- A+
目录
一、grep查找文件内容
二、sort排序
三、uniq统计压缩重复
四、tr替换压缩
五、cut截断
六.sqlit拆分
七.paste合并
八.eval
一、grep(匹配文件内容)
grep [选项]… 查找条件 目标文件
-m 匹配次数
-v 除什么以外
-i 忽略大小写
-n 显示匹配行号
-c 统计行号
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A 后几行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
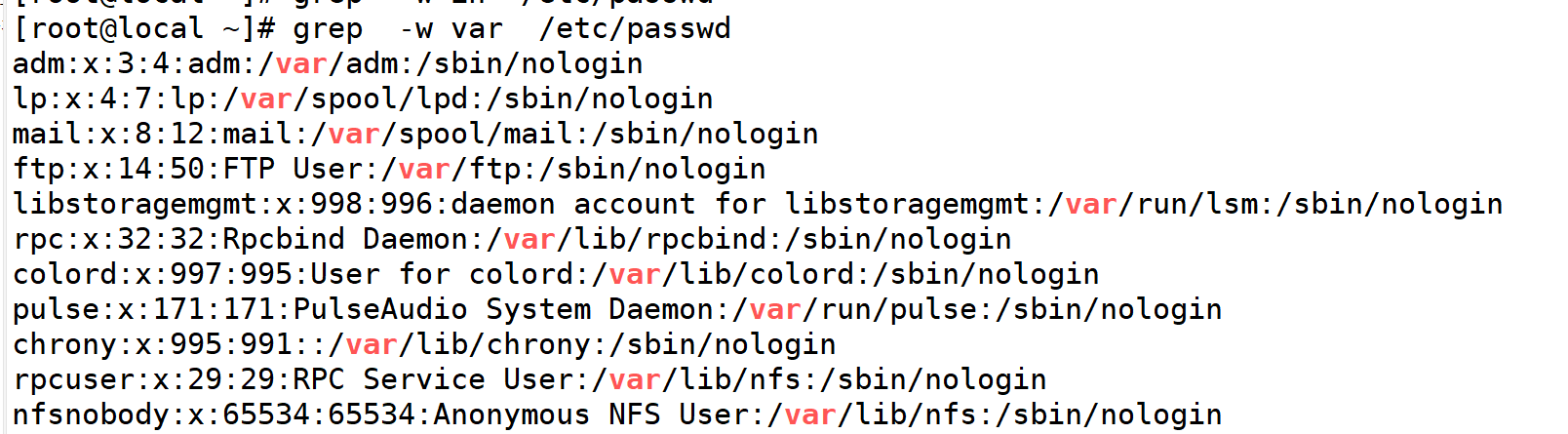
-w 匹配整个单词
-E 使用ERE,相当于egrep,使用扩展正则
-F 不支持正则表达式
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接
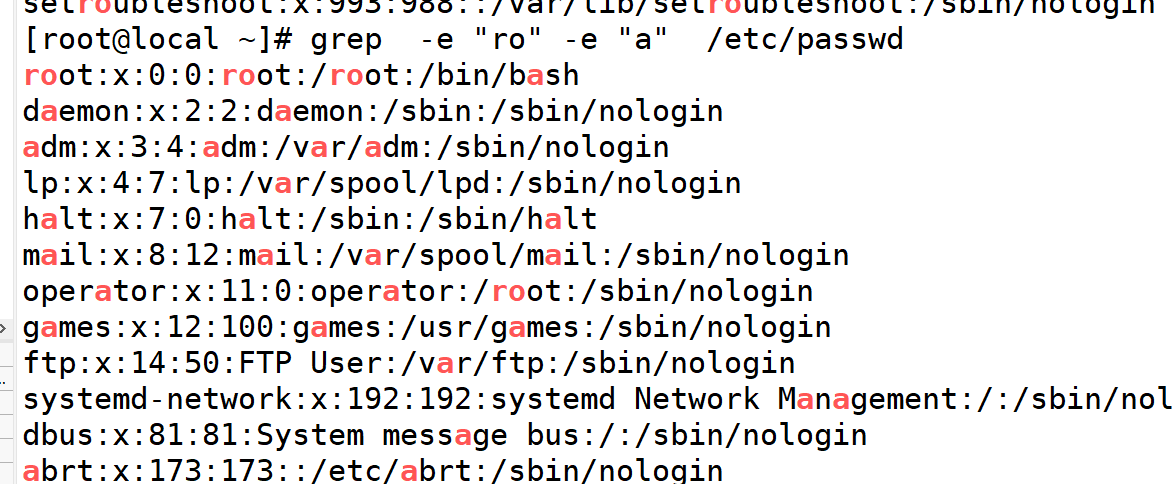
1.显示含a的两行在passwd中

2.显示除a以外两行

3.忽略大小写

4.显示匹配内容的行号

5.统计匹配到含a的行数
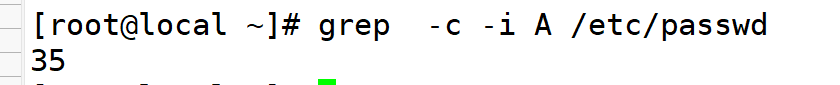
6.仅显示匹配内容

7.静默模式,无事发生
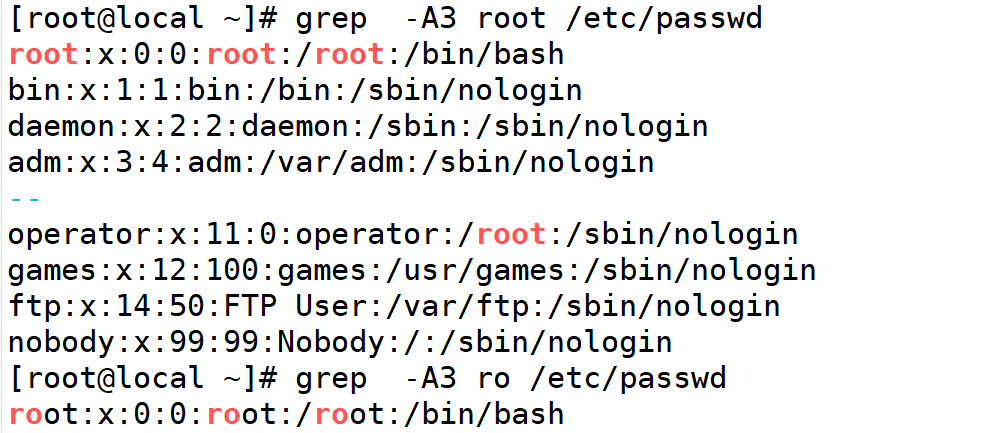
8.A后几行显示

9.B前几行显示
10.-e多个匹配条件
11.w匹配整个字符
12.f两个文件相同地方

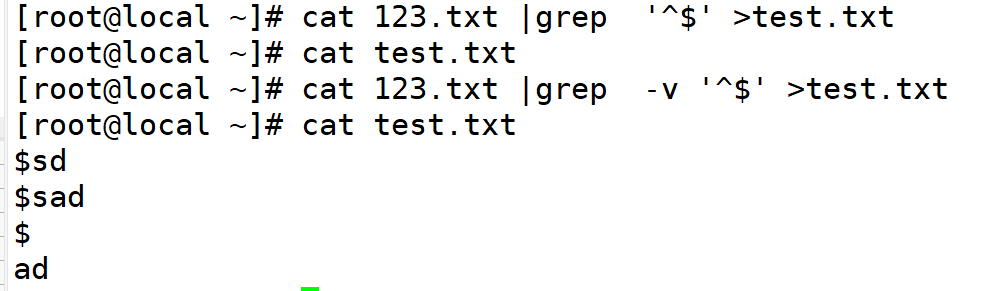
13^$非空行
二、sort
sort命令以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
语法格式:
sort 选项 参数
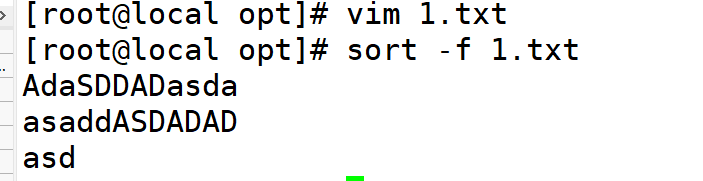
-f:忽略大小写,默认会大写字母排在前面
-b:忽略每行前面的空格
-n:按照数字进行排序
-r:反向排序
-u:等同uniq,表示相同的数据仅显示一行,去重
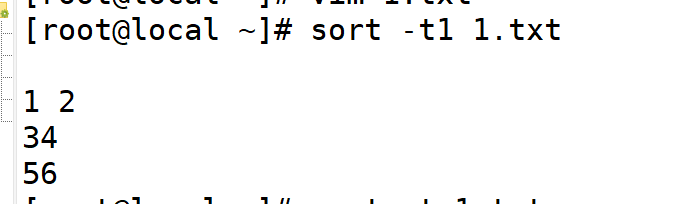
-t:指定字段分隔符,默认使用tab键分隔
-k:指定排序字段
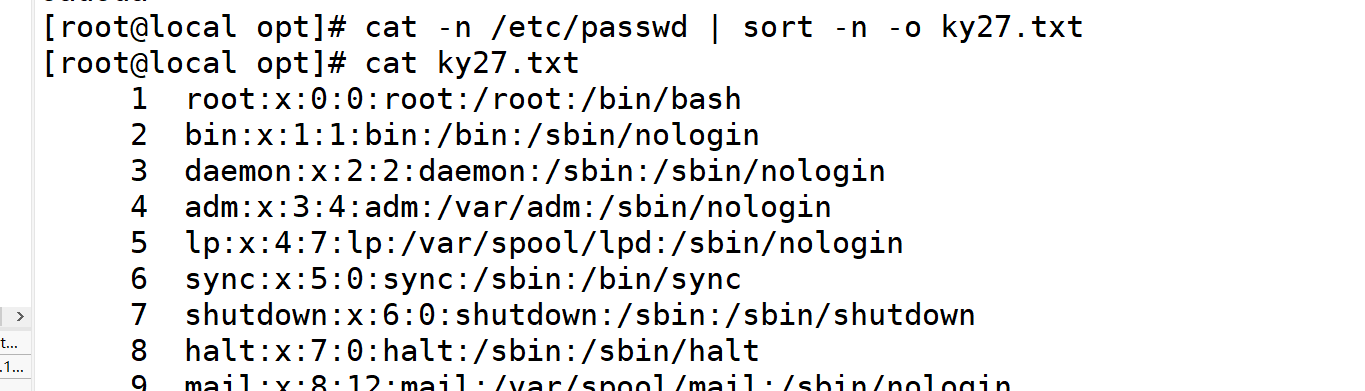
-o <输出文件>:将排序后的结果转存至指定文件
1.-f忽略大小写(以行为一个整体,以第一个字母先对比)
2.-b忽略空格

3.-n按数字大小排序
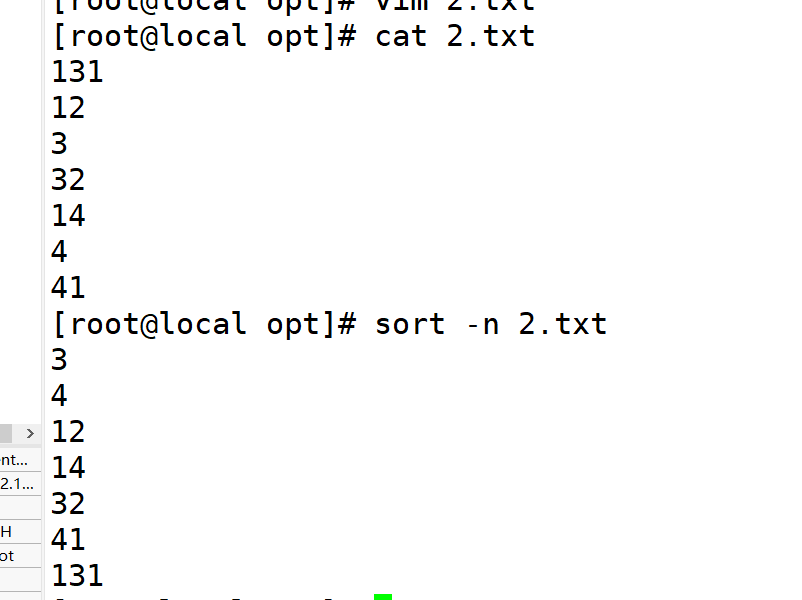
4.-r反向排序

5.u去重

6.t 使用分隔符分隔
7.k指定排序字段

8.o排序后存放指定文件
三、uniq(去重)
-c 统计连续重复的行的次数,并且合并重复的行
-u 显示仅出现一次的行(包括不连续的重复行)
-d 仅显示重复出现的行(必须是连续的重复行)
1.-c统计重复行

2.-u显示仅出现一次的行

3.-d仅出现重复的行

四、tr
常用于对来自标准输入的字符进行替换、压缩和删除
-c:保留字符集1的字符,其他的字符(包括换行符n)用字符集2替换
-d:删除所有属于字符集1的字符
-s:将重复出现的字符串压缩为一个字符串,用字符集2 替换 字符集1
-t:字符集2 替换 字符集1,不加也行
1.显示1的位置用2替换

2.删除指定位置字符

3.-s重复压缩,用位置2字符替换字符1
将第三个位置替换为1并压缩重复字符

4.t替换

五、cut
快速裁剪命令
d 指定分隔符(默认分隔符为Tab)
-f 按字段进行截取。指定第n个字段;
-b 以字节为单位进行截取
-c 以字符为单位进行截取
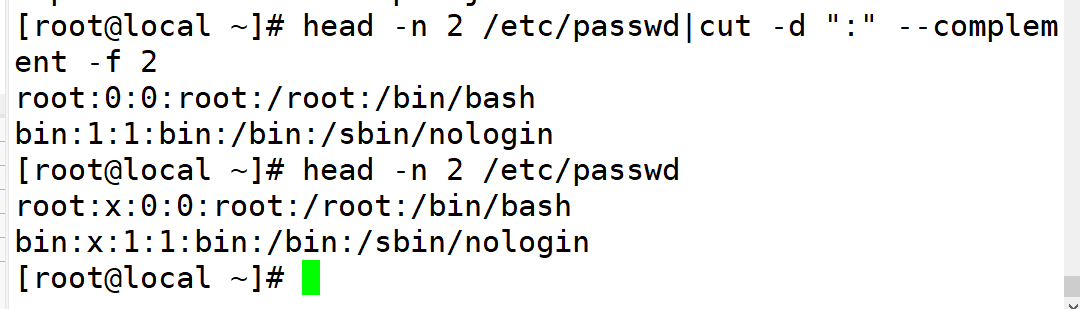
–complement 排除所指定的字段
–output-delimiter 更改输出内容的分隔符
1.d指定分割
截取以:为分割2位置到3位置数据

2.指定已":"作为分隔符,但是删除了第二个字段进行输出
3.将分隔符转换为@,进行输出

六、split
split命令用于在Linux下将大文件拆分为若干小文件。
-l 指定行数
-b 指定文件的大小
1.-l指定拆分为2行

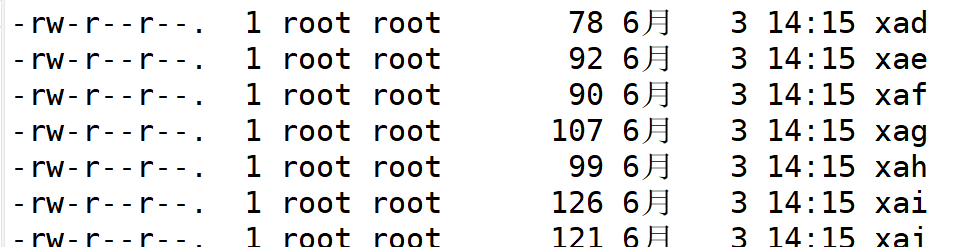

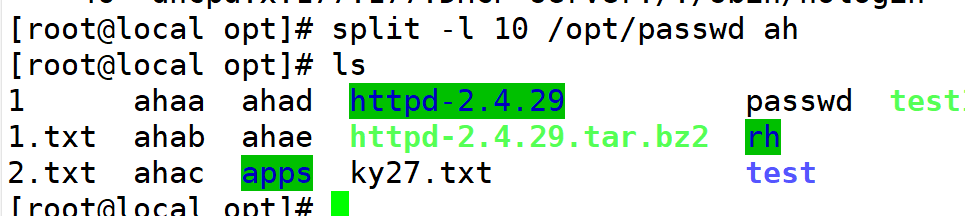
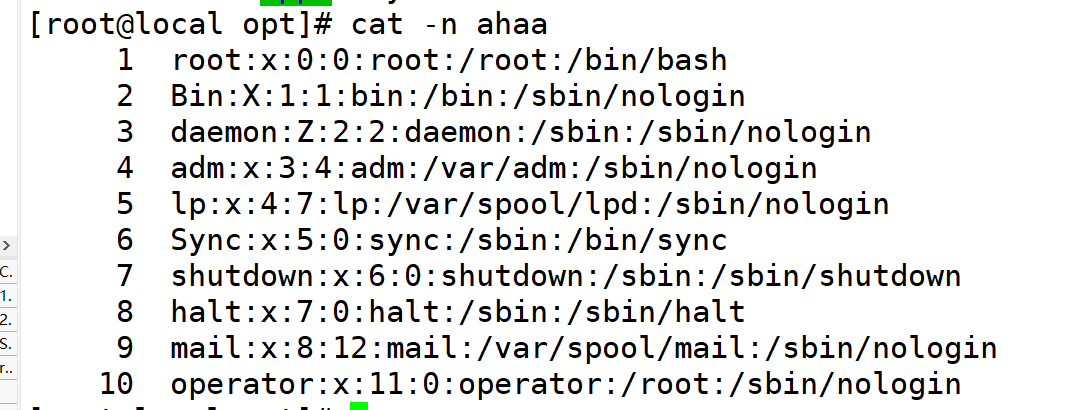
2.指定差分后文件名
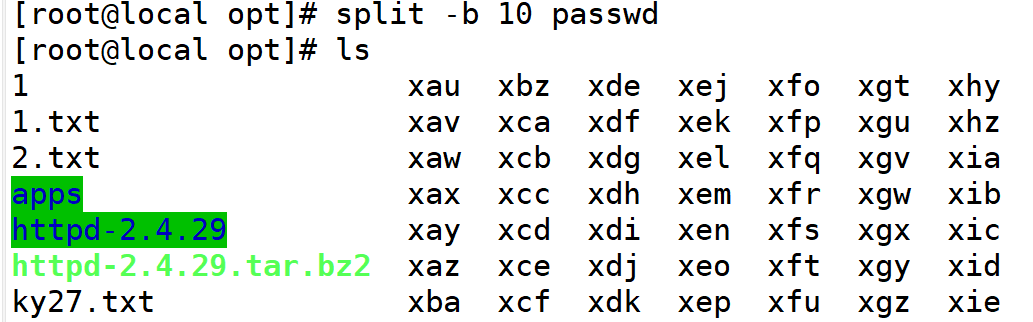
3.-b指定大小
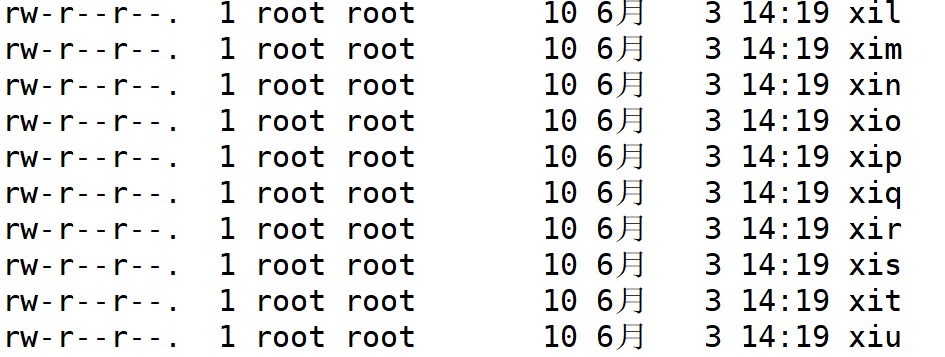
七、paste
按照字段来进行文件的合并
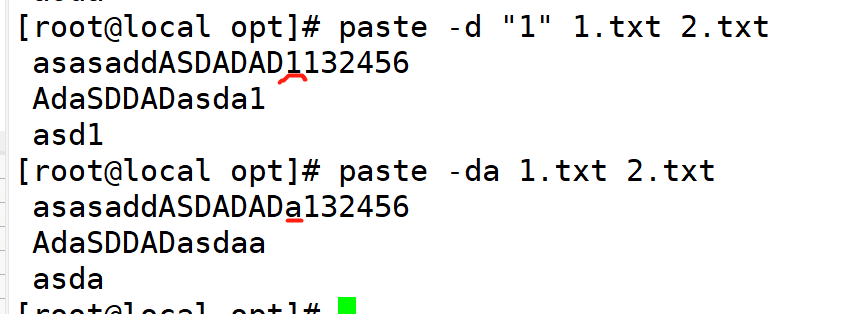
-d 用于指定文件的分隔符(默认情况下为制表符"n")
-s 将列和行的内容进行互相交换
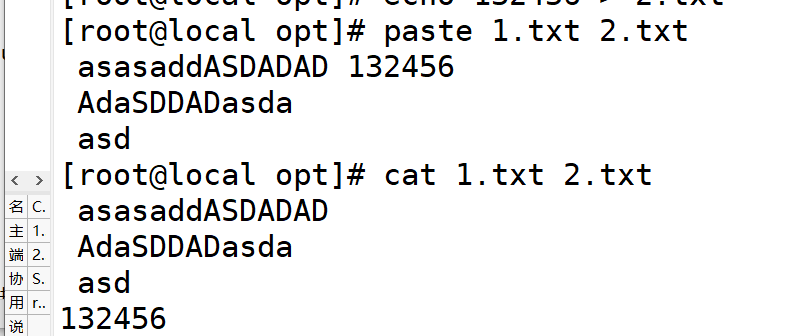
1.paste
paste是左右合并,cat是上下合并
2.-d指定连接处
3.s行和列互换

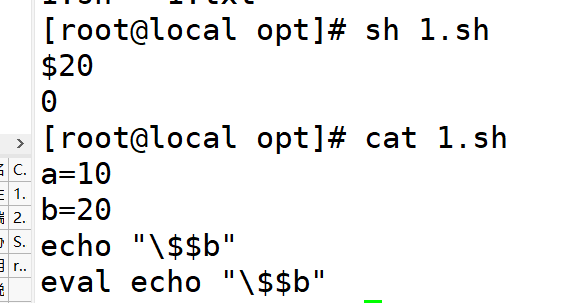
八、eval
命令字前加上eval,shell会在执行命令之前扫描它两次,