- A+
空闲空间的管理
关于空闲空间的管理,前面提到的是已被占用的数据块的组织和管理。接下来要解决的问题是,当我要保存一个数据块时,应该将其放在硬盘的哪个位置。难道需要扫描所有的块,随意找个空的地方放吗?
然而,这种方式效率太低了。因此,我们需要引入一种管理磁盘空闲空间的机制。下面介绍几种常见的方法:
- 空闲表法:使用一个表格来维护磁盘空闲块的信息。表格中的每个条目表示一个空闲块,包含块的起始地址和长度。当需要保存数据块时,可以在表格中找到合适的空闲块,并将其标记为已占用。
- 空闲链表法:使用链表来维护磁盘空闲块的信息。每个链表节点表示一个空闲块,包含块的起始地址和长度,以及指向下一个空闲块的指针。通过遍历链表,可以找到合适的空闲块,并将其标记为已占用。
- 位图法:使用一个位图来表示磁盘的空闲块信息。位图中的每个位表示一个块的状态,1表示已占用,0表示空闲。通过对位图进行操作,可以快速找到空闲块并标记为已占用。
你可以想象一下如果给你一张MySQL表,在已经分配好所有id主键后,你可能会觉得一直顺序写入就可以了,但是一旦中间有删除的操作,这就会存在有空闲的id行没用上,你去保存有空闲的数据行可以怎么做?
空闲表法
它通过建立一张表来记录所有的空闲区域,表中包括空闲区的第一个块号和该空闲区的块个数。需要注意的是,这种方法适用于连续分配。如图所示:
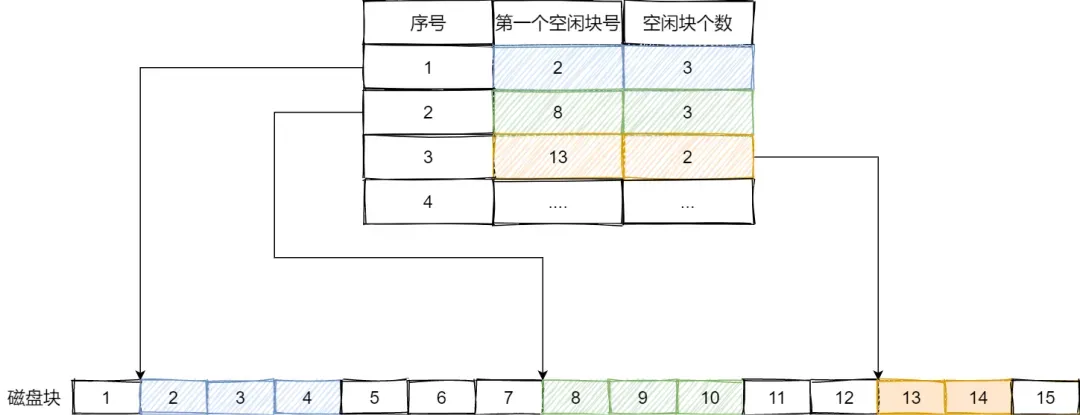
当系统需要分配磁盘空间时,它会顺序扫描空闲表的内容,直到找到一个合适的空闲区域为止。而当用户撤销一个文件时,系统会回收文件的空间。此时,系统会再次顺序扫描空闲表,寻找一个空闲表条目,并将释放空间的第一个物理块号及其占用的块数填入该条目中。
然而,空闲表法在空闲区较少的情况下才能发挥较好的效果。如果存储空间中存在大量小的空闲区域,空闲表会变得非常庞大,从而降低查询效率。此外,这种分配技术适用于建立连续文件。
空闲链表法
除了空闲表法之外,我们还可以使用空闲链表法来管理磁盘的空闲空间。在空闲链表法中,我们使用链表的方式来组织和管理空闲块。如下图:
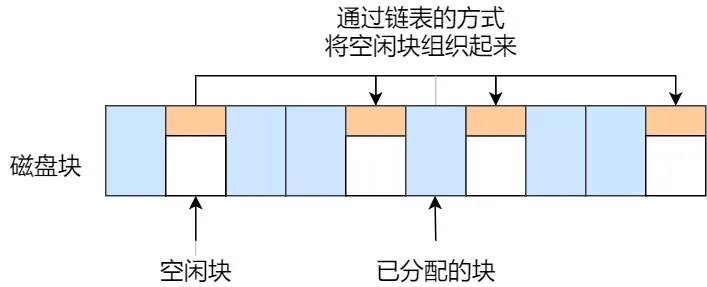
每个空闲块都包含一个指针,指向下一个空闲块。当需要创建文件时,我们可以从链表的头部开始依次获取所需的块数。相反地,当需要回收空间时,我们可以将这些空闲块依次接入链表的头部。
使用空闲链表法的好处是它的实现相对简单,只需要在主存中保存一个指针,指向链表的头部即可。然而,空闲链表法也有一些局限性。由于无法进行随机访问,它的工作效率较低。每当在链表上增加或移动空闲块时,都需要进行大量的输入/输出操作。此外,空闲链表法也会消耗一定的存储空间,因为每个数据块都需要包含一个指针。
需要注意的是,空闲链表法和空闲表法都不适合用于大型文件系统,因为它们会导致空闲表或空闲链表变得过大。在大型文件系统中,我们需要考虑更高效的管理方法来提高性能和减少空间消耗。
位图法
除了空闲表法和空闲链表法,我们还可以使用位图法来管理磁盘的空闲空间。位图法利用二进制位来表示磁盘中每个块的使用情况,每个块都有一个对应的二进制位。
当二进制位的值为0时,表示对应的盘块是空闲的;当二进制位的值为1时,表示对应的盘块已经被分配。位图的形式如下所示:
11111111111111100011101101111...
在 Linux 文件系统就采用了位图的方式来管理空闲空间,位图不仅用于管理数据空闲块,还用于管理inode(索引节点)空闲块。因为inode也是存储在磁盘上的,所以需要对其进行管理。
位图法的优点是实现简单,存储空间占用小。通过位运算可以快速判断一个盘块是否空闲,以及找到一个空闲盘块。由于位图法不需要额外的数据结构来记录空闲块的信息,因此在大型文件系统中,位图法往往是一种较为高效的管理方法。
文件系统的结构
文件系统的结构主要包括普通文件和目录两类。普通文件是存储用户数据的基本单位,而目录则用于组织和管理文件。下面我们来详细了解它们的存储方式。
文件的存储
在Linux文件系统中,文件的存储是通过位图的方式进行管理的。当用户创建一个新文件时,Linux内核会根据inode的位图来找到空闲可用的inode,并进行分配。当需要存储数据时,它会通过块的位图来找到空闲的数据块,并进行分配。然而,经过仔细计算后,我们会发现存在一些问题。
数据块的位图是存储在磁盘块中的,假设每个块的大小为4K,那么一个块能够表示的位数就是4 × 1024 × 8 = 215个块。由于每个数据块的大小为4K,那么最大可以表示的空间就是215 × 4 × 1024 = 2^27个字节,即128M。
换句话说,按照上述结构,如果使用"一个块的位图 + 一系列的块"以及"一个块的inode位图 + 一系列的inode结构"来表示空间,最大能够表示的空间也只有128M。然而,现在很多文件的大小都超过了这个限制。
因此,在Linux文件系统中,引入了块组的概念来解决这个问题。每个块组包含一个块的位图和一系列的块,以及一个inode的位图和一系列的inode结构。通过增加块组的数量,文件系统就能够表示更大的文件。这样,用户就可以利用多个块组来存储大文件,从而突破了128M的限制。
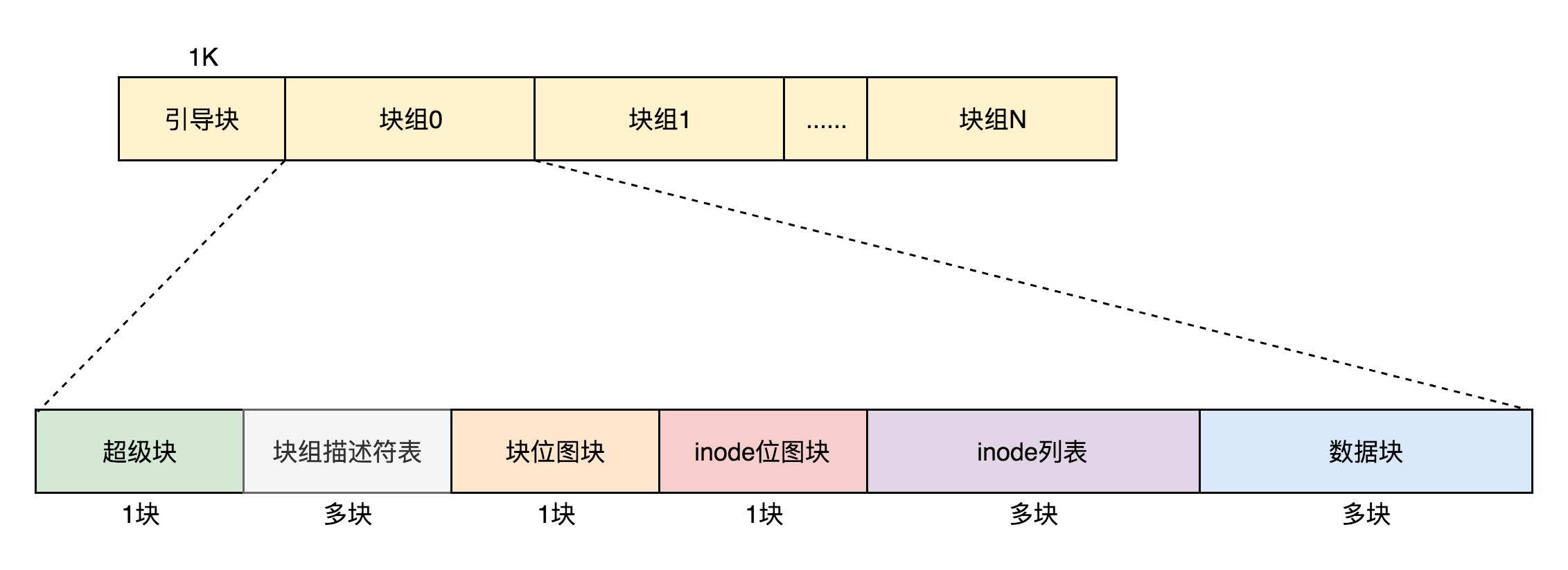
最前面的第一个块是引导块,在系统启动时用于启用引导,接着后面就是一个一个连续的块组了,块组的内容如下:
- 超级块,它包含了文件系统的重要信息,比如inode总个数、块总个数、每个块组的inode个数、每个块组的块个数等等。超级块对于文件系统的正常运行起着至关重要的作用。
- 块组描述符,它包含了文件系统中各个块组的状态信息,比如块组中空闲块和inode的数目等。每个块组都包含了文件系统中所有块组的组描述符信息,这样可以方便地管理和维护整个文件系统。
- 数据位图和inode位图,它们用于表示对应的数据块或inode是空闲的,还是被使用中。数据位图和inode位图的使用可以有效地管理文件系统的空闲空间和资源。
- inode列表,它包含了块组中所有的inode。inode用于保存文件系统中与各个文件和目录相关的所有元数据,比如文件的大小、权限、所属用户等。
- 数据块,它包含了文件的有用数据。
你可能会发现每个块组里有很多重复的信息,比如超级块和块组描述符表,这两个都是全局信息,而且非常重要。这么做有两个原因:
- 一是如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
- 二是通过使文件和管理数据尽可能接近,可以减少磁头寻道和旋转,从而提高文件系统的性能。不过,Ext2的后续版本采用了稀疏技术。稀疏技术的做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组0、块组1和其他ID可以表示为3、5、7的幂的块组中。这样可以进一步减少重复的信息,提高文件系统的存储效率和性能。
目录的存储
在前面我们已经了解了普通文件的存储方式,但是目录作为一个特殊文件,它的存储方式又是怎样的呢?
基于 Linux 一切皆文件的设计思想,目录实际上也是一个文件,你甚至可以使用vim打开它。目录文件也有一个inode,其中也包含指向其他块的指针。
然而,与普通文件不同的是,普通文件的块中保存的是文件的实际数据,而目录文件的块中保存的是目录中每个文件的信息。
目录文件的块中最简单的保存格式是一个列表,即将目录下的文件信息(例如文件名、文件inode、文件类型等)逐项列在表中。
列表中的每一项代表该目录下的文件名和对应的inode。通过这个inode,我们可以方便地找到真正的文件。
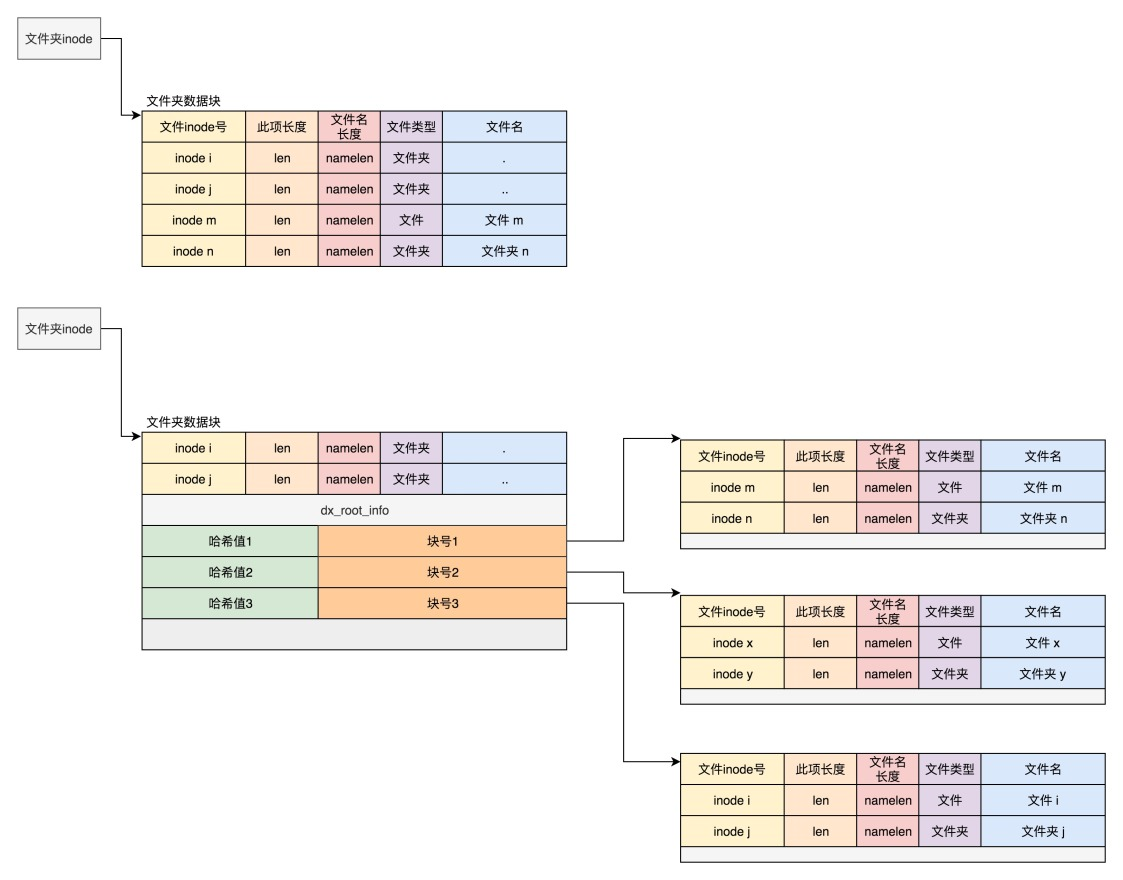
通常,目录文件的第一项是「.」,表示当前目录,第二项是「..」,表示上一级目录,随后是每个文件的文件名和对应的inode(如果想要查看的话,vim是不可以直接显示inode的,可以使用ls -i命令来显示目录中的文件名和对应的inode号码)。然而,当一个目录包含大量文件时,按顺序逐项查找效率较低。
为了提高查找效率,目录文件的存储格式可以改为哈希表。通过对文件名进行哈希计算并保存哈希值,我们可以通过哈希值快速定位到相应的块,以获取文件信息。Linux系统的ext文件系统采用了这种哈希表的存储方式,它的优点在于查找速度快、插入和删除操作相对简单,但需要采取一些预防措施以避免哈希冲突。
目录查询是通过在磁盘上反复搜索完成,需要不断地进行 I/O 操作,开销较大。所以,为了减少磁盘I/O操作的开销,目录查询时可以将当前使用的目录缓存到内存中。这样,在以后需要使用该目录中的文件时,只需在内存中进行操作,减少了磁盘访问次数,提高了文件系统的访问速度。
总结
空闲空间的管理是文件系统中一个重要的问题。为了有效地管理磁盘空闲空间,我们可以使用空闲表法、空闲链表法和位图法等方法。其中,空闲表法使用表格来维护磁盘空闲块的信息,空闲链表法使用链表来维护磁盘空闲块的信息,位图法使用位图来表示磁盘空闲块的状态。每种方法都有其优缺点,适用于不同规模和需求的文件系统。
文件系统的结构主要包括普通文件和目录两类。普通文件是存储用户数据的基本单位,目录用于组织和管理文件。
总的来说,空闲空间的管理和文件系统的结构设计都是为了提高文件系统的性能和效率,以满足用户对存储和访问数据的需求。




