overflow: hidden; text-overflow: ellipsis; direction: rtl; white-space: nowrap; span::before { content: "a"; opacity: 0; font-size: 0; } }
我们通过伪元素,使用在元素前面添加了一个字母 a,并且设置伪元素的 font-size: 0 和 opacity: 0,从外观上,完全看不出有这么个元素,非常好的隐藏了起来,同时,起到了破坏内容其纯数字的性质。
效果如下:

方案三:通过 200e LRM 标记位
我们继续优化我们的方案。
上面通过伪元素的方式,已经能够实现在对业务结构影响最小化及代码增量较少的前提下,实现想要的结果。
问题还是在于插入的这个字母 a,一来是不够优雅,二是这种解决方案更像是一种 HACK 的解决方式,随着时间长河的推进,这种代码即便留下了注释,也容易造成可读性上困扰。
所以,我们需要尝试替换掉这个 a 字母。
这里,通过查阅资料,最终找到了这样一个字符 -- 200e。
200e:是左到右标记(Left-to-Right Mark,LRM)的 Unicode 码点。它是 Unicode 字符方向控制工具之一,用于强制将文本的阅读方向指定为从左到右。在前端排版中,特别是处理多语言文本时,由于不同语言书写时有不同的书写方向,因此可以使用 LRM 来指定文本的书写方向,以确保文本能够正确地显示。
这里,通过 200e 替换掉 a,这里用 200e 的目的与 a 的目的其实是不一样的:
- 在字符串前面通过伪元素添加一个
a,目的是破坏其纯数字的特性 - 在字符串前面通过伪元素添加一个
200e,目的是强制控制接下来文本的排版顺序
添加 a 的方案类似于一种 Hack 技巧,而 200e 可以理解为就是专门解决这种场景而诞生的特殊字符。
好,看看改造后的代码:
<div class="g-add-letter"> <span>13993199751_18037893546_4477657</span> </div>
.g-add-letter { overflow: hidden; text-overflow: ellipsis; direction: rtl; white-space: nowrap; span::before { content: "200e"; opacity: 0; font-size: 0; } }
效果如下:

这样,我们算是比较完美的解决了这个问题。
方案四:通过 <bdi> 标签
那么,上述的方案已经是最佳方案了吗?或者说,还有没有不需要添加伪元素的方式?
在查找解法的过程中,还发现了一个非常有意思的标签 -- <bdi>。
<bdi>:是一个 HTML 标签,表示“双向的隔离器”(Bidirectional Isolation)。它是一个比较新的标签,主要用于解决混合显示多个语言文本时的排版问题。
在多语言文本中,由于不同语言之间的书写方向和文本组织方式可能有所不同,如果直接拼合在一起显示,容易导致排版混乱,甚至出现不合法的语言混排现象。而 <bdi> 标签则提供了一种简单的解决方案,可以隔离不同的语言文本,确保它们按照正确的顺序呈现,并避免混乱的语言混排现象。
具体来说,<bdi> 标签可以将一段文本从周围文本隔离开来,创建一个独立的文本环境,使得文本能够按照正确的书写方向呈现。在使用该标签时,可以使用 dir 属性来指定文本的书写方向,可以是从左到右(dir="ltr")或者从右到左(dir="rtl")等。
综上所述,<bdi> 标签的作用是提供一种简单的解决方案来排版混合显示多个语言文本,通过隔离不同的语言文本,确保它们按照正确的顺序呈现,并避免混乱的语言混排现象。
因此,利用 <bdi> 标签,我们可以再进一步省略掉伪元素的部分:
<div class="g-bdi"> <bdi dir="ltr">13993199751_18037893546_4477657</bdi> </div>
.g-bdi { overflow: hidden; text-overflow: ellipsis; direction: rtl; white-space: nowrap; }
此种方案就比较纯粹,回归了最初的代码,只是多了一层 <bdi> 并且设置了其内部语言排版方向。
最终,结果如下:

上述四种方案的完整代码,你也可以戳这里:CodePen Demo -- 多种方式解决下划线数字的头部溢出省略打点排版问题
总结一下
本文,我们介绍了一种在头部省略溢出的情境下,对于形如 11111_22222_33333_44444 这种用下划线连接的文本,处理的方式会被对待成 11111 22222 33333 44444 一样的情况,导致了最终排版结果与我们的预期不符。
为了解决这种问题,我们介绍了 4 种不同的解决方案:
- 方案一:两次
direction反转 - 方案二:通过伪元素添加字母,破坏其纯数字的性质
- 方案三:通过
200eLRM 标记位 - 方案四:通过
<bdi>标签
上述 4 个方案的思维与处理方式各有优劣。围绕多语言排版涉及了不同的知识,从一个很小的需求中,能够窥探到其中复杂的逻辑。是一个很好的业务实操案例。
本文转载于:
https://juejin.cn/post/7226540105698197563
如果对您有所帮助,欢迎您点个关注,我会定时更新技术文档,大家一起讨论学习,一起进步。





