- A+
文件系统
文件是面向OS和面向使用者而言的,对于人来说,音乐,图片,文档,游戏,软件,邮件,等记录信息的载体都被操作系统统称为文件,而存储在HDD(机械硬盘)和SSD(固态硬盘)里.因此文件是一种实体的抽象,而之所以文件需要文件名,是因为不同的文件需要进行相对应的区分,也就是文件名,而其中的展开就是文件内容,本质上也就是一堆字符序列,而文件名常常是不通的,因此如何去管理这些文件名,就需要一个对应的目录,就好比教务系统管理我们的信息一样,因此这些不同的文件共同组成了目录,而每个目录其中的最小单位也就是每一个目录项,他记载着每个文件地址或编号.
而我们使用者如何去进行基础的读写创建删除文件的操作,则需要文件系统的支持,而使用者与文件之间的这层薄膜就是虚拟文件系统,用来帮我们实现接口去调用相应的操作执行我们的行为.
而对上层开发者及使用者来说:虚拟文件系统就是对应的的执行接口.
那么对下层的存储设备来说:文件系统就是以某种形式在存储设备上保存和维护这这些文件的数据,而为了更好地统一使用虚拟文件系统组织和管理文件系统,将存储设备抽象为块设备,因此可以将存储设备上的逻辑地址划分为固定大小的块,这一点的设计和内存的设计划分有着相似之处.
- 通常来说,块是设备读写的最小单元,通常来说大小是512字节或者4KB.每个存储块都会有一个相应的地址,被称为
块号
而如果想查看自己电脑的块总数和相关的信息可以使用命令查看
- 这里以WIN10为例:以管理员模式允许cmd输入:
fsinfo ntfsinfo C: 输出结果显示:
NTFS Volume Serial Number : 0xacfc89e7fc89abe0 NTFS Version : 3.1 LFS Version : 2.0 Total Sectors : 791,466,638 (377.4 GB) Total Clusters : 98,933,329 (377.4 GB) Free Clusters : 51,237,504 (195.5 GB) Total Reserved Clusters : 1,339,199 ( 5.1 GB) Reserved For Storage Reserve : 1,328,585 ( 5.1 GB) Bytes Per Sector : 512 Bytes Per Physical Sector : 512 Bytes Per Cluster : 4096 Bytes Per FileRecord Segment : 1024 Clusters Per FileRecord Segment : 0 Mft Valid Data Length : 1.12 GB Mft Start Lcn : 0x00000000000c0000 Mft2 Start Lcn : 0x0000000000000002 Mft Zone Start : 0x0000000002f6e180 Mft Zone End : 0x0000000002f76aa0 MFT Zone Size : 137.13 MB Max Device Trim Extent Count : 256 Max Device Trim Byte Count : 0xffffffff Max Volume Trim Extent Count : 62 Max Volume Trim Byte Count : 0x40000000 Resource Manager Identifier : B20E52C3-85D6-11EA-A277-9CEBE83A74F8 - Bytes Per Cluster:4096 字节,这表示每个块的大小为 4KB。
- Total Clusters:98,933,329,表示总的块数。
意味着我的系统块的大小是4KB,同时需要注意,即使你创建的一个文件没有超过块的大小,依然会分配一个块给你,这里的分配其实和内存页的分配类似,都会导致空间利用率不确定,也就是碎片的问题,不过磁盘的碎片是可以接受的,但同样不宜将块的大小定大.
1.基于inode的文件系统
前面对文件系统中每一个存储块的大小定义为4KB去存放这些文件,可是按照常理来说,很多文件的大小往往都不止4KB,比如一些图片,音频等,很容易都是MB,因此就需要几千个4KB的块去存,而像大电影那种GB的文件,就需要几十万甚至几百万个4KB的块,而这些块都需要与之对应的块号,也就是类似地址一样的东西来表示这些块,也就是去表示这些文件,因此记录这些块号也需要开辟额外的内存空间,所以文件系统是如何解决这一庞大的开销呢?
为了去记录这些块号,因此提出了一种磁盘结构:inode:index node的简写,即索引节点,他记录了每一个文件所对应的块的块号,即存储索引.

而前面我们也顾及过一个问题,就是一个文件所占用的磁盘空间可能不止一个块,即多个块,这意味着需要多个indoe去记录.

意味着indoe这种磁盘结构需要额外分配来记录存储索引,以免遇到更大的数据类型,需要更多的块,因此如果通过预留的方式则可能会导致资源的浪费.因此,一种类似内存空间页表的设计思想利用到了文件系统到中.
也就是采用多级,即分级的方法是来组织和存储块号
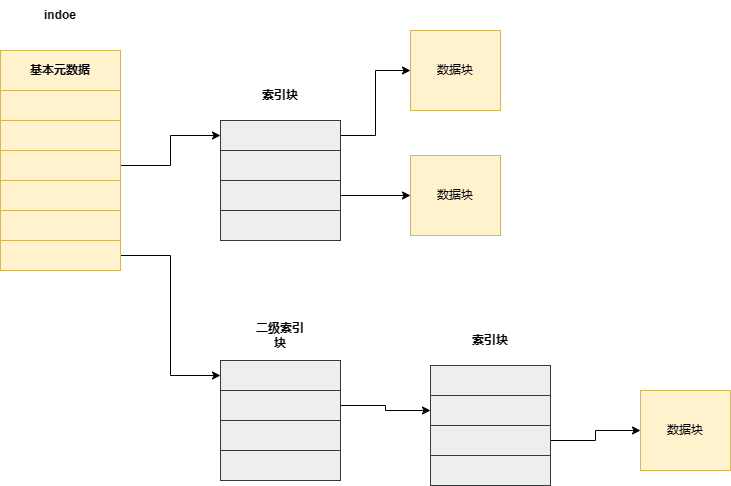
这样最大的优点就是高级的索引块是固定的,而不用在受限于数据的大小,即通过间接索引块去记录文件对应的块号,自由地动态分配,且这种多级索引块的方式提供了更大的寻址范围,如果只是简简单单的一级索引块,假设字长为8位的情况下,可表示的范围也就只有28 ,当然,实际上都是8字节,甚至几百字节的情况下,不过多级索引的这种方式,无疑让块号可表示的范围更长了,也就类似偏移地址的那种感觉.毕竟硬盘其实非常的大,相比于内存,其实这种块号需要的表示范围还是蛮大的,仅仅靠着一张inode去存储这个块号,明显力不从心,而且这种多级的方式也更加利于管理.
- 在图示中,我们还在inode中写入了元数据这一项,其意义是处了存储块号之外,还有着其他的数据信息:
- 文件类型:指示文件是普通文件、目录、符号链接等类型。
- 文件权限:指定文件的访问权限,如读、写、执行权限。
- 文件所有者:记录文件的所有者用户和用户组。
- 文件大小:指示文件的大小,以字节为单位。
- 创建时间和修改时间:记录文件的创建时间和最后修改时间。
- 文件链接计数:指示有多少个目录项指向该inode,用于维护文件的引用计数。
- 数据块指针:用于指向文件数据所在的数据块,包括直接块指针、间接块指针和二次间接块指针等。
2.文件名与目录
以上基于inode的文件系统的实现其面向的对象是OS内部本身,即用户并不能通过块号或者说去查找块号去定位文件的位置,为了方便用户,也就是通过每个inode号去和文件名映射一种对应关系,就跟网络中的域名和IP一样,人类不方便去记忆IP地址和inode号一样,他们选择了一种名字的方式去寻找和查找一样.因此这些被映射的文件名就会被放在目录之中.
本着Linux的一切皆文件的想法,目录本身也是一种特殊类型的文件,记录着文件名和inode号的映射,同样目录也存在着多级也就是子目录的情况下,因此这种结构就如同我们的文件夹一样,可以去通过递归的形式,来组织的管理文件系统中的文件.而我们目录里存放的这种结构则是目录项,每个目录下都代表着文件信息,比如文件名和对应的inode号等.
例如:在Linux下可以使用tree命令去查看目录结构:
[root@iZf8ze1gd2ic6tea2rrf8dZ wwwroot]# tree . └── default 1 directory, 0 files wwwroot下仅一个default文件夹,因此输出如上
如果Linux中没有tree命令,则执行:sudo yum install tree(CentOS);
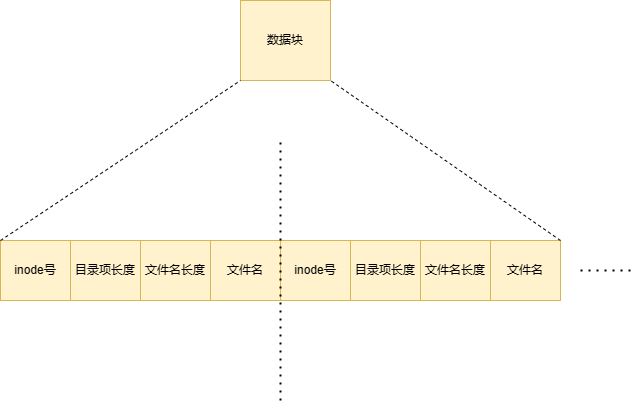
因此文件名与inode号之间这种映射被存放在目录项里,而目录则管理着这些目录
在大多数文件系统中,目录被存储在特定的数据块中,这些数据块通常称为目录数据块或目录文件块。每个目录数据块都包含了一系列的目录项,每个目录项对应一个文件或目录,并记录了其名称和对应的Inode号。
因此,展开如图所示:
3.硬链接与软链接
硬链接
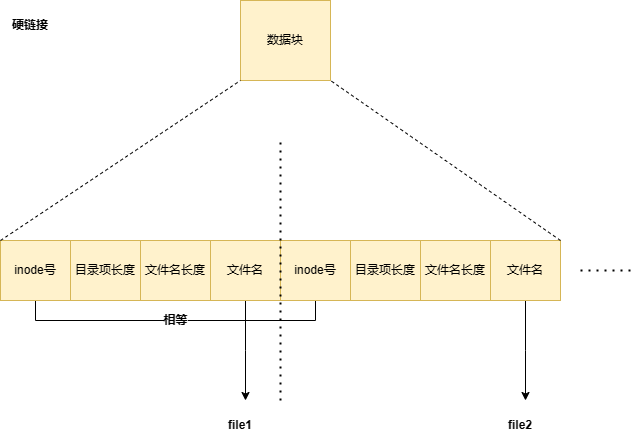
由于indoe是一个非负整数,他可以表示唯一的文件名,这意味着通过inode一定能找到一个文件,但文件名并不是存放在索引块或者inode块中的元数据,这意味着文件名其实更像是一种标识,因此可以出现多个文件名保持同一个inode号的情况出现.
例如:通过ln file1.txt file2.txt创造一个文件两个名字的,也就意味着有两个目录项,他们两的inode号是相同的.
$ ln file1.txt file2.txt 我们可以使用 ls -i 命令查看文件的Inode号:
[root@iZf8ze1gd2ic6tea2rrf8dZ www]# ls -i file1 file2 1325159 file1 1325159 file2 而为了方便记录有多少个目录项指向inode,因此在元数据中保存着这个文件最原始的一些信息,包括有多个链接指向他,是不是很智能.
软链接(符号链接)
软链接是一种文件类型,他并不会指向inode号,而是通过文件的路径去指向文件,其实本质是一个文件,而文件里面存放的是路径,因此他也有元数据和对应的目录项
例如:通过ln -s target slink来为target文件创造一个软链接slink
[root@iZf8ze1gd2ic6tea2rrf8dZ www]# ln -s target slink 我们可以使用ls -l命令查看文件的软链接:
[root@iZf8ze1gd2ic6tea2rrf8dZ www]# ls -l slink lrwxrwxrwx 1 root root 6 Jun 1 15:37 slink -> target 图解的形式如下:

其实这种设计思想的落脚实现在很多地方都有所体现.比如JVM中字节码文件中的符号链接,本质上就是类的全限定名,也就是相对路径,这种路径最后被转换成实际的物理内存,也就是直接链接
4.存储布局
为什么要去理解存储布局,早在内存管理的部分,其实我们就参考过这种设计思想,将内存按段分成相应的数据段,代码段,栈段,BSS段等,这种段的划分其实就已经为内存划分了区域,虽然面向的对象依然是OS.同样硬盘也作为一种存储设备,区域的划分可以更加地有效地去管理存储设备上的文件和数据.
因此,一个存储设备中的内存区域可以大致被划分为超级块,块分配信息,inode分配信息,inode表,文件数据块等区域.每当我们进行格式化操作的时候,文件系统就会去初始化每个区域的大小,布局等信息
- 超级块:这个结构非常的重要,他记录着整个文件系统的全局元数据,比如文件系统类型:魔数,还有一些版本,文件系统管理空间的大小,因此超级块实际记录的是
文件系统的相关信息,用来描述文件系统的属性和结构的 - 块分配信息:则是用来记录每个块的使用情况的,这种结构使用位图则可以大大节省内存,和内存的跟踪类似,利用
位图则可知道每一个块的使用情况,1表示已经使用,0则表示无使用. - inode分配信息:跟块分配信息其实差不多,只不过特定与inode(索引节点),因为是固定分配好的,所以存在有一些用了,有一些没用的情况
- inode表:inode表则是一开始提到的基于inode的文件系统中的索引节点,inode分配信息也就是根据inode表里来的,因此一般情况下,由文件系统已经初始化定好了大小.





