- A+
作者: zyl910
一、引言
前面的几篇文章里,介绍了 C# 编写向量算法的各种办法。
虽然也做了一些基准测试,初步验证了向量算法的效率高。但是由于 CPU睿频、其他进程抢占CPU资源 等原因,基准测试的结果不太稳定,有时难以评价哪种向量算法的效率更高。
这时便需要检查一下程序运行时的汇编代码,从而能进行更精准的分析。
例如汇编代码里的这些情况, 会影响程序的性能:
- 以函数调用的方式来使用内在函数。内在函数的运行时间,一般仅是个位数的时钟周期;而函数调用因存在参数压栈、在栈中保存寄存器 等操作,会花费数十个时钟周期或更长的时间。而以Release方式运行程序时,正常情况下会以内联(inline)的方式使用内在函数,即直接使用CPU指令,而不是函数调用。
- 对于变量访问存在多余的读写内存操作,未充分利用寄存器(Register)。当以内联的方式使用内在函数时,是使用CPU内部的寄存器来传递参数的。寄存器与CPU同频工作,速度比内存快好几个数量级。正常情况下,仅当寄存器数量不够用时,才需要使用栈内存来暂存中间变量,这会拖慢速度。有时向量版代码编写的不够好,就容易遇到“超过了寄存器数量”问题。检查汇编代码,可以发现这种问题。
- 存在多余的越界检查等安全检查。
……
C# 程序编译时,只是编译为IL(Intermediate Language,中间语言)的代码。
随后在真机上运行时,通过JIT(just in time,即时编译)技术,将IL再编译为本机代码(Native Code),从而使程序运行。
使用 ildasm、ILSpy 等工具进行反编译时,只能看到IL代码,而不是运行时的本机汇编代码。
若想查看运行时的本机汇编代码,得用其他办法。
二、办法说明
2.1 基本办法
若想查看运行时汇编代码,最简单的办法是使用Visual Studio的“Disassembly”功能。
具体办法是:在Visual Studio里打开程序的解决方案,并设置断点。按“F5”运行程序直至遇到断点,然后点击菜单栏里的“DEBUG”(调试)->“Windows”(窗口)->“Disassembly”(反汇编)。
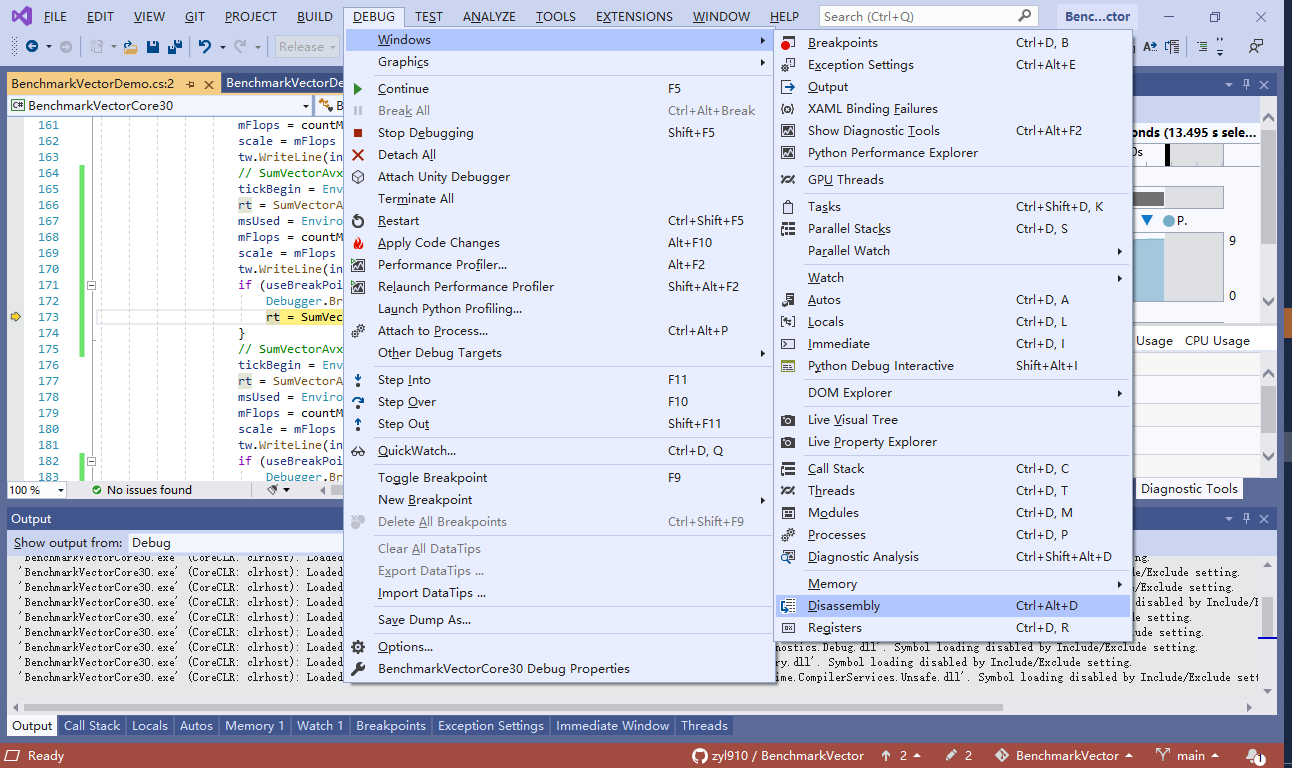
在“Disassembly”菜单项的旁边,还有一个“Registers”(寄存器)菜单项,可以用来查看CPU的各个寄存器。这对调试汇编代码很有用。

对于 C# 程序,目前Visual Studio还不支持“查看AVX寄存器信息”,会发现它的数据为灰色字体。仅在运行 C/C++ 程序时,可以用该窗口查看AVX的寄存器。
C# 仅是看不了AVX寄存器而已,“Registers”窗口仍然能查看 SSE寄存器、通用寄存器 等内容。
2.2 Release程序如何设置断点
在Visual Studio里,可通过“在某行代码的左侧点击鼠标左键”的办法,设置断点。
在Debug模式下运行时,该办法一般是有效的。而在Release模式下运行时,大多数时候会发现断点没生效。
这可能是因为Release模式下进行了很多编译优化,导致断点失效了。
初步发现仅Visual Studio 2022在调试 .NET 7.0程序时,断点在Release模式运行时有效。而低版本的,一般没成功。
所以对于Release模式下运行的程序,我们需要用另一种办法来设置断点。
办法就是使用 Debugger.Break 来主动触发断点. 它的名称空间是 System.Diagnostics.
using System.Diagnostics; Debugger.Break(); // ... 2.3 如何避免“分层编译”的误导
设置好断点后,按“F5”运行Release模式的程序。随后会发现一个情况——怎么内在函数全部是函数调用方式运行的?这种方式的效率很低啊。
别慌,这是 .NET的“分层编译”技术所导致的。
为了提高程序的启动速度,.NET推出了“分层编译”技术。即在程序启动时,几乎不进行编译优化,而是以最简单、最快的办法进行即时编译(JIT),使程序能在很短的时间内启动。随后JIT会监控程序的热点代码, 对热点代码进行 慢速的、复杂的二次编译,此时才会使用多种编译优化手段。例如改为内联使用内在函数,而不是函数调用。
为了查看编译优化后的汇编代码,需要在热点代码运行后才触发断点。
此时有一个技巧——先按原来的办法对函数进行基准测试,随后在基准测试代码的后面,插入“Debugger.Break”,并再调用一次测试函数。
因为在对函数进行基准测试时,会使该函数变为热点代码,触发编译优化。基准测试完毕遇到“Debugger.Break”时会暂停执行,便能打开“Disassembly”窗口。然后单步运行,从而查看汇编代码。
为了不影响程序发布, 可以建立useBreakPoint变量。随后根据该变量写分支语句,写好断点时相关代码。
修改后的代码如下。
bool useBreakPoint = true; // SumVectorAvxRef. tickBegin = Environment.TickCount; rt = SumVectorAvxRef(src, count, loops); msUsed = Environment.TickCount - tickBegin; mFlops = countMFlops * 1000 / msUsed; scale = mFlops / mFlopsBase; tw.WriteLine(indent + string.Format("SumVectorAvxRef:t{0}t# msUsed={1}, MFLOPS/s={2}, scale={3}", rt, msUsed, mFlops, scale)); if (useBreakPoint) { Debugger.Break(); rt = SumVectorAvxRef(src, count, 1); } 2.4 实际演练(汇编调试)
2.4.1 进入断点
按照上面办法修改好程序,并将程序切换为Release方式,然后按“F5”(或工具栏的运行按钮)运行程序。
程序运行一段时间后,断点触发了,Visual Studio的C#源码窗口,会停在“Debugger.Break”的下一行 C# 代码上。如下图。
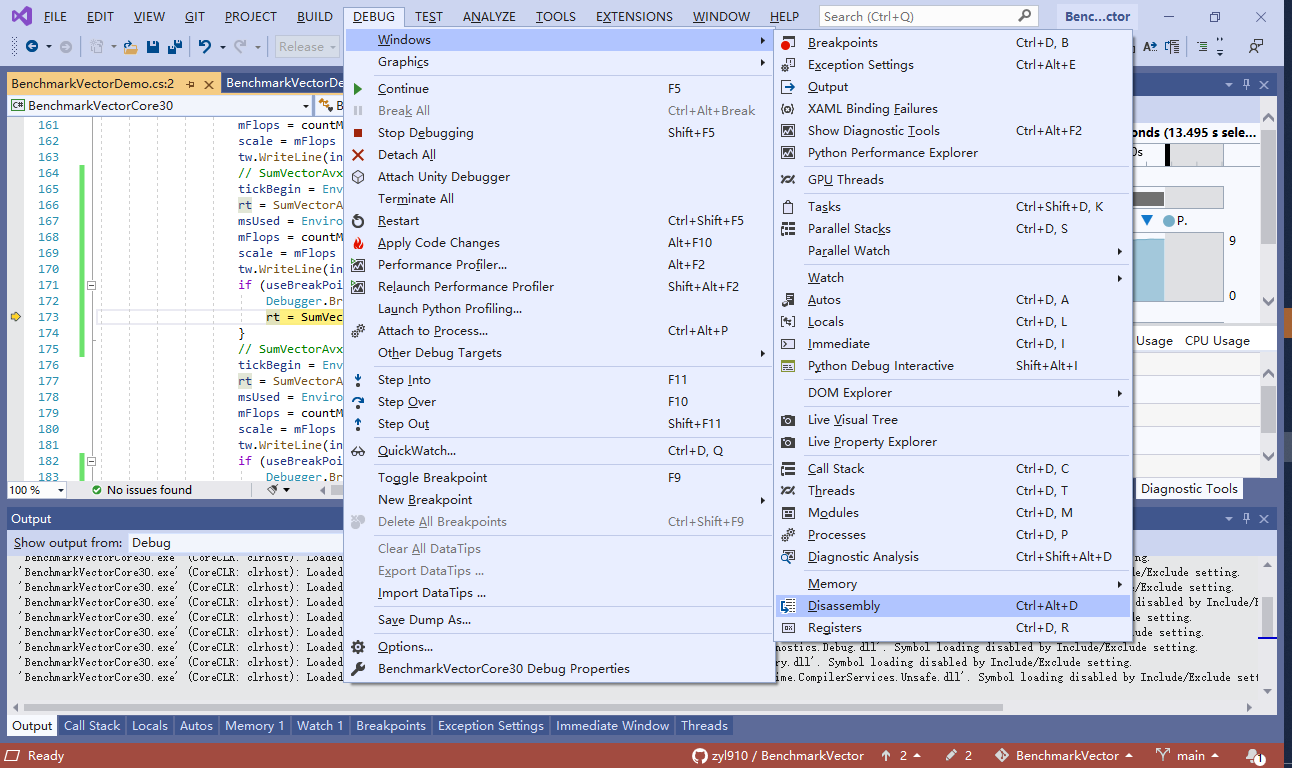
此时点击点击菜单栏里的“DEBUG”(调试)->“Windows”(窗口)->“Disassembly”(反汇编)。
随即便打开了“Disassembly”窗口,能查看本机的汇编代码。例如这台电脑是X86架构,于是汇编代码是X86的。如下图。
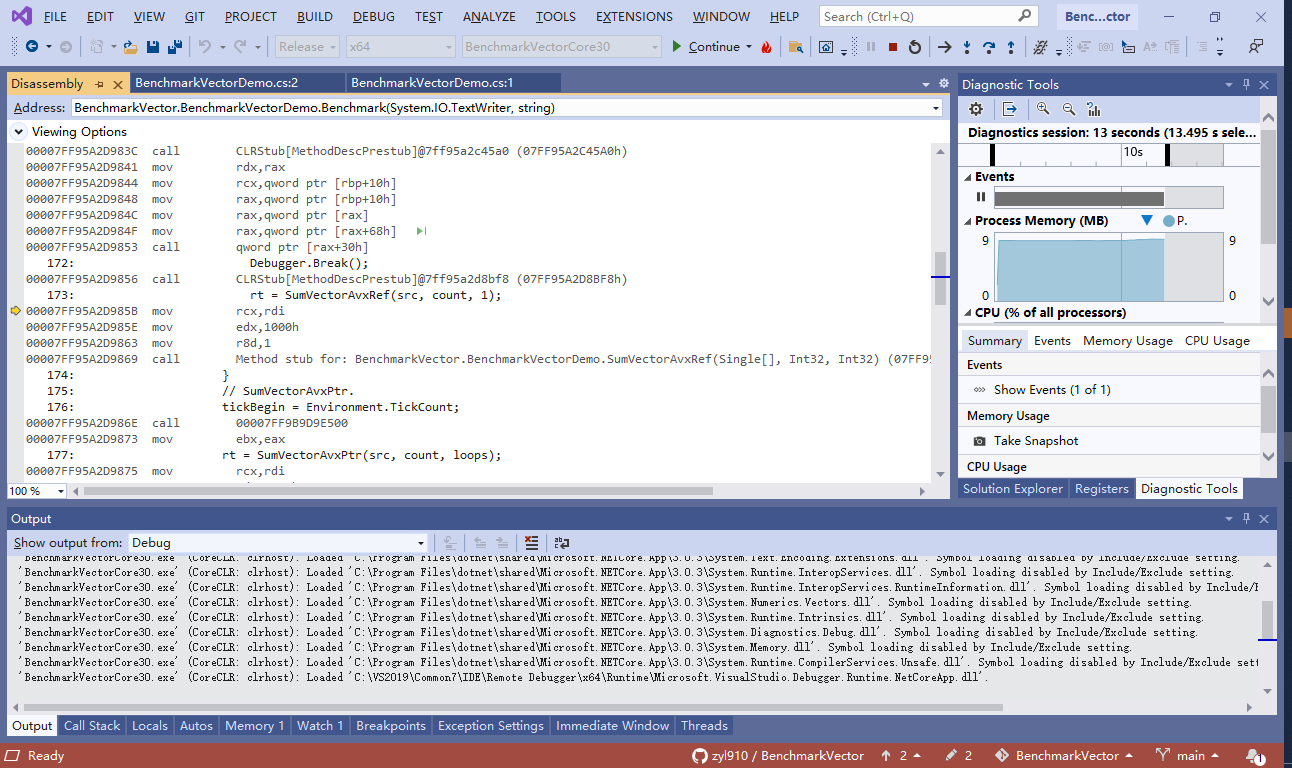
“Disassembly”窗口里不仅展示了汇编代码,且还将对应的 C# 代码也一起展示。注意有些时候因为编译优化等原因,对应的 C# 代码没能一起展示。此次阅读汇编代码会稍微吃力一些,需人工翻阅 C# 代码, 思考对照关系.
格式说明——
- C# 代码。格式为
前导空格 + C#行号 + 冒号(:) + 多个空格 + C#代码. - 汇编代码。格式为
十六进制地址 + 多个空格 + 汇编指令.
173: rt = SumVectorAvxRef(src, count, 1); 00007FF95A68985B mov rcx,rdi 00007FF95A68985E mov edx,1000h 00007FF95A689863 mov r8d,1 00007FF95A689869 call Method stub for: BenchmarkVector.BenchmarkVectorDemo.SumVectorAvxRef(Single[], Int32, Int32) (07FF95A680FB0h) 这里的3个“mov”指令,是使用寄存器传递参数。最后用“call”指令,调用测试函数(SumVectorAvxRef).
可参考C#代码中函数的参数列表, 弄清楚这3个“mov”指令所对应的参数。
mov rcx,rdi。它对应函数的float[] src参数。即float[] src = new float[count];。mov edx,1000h。它对应函数的int count参数。即const int count = 1024*4;。1024*4的结果是4096, 用十六进制表示就是1000h.mov r8d,1。它对应函数的int loops参数。即1。
2.4.2 单步调试
“Disassembly”窗口也支持“F11”单步调试等快捷键。注意此时不再以 “一条C#语句” 为单位, 而是以“一条汇编指令” 为单位。
按3次“F11”,跳过了3个“mov”指令,当前语句是“call”指令。此时再按一次“F11”,便能进入该函数。如下图。
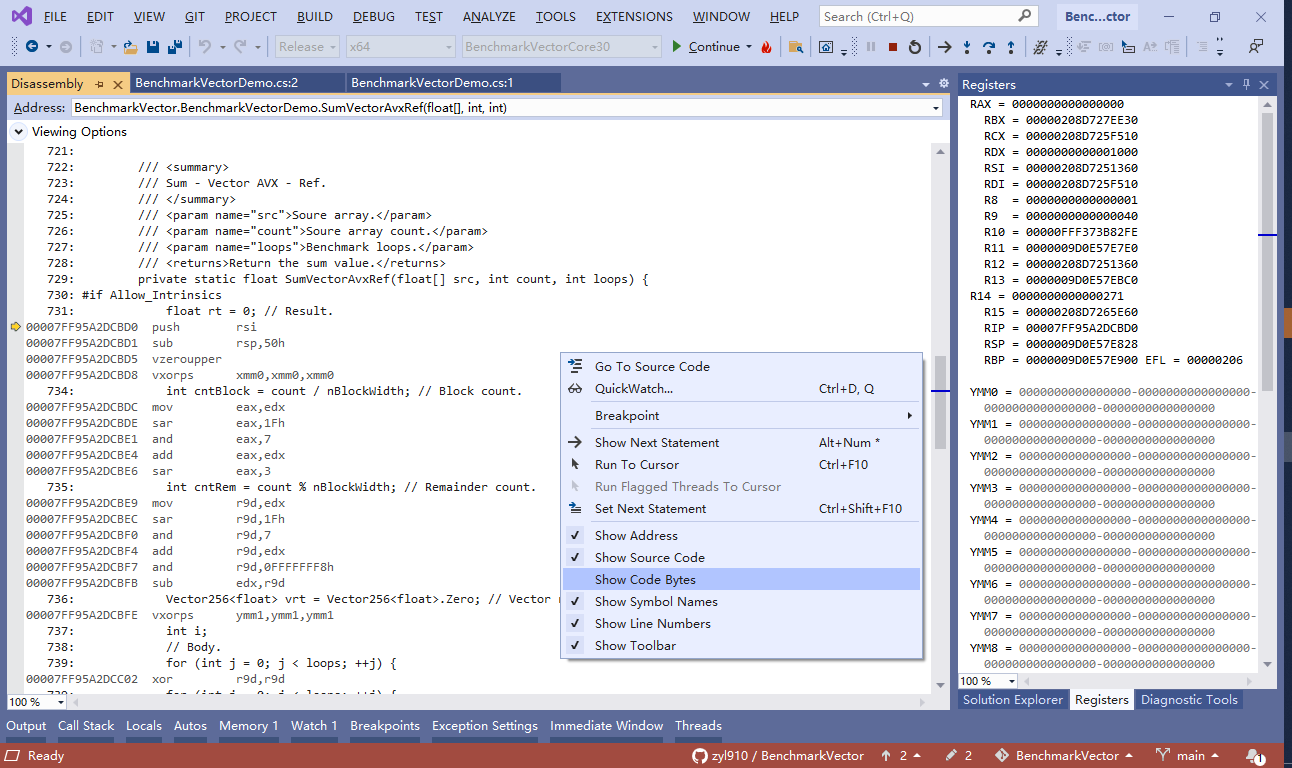
上面的截图里,展示了“Disassembly”窗口的快捷菜单,其中有如下的查看选项。
- Show Address:显示汇编代码的地址。
- Show Source Code:显示 C# 源码。
- Show Code Bytes:显示代码的字节。即显示机器码。
- Show Symbol Names:显示符号名。
- Show Line Numbers:显示 C# 源码的行号。
- Show Toolbar:显示工具栏。即此窗口顶部的“Viewing Options”工具栏。
上述截图里,还展示了“cntBlock”字段是如何计算的,结果会保存到“eax”寄存器。汇编代码摘录如下。
734: int cntBlock = count / nBlockWidth; // Block count. 00007FF95A68CBDC mov eax,edx ; eax = edx; 注意edx是函数的输入参数 `int count`。 00007FF95A68CBDE sar eax,1Fh ; eax >>= 1Fh; “1Fh”是十进制的“31”,这个带符号移位是为了获得edx的符号. 0或正数会得到“0”,负数会得到“-1”(FFFFFFFFh). 00007FF95A68CBE1 and eax,7 ; eax &= 7 00007FF95A68CBE4 add eax,edx ; eax += edx 00007FF95A68CBE6 sar eax,3 ; eax >>= 3; 因为此时 nBlockWidth 为8,可优化为右移3位. 为了便于读者阅读,我在上述汇编代码的后面加了注释,用 ;(分号)隔开。
这一段代码使用了一种常见的编译优化手段——“将除法优化为移位”。且由于是带符号数,有可能为负数,于是在右移前对数据进行了一些转换。
上述截图里,还展示了“vrt”字段是如何清零的,它使用了“ymm1”寄存器。汇编代码摘录如下。
736: Vector256<float> vrt = Vector256<float>.Zero; // Vector result. 00007FF95A68CBFE vxorps ymm1,ymm1,ymm1 ; ymm1 = ymm1^ymm1 = 0; 将同一个数进行“xor”运算, 结果为0, 这便完成了“赋值为0”的工作. 2.4.3 观察主循环的汇编代码
由于程序已经运行到该函数内,于是可以不用进行单步调试了。可直接拖动滚动条,查看主循环的汇编代码。如下图。
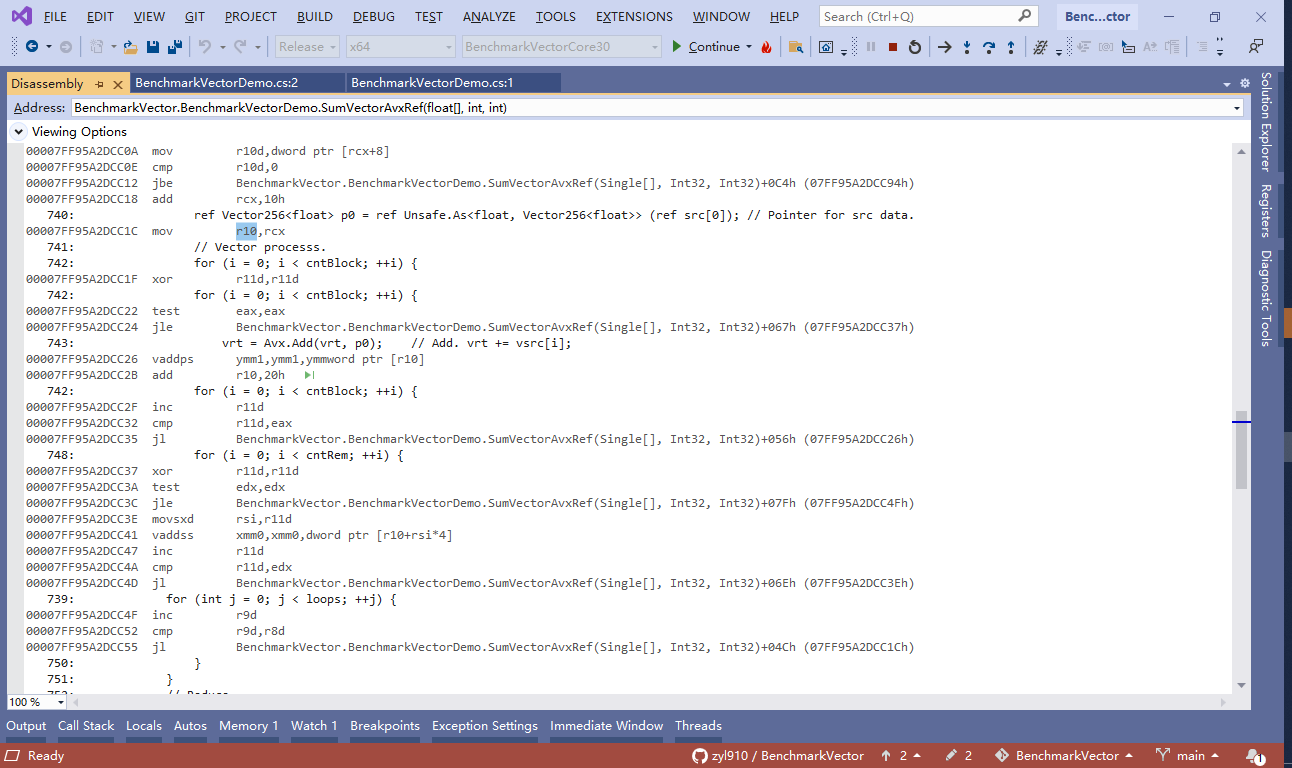
由于有 C# 语句做对照,所以能很快定位关键代码。例如下面这几条汇编语句,是计算“p0”的初始值(数组中首个元素的引用)
00007FF95A68CC18 add rcx,10h ; rcx += 10h 740: ref Vector256<float> p0 = ref Unsafe.As<float, Vector256<float>> (ref src[0]); // Pointer for src data. 00007FF95A68CC1C mov r10,rcx ; r10 = rcx 注意rcx是函数的输入参数 float[] src。加上 10h 后,使rcx改为指向“数组中首个元素的地址”。10h与 .NET内部的数组内存布局有关, 不同的处理器架构, 该值不同。
虽然 Unsafe.As 写起来比较冗长, 但这些冗长内容,只是为了满足 C# 的语法检查,它的本质是“赋值”。于是并不需要调用Unsafe.As 等函数, 仅用1条“mov”指令就行。
接下来可以观察向量处理的关键循环(Vector processs)。汇编代码摘录如下。
741: // Vector processs. 742: for (i = 0; i < cntBlock; ++i) { 00007FF95A68CC1F xor r11d,r11d ; r11d = r11d^r11d = 0; 这是for的“i = 0”部分. 742: for (i = 0; i < cntBlock; ++i) { 00007FF95A68CC22 test eax,eax ; 检查eax(cntBlock)是否小于等于(le)零。若为真,会用下一条语句跳转到“00007FF95A68CC37h”,即循环外. 00007FF95A68CC24 jle BenchmarkVector.BenchmarkVectorDemo.SumVectorAvxRef(Single[], Int32, Int32)+067h (07FF95A68CC37h) ; 若为假, 则往下执行. 743: vrt = Avx.Add(vrt, p0); // Add. vrt += vsrc[i]; 00007FF95A68CC26 vaddps ymm1,ymm1,ymmword ptr [r10] ; ymm1 = ymm1 + [r10]; 该指令的最后一个参数可以是内存地址,便从 r10(p0)加载了数据。注意ymm1是累加结果变量“vrt”. 00007FF95A68CC2B add r10,20h ; r10 + 20h; 对应 `p0 = ref Unsafe.Add(ref p0, 1);`. 使r10寄存器指向下一笔数据. 向量类型的长度是256位,为32字节,既十六进制的“20h”. 742: for (i = 0; i < cntBlock; ++i) { 00007FF95A68CC2F inc r11d ; ++r11d; 这是for的“++i”部分. 00007FF95A68CC32 cmp r11d,eax ; 这是for的“i < cntBlock”部分. 若为真,会用下一条语句跳转到“07FF95A68CC26h”,即循环内的第一条语句. 00007FF95A68CC35 jl BenchmarkVector.BenchmarkVectorDemo.SumVectorAvxRef(Single[], Int32, Int32)+056h (07FF95A68CC26h) ; 若为假, 则往下执行, 离开循环. 748: for (i = 0; i < cntRem; ++i) { 00007FF95A68CC37 xor r11d,r11d 可以看出,上面的汇编代码的质量很高——
- 不仅对内在函数做了内联优化, 且将引用的相关操作(
Unsafe.As、Unsafe.Add)也做了内联, 转成了高效率的地址计算指令。 - 充分利用了寄存器,避免了慢速的栈内存。
三、结语
还可以对照一下SumVectorAvxPtr运行时的汇编代码, 会发现它与SumVectorAvxRef的几乎是一样的。这就是“引用版函数与指针版函数的性能几乎一致”的原因,现在有汇编代码为证。
这也是 第2篇文章 发现“C# 向量算法与C++版向量算法的性能几乎一致”的原因。因为它们都已经被编译为高效率的汇编代码。
除了“Disassembly”窗口外,还可以使用 WinDbg、BenchmarkDotNet、CoreCLR命令行 等办法来查看汇编代码。有兴趣的读者,可以查看 Nemanja Mijailovic 的文章.
参考文献
- Microsoft《Debugger.Break 方法》. https://learn.microsoft.com/zh-cn/dotnet/api/system.diagnostics.debugger.break?view=net-7.0
- Leon_Chaunce《.NET Core 2.1中的分层编译(预览)》. https://www.cnblogs.com/xiaoliangge/p/9441988.html
- Nemanja Mijailovic《Exploring .NET Core platform intrinsics: Part 3 - Viewing the code generated by the JIT》. https://mijailovic.net/2018/07/05/generated-code/
- zyl910《
C# 使用SIMD向量类型加速浮点数组求和运算(1):使用Vector4、Vector<T>》. https://www.cnblogs.com/zyl910/p/dotnet_simd_BenchmarkVector1.html - zyl910《
C# 使用SIMD向量类型加速浮点数组求和运算(2): C# 通过Intrinsic直接使用AVX指令集操作 Vector256<T>,及C++程序对比》. https://www.cnblogs.com/zyl910/p/dotnet_simd_BenchmarkVector2.html - zyl910《
C# 使用SIMD向量类型加速浮点数组求和运算(3):循环展开》. https://www.cnblogs.com/zyl910/p/dotnet_simd_BenchmarkVector3.html - zyl910《
C# 使用SIMD向量类型加速浮点数组求和运算(4):用引用代替指针, 摆脱unsafe关键字,兼谈Unsafe类的使用》. https://www.cnblogs.com/zyl910/p/dotnet_simd_BenchmarkVector4.html




