- A+
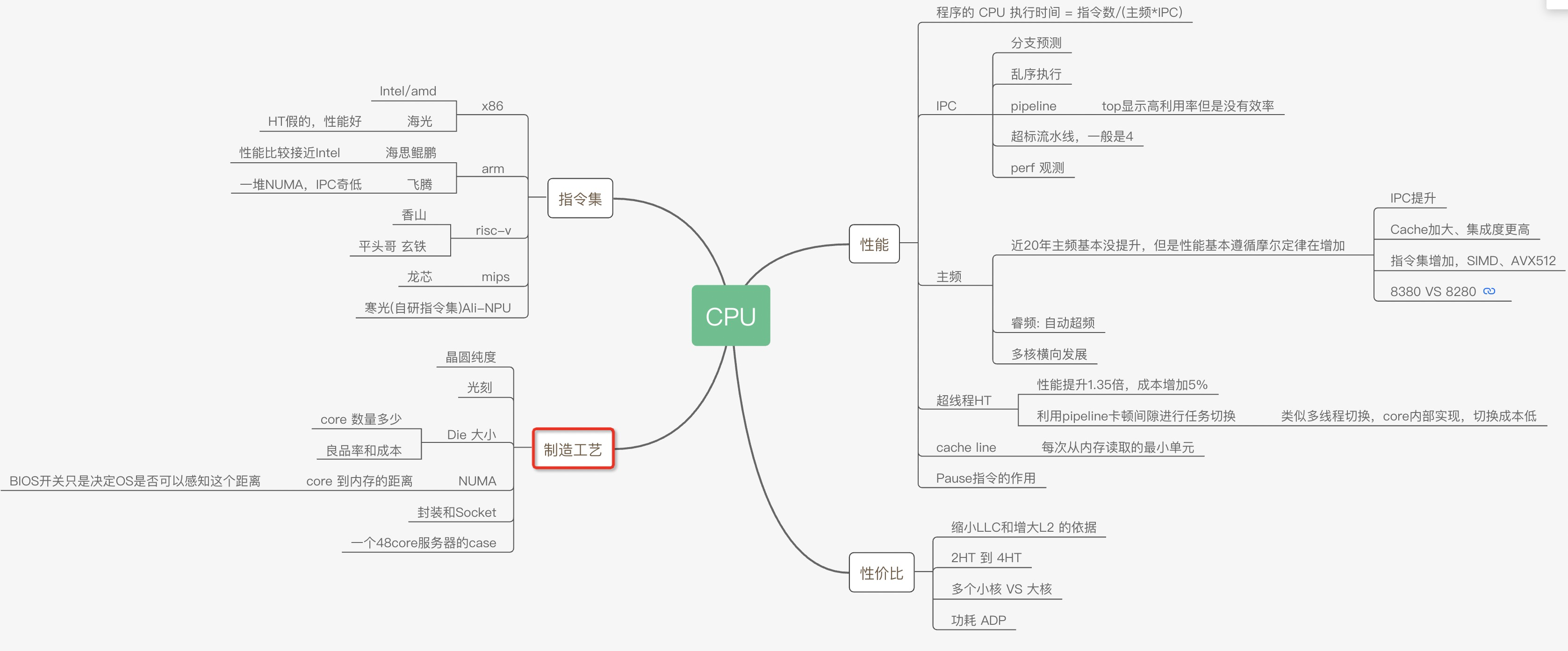
为了让程序能快点,特意了解了CPU的各种原理,比如多核、超线程、NUMA、睿频、功耗、GPU、大小核再到分支预测、cache_line失效、加锁代价、IPC等各种指标(都有对应的代码和测试数据)都会在这系列文章中得到答案。当然一定会有程序员最关心的分支预测案例、Disruptor无锁案例、cache_line伪共享案例等等。
这次让我们从最底层的沙子开始用8篇文章来回答各种疑问以及大量的实验对比案例和测试数据。
大的方面主要是从这几个疑问来写这些文章:
- 同样程序为什么CPU跑到800%还不如CPU跑到200%快?
- IPC背后的原理和和程序效率的关系?
- 为什么数据库领域都爱把NUMA关了,这对吗?
- 几个国产芯片的性能到底怎么样?
系列文章
Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的
AMD Zen CPU 架构 以及 AMD、海光、Intel、鲲鹏的性能对比
几个重要概念
为了增加对文章的理解先解释下几个高频概念
Wafer:晶圆,一片大的纯硅圆盘,新闻里常说的12寸、30寸晶圆厂说的就是它,光刻机在晶圆上蚀刻出电路
Die:从晶圆上切割下来的CPU(通常一个Die中包含多个core、L3cache、内存接口、GPU等,core里面又包含了L1、L2cache),Die的大小可以自由决定,得考虑成本和性能, Die做成方形便于切割和测试,服务器所用的Intel CPU的Die大小一般是大拇指指甲大小。
封装:将一个或多个Die封装成一个物理上可以售卖的CPU
路:就是socket、也就是封装后的物理CPU
node:同一个Die下的多个core以及他们对应的内存,对应着NUMA
售卖的CPU实物
购买到的CPU实体外观和大小,一般是40mm X 50mm大小,可以看出一个CPU比一个Die大多了。



裸片Die 制作
晶圆为什么总是圆的呢?生产过程就是从沙子中提纯硅,硅晶柱生长得到晶圆,生长是以圆柱形式的,所以切割下来的晶圆就是圆的了:

硅晶柱切片:

直径为 300 毫米的纯硅晶圆(从硅柱上切割下来的圆片),俗称 12 寸晶圆,大约是 400 美金。但尺寸并不是衡量硅晶圆的最重要指标,纯度才是。日本的信越公司可以生产 13 个 9 纯度的晶圆。
高纯硅的传统霸主依然是德国Wacker和美国Hemlock(美日合资),中国任重而道远。太阳能级高纯硅要求是99.9999%,低纯度的硅全世界超过一半是中国产的,但是不值钱。而芯片用的电子级高纯硅要求99.999999999%,几乎全赖进口,直到2018年江苏鑫华公司才实现量产,目前年产0.5万吨,而中国一年进口15万吨。核心材料技术这块毫无疑问“外国仍然把中国摁在地上摩擦”。
芯片设计
主要依赖EDA, EDA工具是电子设计自动化(Electronic Design Automation)的简称,从计算机辅助设计(CAD)、计算机辅助制造(CAM)、计算机辅助测试(CAT)和计算机辅助工程(CAE)的概念发展而来的,是IC基础设计能力。利用EDA工具,工程师将芯片的电路设计、性能分析、设计出IC版图的整个过程交由计算机自动处理完成。
EDA软件方面早已形成了三巨头——Synopsys、Cadence、Mentor。Synopsys是EDA三巨头之首,国内从事EDA软件开发的华大九天和这三家比起来不是一个数量级。国内IC设计公司几乎100%采用国外EDA工具,在未来的相当长的一段时间里,我们应该看不到缩小和Synopsys、Cadence、Mentor技术差距的可能性。
光刻
使用特定波长的光,透过光罩(类似印炒里面的母版),照射在涂有光刻胶的晶圆上,光罩上芯片的设计图像,就复制到晶圆上了,这就是光刻,这一步是由光刻机完成的,光刻机是芯片制造中光刻环节的核心设备。你可以把光刻理解为,就是用光罩这个母版,一次次在晶圆上印电路的过程。
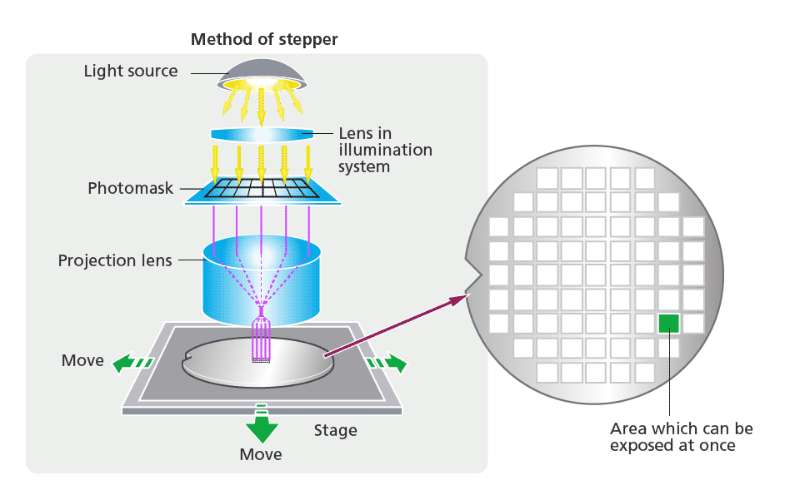
光刻是最贵的一个环节,一方面是光罩越来越多,越来越贵,另一方面光刻机也很贵。光刻机是半导体制造设备中价格占比最大,也是最核心的设备。2020 年荷兰公司 ASML 的极紫外光源(EUV)光刻机每台的平均售价是 1.45 亿欧元,而且全世界独家供货,年产量 31 台,有钱也未必能买得到。

短波长光源是提高光刻机分辨力的有效方,光刻机的发展历史,就从紫外光源(UV)、深紫外光源(DUV),发展到了现在的极紫外光源(EUV)。
回顾光刻机的发展历史,从 1960 年代的接触式光刻机、接近式光刻机,到 1970 年代的投影式光刻机,1980 年代的步进式光刻机,到步进式扫描光刻机、浸入式光刻机和现在的深紫外光源(DUV)和极紫外光源(EUV)光刻机,一边是设备性能的不断提高,另一边是价格逐年上升,且供应商逐渐减少。到了 EUV 光刻机,ASML(阿斯麦) 就是独家供货了。英特尔有阿斯麦15%的股份,台积电有5%,三星有3%,另外美国弄了一个《瓦森纳协定》,敏感技术不能卖,中国、朝鲜、伊朗、利比亚均是被限制国家。
品质合格的die切割下去后,原来的晶圆成了下图的样子,是挑剩下的Downgrade Flash Wafer。残余的die是品质不合格的晶圆。黑色的部分是合格的die,会被原厂封装制作为成品NAND颗粒,而不合格的部分,也就是图中留下的部分则当做废品处理掉。
从晶圆上切割检测合格的Die(螺片),所以Die跟Wafer不一样不是圆的,而是是方形的,因为方形的在切割封测工艺上最简单

一个大晶圆,拿走了合格的Die后剩下的次品:

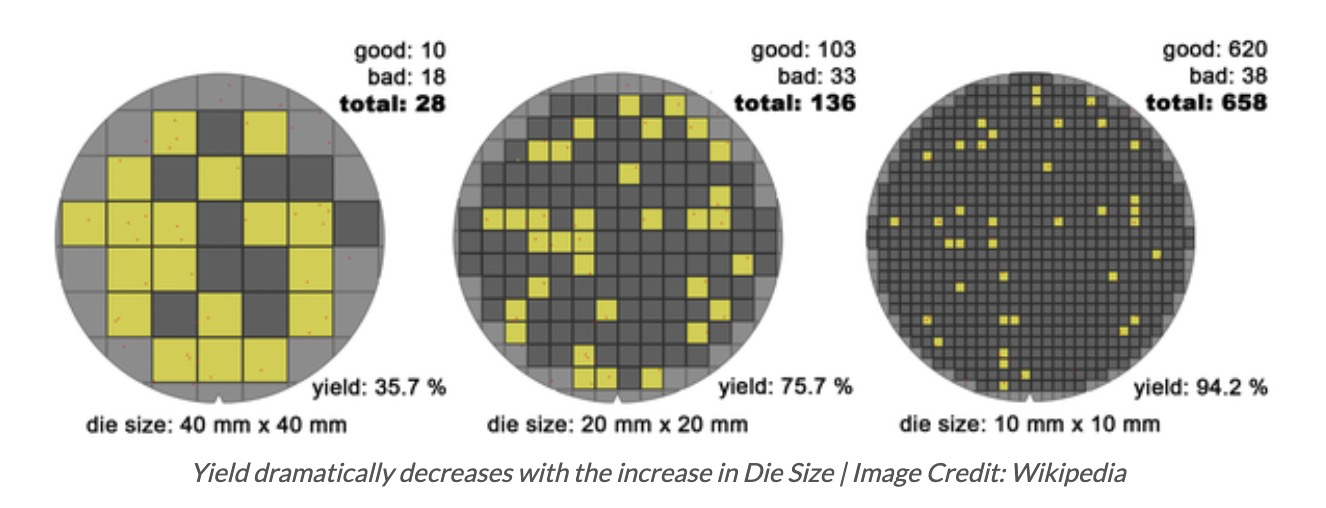
可见次品率不低,后面会谈到怎么降低次品率,次品率决定了CPU的价格。
台积电一片 5nm 晶圆的加工费高达 12500 美金。根据台积电的财报推算,台积电平均每片晶圆可以产生近 4000 美金(300mm 晶圆)的利润。无论是哪个数字,对比 400 美金的纯硅晶圆原料来说,这都是一个至少增值 10 倍的高价值的加工过程。
随着Die的缩小,浪费的比例也从36%缩小成为12.6%。根据极限知识,我们知道如果Die的大小足够小,我们理论上可以100%用上所有的Wafer大小。从中我们可以看出越小的Die,浪费越小,从而降低CPU价格,对CPU生产者和消费者都是好事。
光刻机有一个加工的最大尺寸,一般是 858mm²,而 Cerebras 和台积电紧密合作,做了一个 46255mm²,1.2T 个晶体管的世界第一大芯片。这也是超摩尔定律的一个突破。
AMD在工艺落后Intel的前提下,又想要堆核,只能采取一个Package封装4个独立Die的做法,推出了Zen1 EPYC服务器芯片,即不影响良率,又可以核心数目好看,可谓一举两得。
可惜连接四个Die的片外总线终归没有片内通信效率高,在好些benchmark中败下阵来,可见没有免费的午餐。

Intel的Pakcage内部是一个Die, Core之间原来是Ring Bus,在Skylake后改为Mesh。AMD多Die封装的目的是省钱和增加灵活性!AMD每个Zeppelin Die都比Intel的小,这对良品率提高很大,节约了生产费用。
这种胶水核强行将多个die拼一起是没考虑跨die之间的延迟,基本上跨die跟intel跨socket(numa)时延一样了。
一颗芯片的 1/3 的成本,是花在封测阶段的
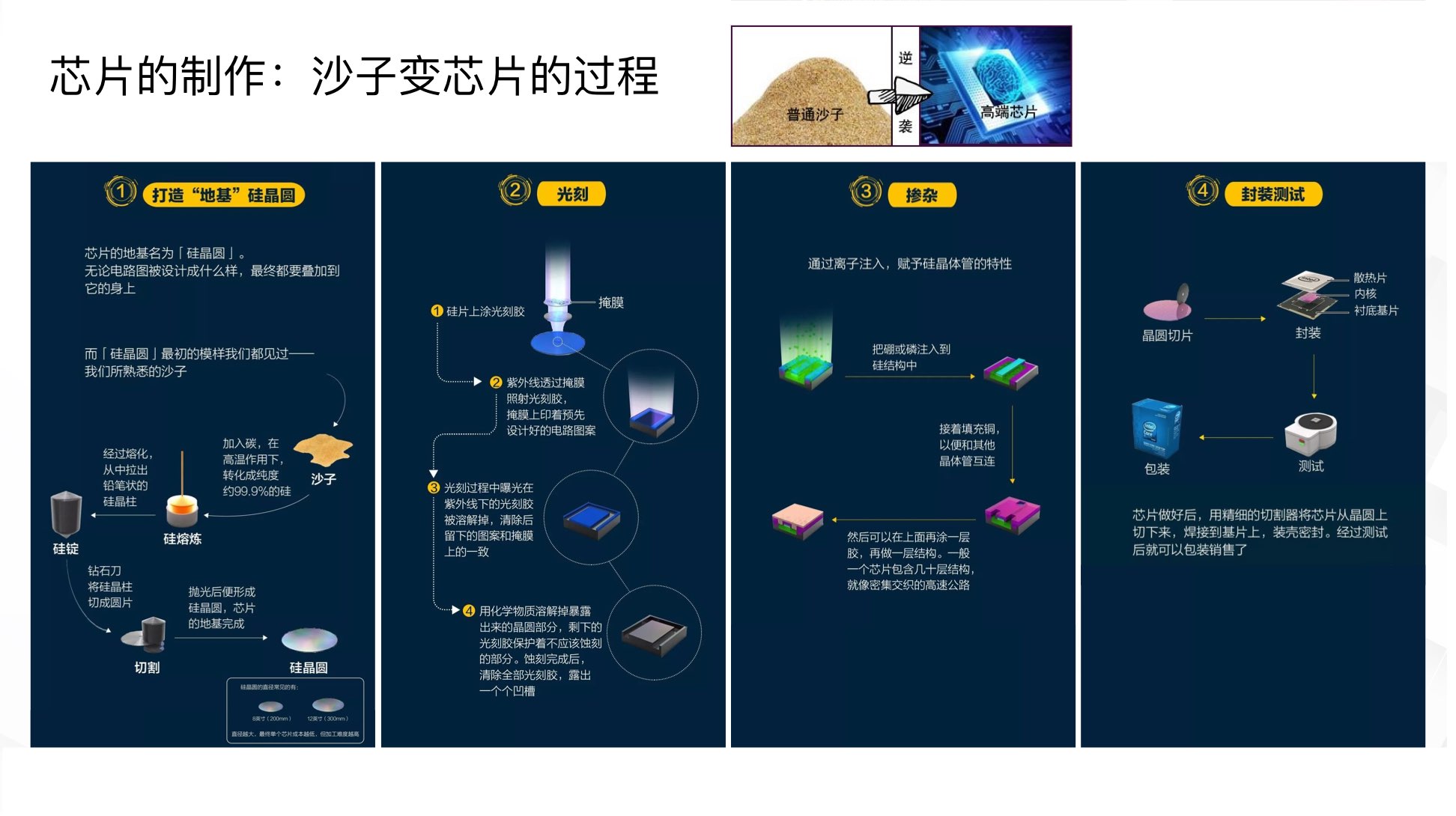
一个晶体管(纳米尺度),注意三个黄色的导电铜点

对应的一个逻辑意义上的NPMOS 晶体管:
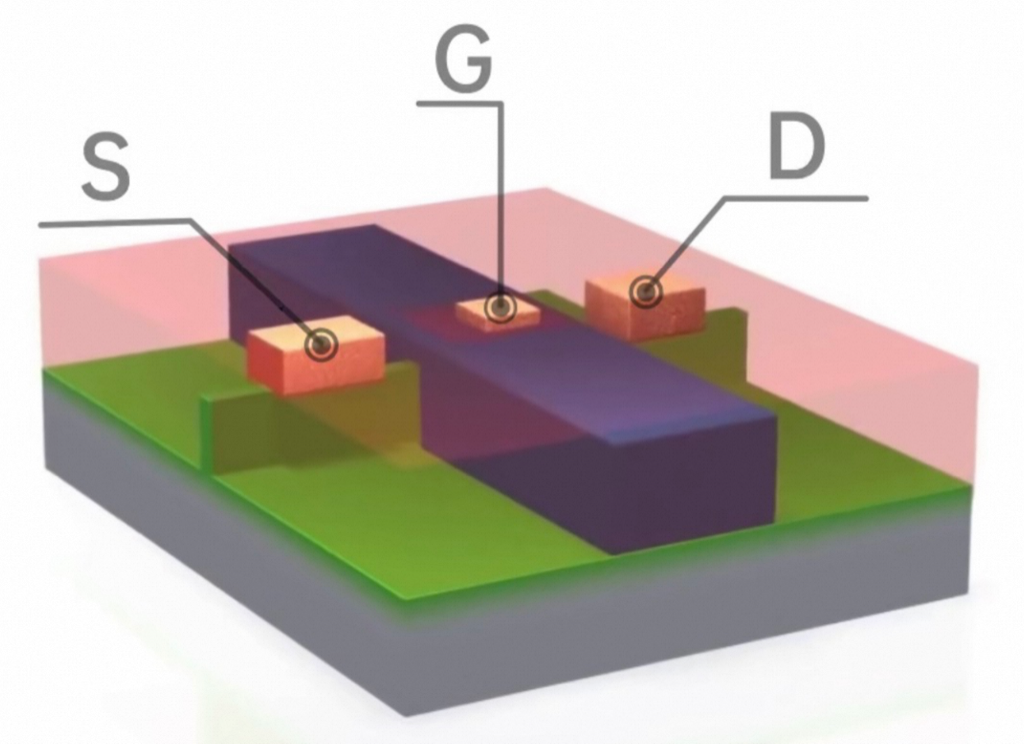
MOS :金属-氧化物-半导体,而拥有这种结构的晶体管我们称之为MOS晶体管。 MOS晶体管有P型MOS管和N型MOS管之分。 由MOS管构成的集成电路称为MOS集成电路,由NMOS组成的电路就是NMOS集成电路,由PMOS管组成的电路就是PMOS集成电路,由NMOS和PMOS两种管子组成的互补MOS电路,即CMOS电路
Die和core
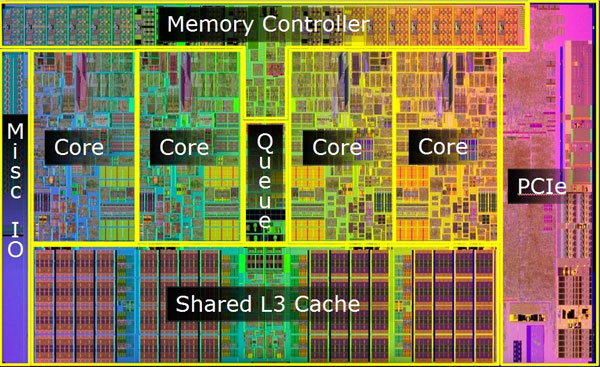
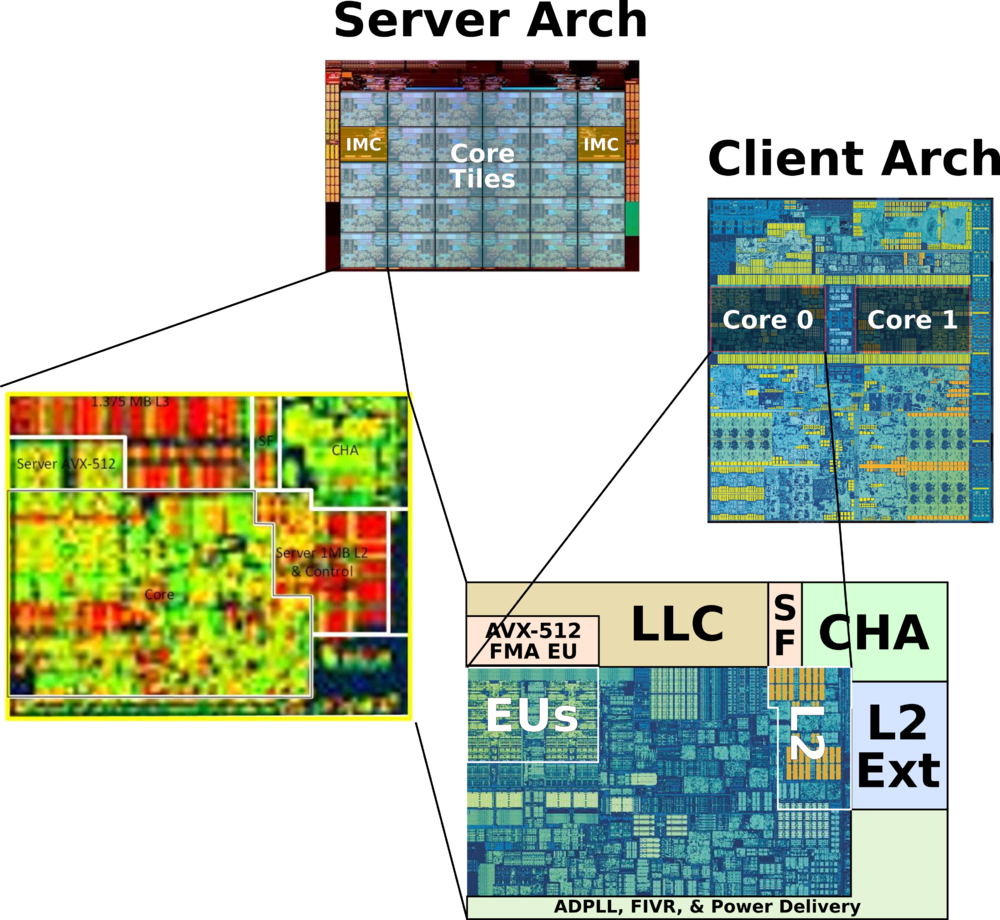
One die with multiple cores,下图是一个Die内部图:
或者Skylake:
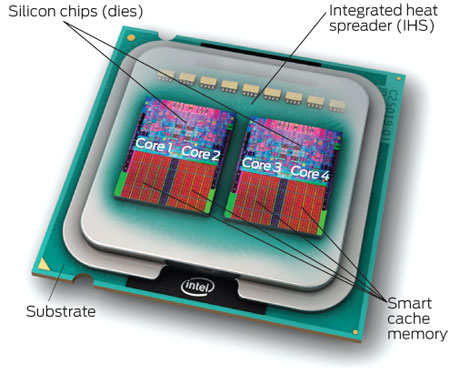
将两个Die封装成一块CPU(core多,成本低):
第4代酷睿(Haswell)的die:
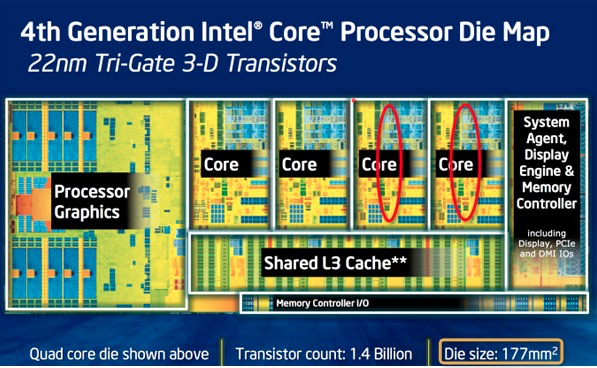
第4代酷睿(Haswell)的die主要分为几个部分:GPU、4个core、System Agent(uncore,类似北桥)、cache和内存控制器和其他小部件。比如我们发现core 3和4有问题,我们可以直接关闭3和4。坏的关掉就是i5, 都是好的就当i7来卖。
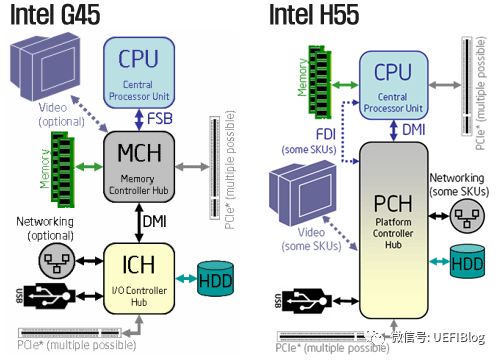
北桥和南桥
早期CPU core和内存硬盘的连接方式(FSB 是瓶颈):

个人PC主板实物图:
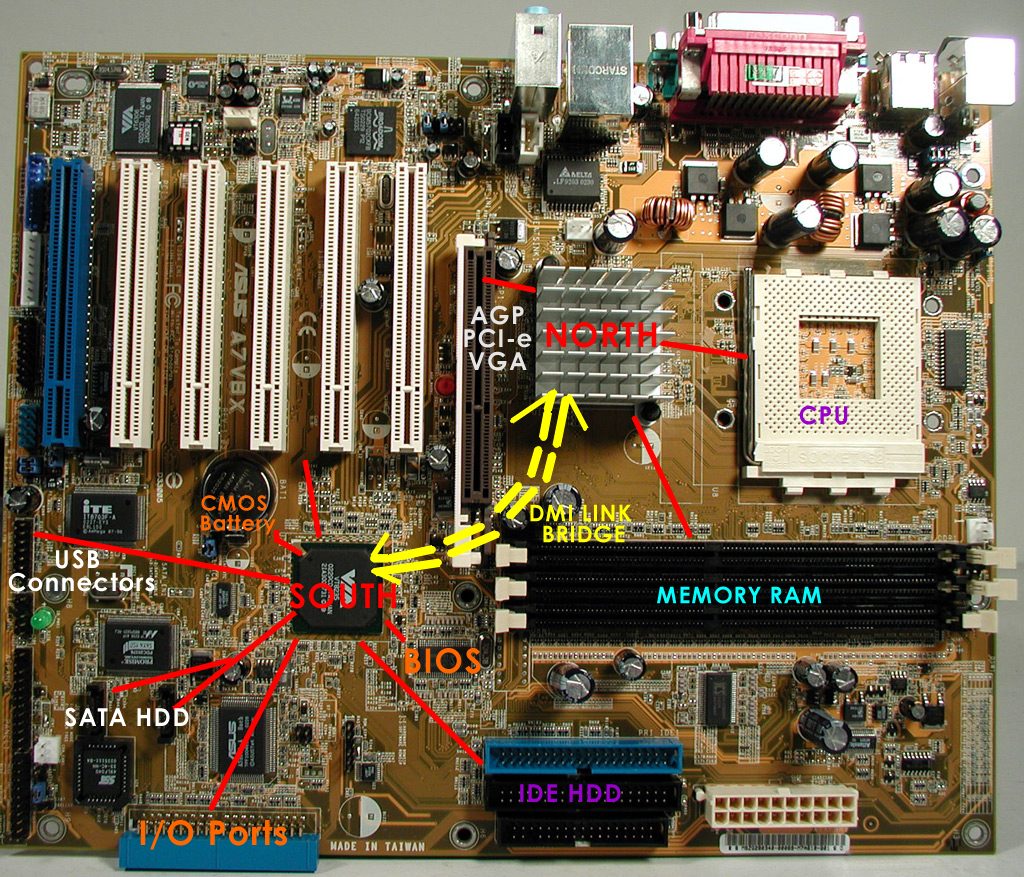
由于FSB变成了系统性能的瓶颈和对多CPU的制约,在台式机和笔记本电脑中,MCH(Memory Control Hub)被请进CPU中,服务器市场虽然短暂的出现了IOH。
集成北桥后的内存实物图:

北桥已经集成到CPU中,南桥还没有,主要是因为:集成后Die增大不少,生产良品率下降成本上升;不集成两者采用不同的工艺;另外就是CPU引脚不够了!

SoC(System on Chip):南桥北桥都集成在CPU中,单芯片解决方案。ATOM就是SoC
现代CPU的基本架构
下图是一个两路的服务器结构,每路4个内存channel

一个Core的典型结构
Intel skylake 架构图
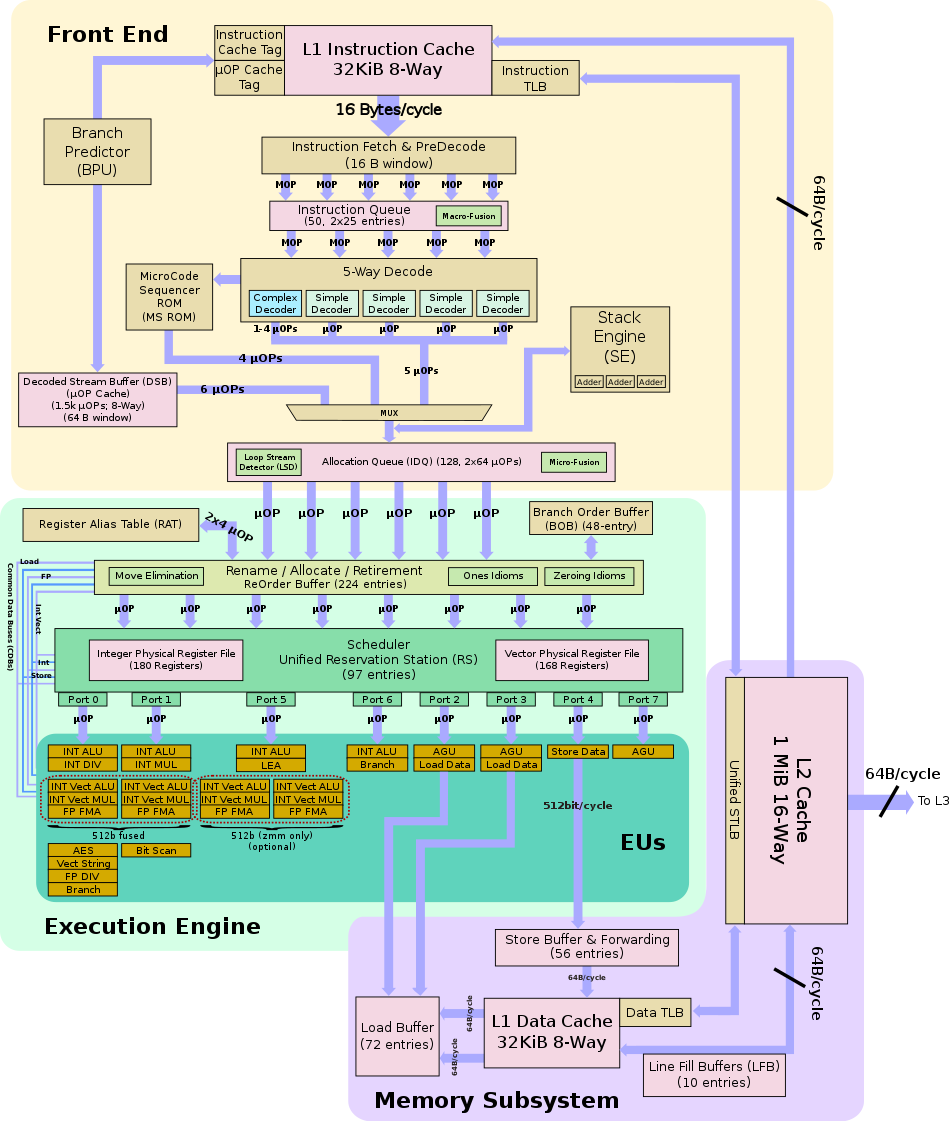
iTLB:instruct TLB
dTLB:data TLB
多个core加上L3等组成一个Die:

多核和多个CPU
如果要实现一台48core的计算能力的服务器,可以有如下三个方案
方案1:一个大Die集成48core: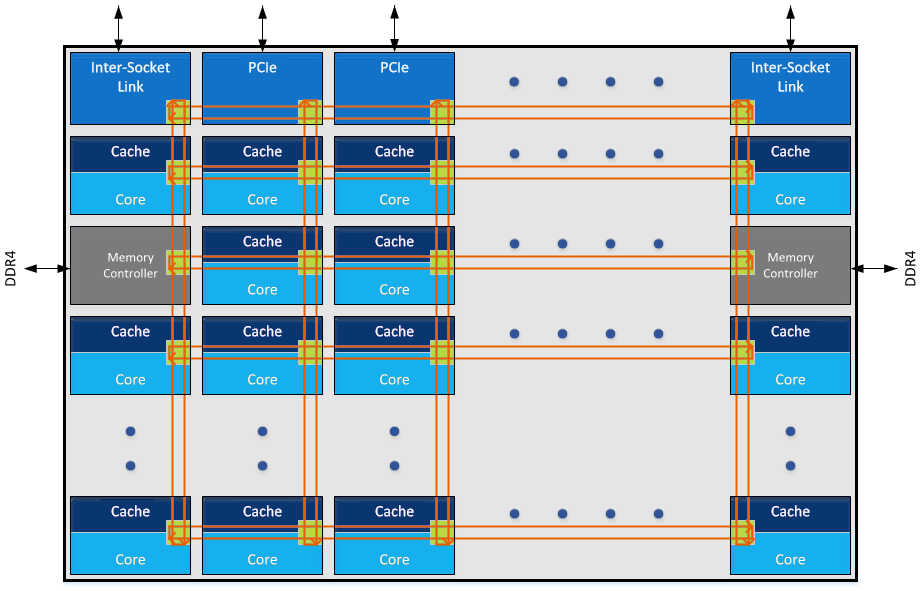
方案2:一个CPU封装8个Die,也叫MCM(Multi-Chip-Module),每个Die 6个core

四个Die之间的连接方法:
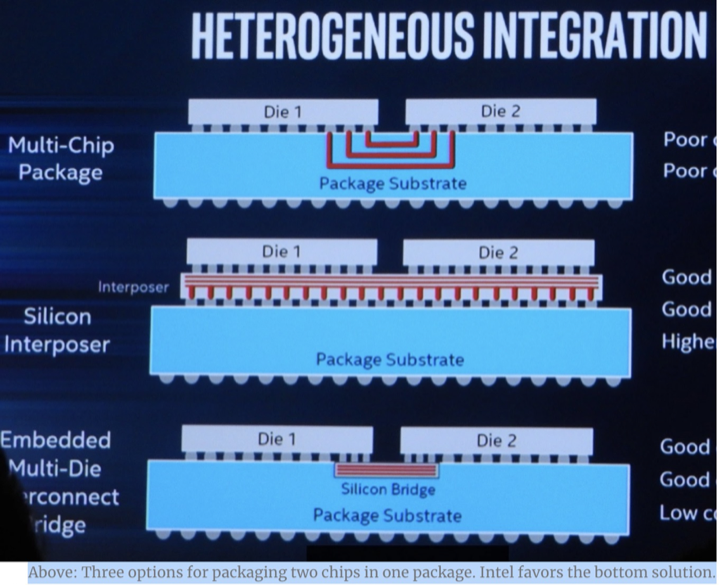
上图最下面的方案为Intel采用的EMIB(Embedded Multi-die Interconnect Bridge)方案,cost 最低。中间的方案是使用“硅中介层”(Interposer,AMD采用的方案)。这意味着你能在两枚主要芯片的下面放置和使用第三枚芯片。这枚芯片的目的是使得多个设备的连接更加容易,但是也带来了更高的成本。
方案3:四个物理CPU(多Socket),每个物理CPU(Package)里面一个Die,每个Die12个core:

三者的比较:
性能肯定是大Die最好,但是良品率低、成本高;
方案2的多个Die节省了主板上的大量布线和VR成本,总成本略低,但是方案3更容易堆出更多的core和内存
面积和性能
我们使用了当时Intel 用在数据中心计算的大核CPU IvyBridge与当时用于 存储系列的小核CPU Avoton(ATOM), 分别测试阿里巴巴的workload,得到性能吞吐如下:
| Intel 大小CPU 核心 | 阿里 Workload Output(QPS) |
|---|---|
| Avoton(8 cores) 2.4GHZ | 10K on single core |
| Ivy Bridge(2650 v2 disable HT) 2.6GHZ | 20K on single core |
| Ivy Bridge(2650 v2 enable HT) 2.4GHZ | 25K on single core |
| Ivy Bridge(2650 v2 enable HT) 2.6GHZ | 27K on single core |
- 大小核心直观比较:超线程等于将一个大核CPU 分拆成两个小核,Ivy Bridge的数据显示超线程给 Ivy Bridge 1.35倍(27K/20K) 的提升
- 性能与芯片面积方面比较:现在我们分别评判 两种CPU对应的性能密度 (performance/core die size) ,该数据越大越好,根据我们的计算和测量发现 Avoton(包含L1D, L1I, and L2 per core)大约是 3~4平方毫米,Ivy Bridge (包含L1D, L1I, L2 )大约是12~13平方毫米, L3/core是 6~7平方毫米, 所以 Ivy Bridge 单核心的芯片面积需要18 ~ 20平方毫米。基于上面的数据我们得到的 Avoton core的性能密度为 2.5 (10K/4sqmm),而Ivy Bridge的性能密度是1.35 (27K/20sqmm),因此相同的芯片面积下 Avoton 的性能是 Ivy Bridge的 1.85倍(2.5/1.35).
- 性能与功耗方面比较: 从功耗的角度看性能的提升的对比数据,E5-2650v2(Ivy Bridge) 8core TDP 90w, Avoton 8 core TDP 20瓦, 性能/功耗 Avoton 是 10K QPS/20瓦, Ivy Bridge是 27KQPS/90瓦, 因此 相同的功耗下 Avoton是 Ivy Bridge的 1.75倍(10K QPS/20)/ (27KQPS/95)
- 性能与价格方面比较: 从价格方面再进行比较,E5-2650v2(Ivy Bridge) 8core 官方价格是1107美元, Avoton 8 core官方价格是171美元性能/价格 Avoton是 10KQPS/171美元,Ivy Bridge 是 27KQPS/1107美元, 因此相同的美元 Avoton的性能是 Ivy Bridge 的2.3倍(1 10KQPS/171美元)/ (27KQPS/1107美元)
总结:在数据中心的场景下,由于指令数据相关性较高,同时由于内存访问的延迟更多,复杂的CPU体系结构并不能获得相应性能提升,该原因导致我们需要的是更多的小核CPU,以达到高吞吐量的能力,因此2014 年我们向Intel提出数据中心的CPU倾向“小核”CPU,需要将现有的大核CPU的超线程由 2个升级到4个/8个, 或者直接将用更多的小核CPU增加服务器的吞吐能力,经过了近8年,最新数据表明Intel 会在每个大核CPU中引入4个超线程,和在相同的芯片面积下单socket CPU 引入200多个小核CPU,该方案与我们的建议再次吻合
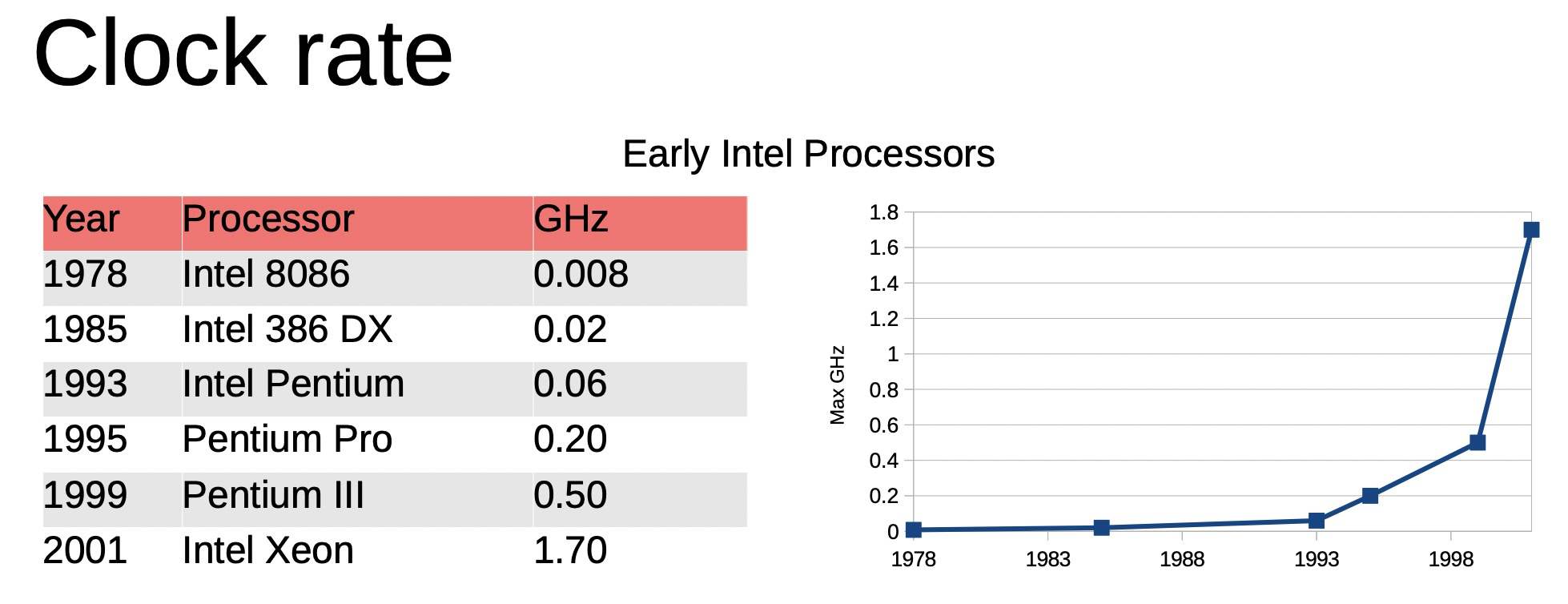
为什么这20年主频基本没有提升了
今天的2.5G CPU性能和20年前的2.5G比起来性能差别大吗?
因为能耗导致CPU的主频近些年基本不怎么提升了,不是技术上不能提升,是性价比不高.
在提升主频之外可以提升性能的有:提升跳转预测率,增加Decoded Cache,增加每周期的并发读个数,增加执行通道,增加ROB, RS,Read & Write buffer等等,这些主要是为了增加IPC,当然增加core数量也是提升整体性能的王道。另外就是优化指令所需要的时钟周期、增加并行度更好的指令等等指令集相关的优化。

the industry came up with many different solution to create better computers w/o (or almost without) increasing the clock speed.
比较两代CPU性能变化
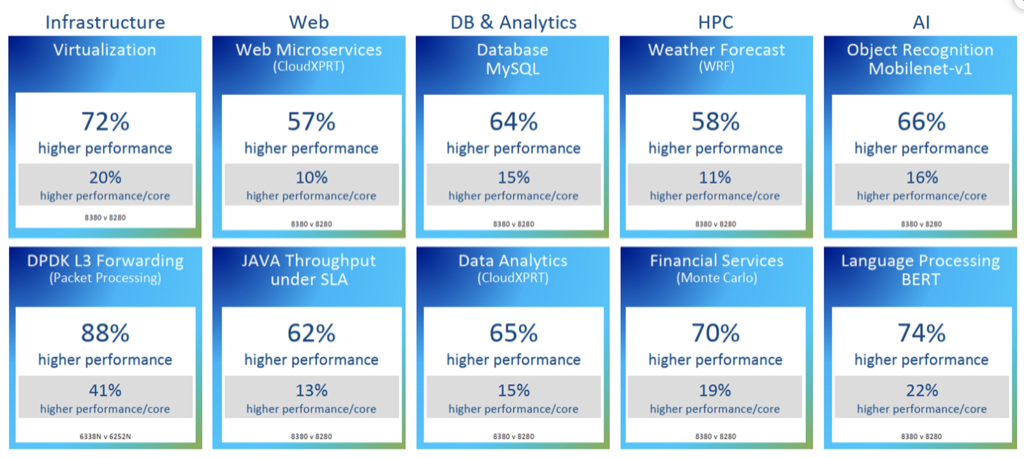
Intel 最新的CPU Ice Lake(8380)和其上一代(8280)的性能对比数据:


上图最终结果导致了IPC提升了20%
But tock Intel did with the Ice Lake processors and their Sunny Cove cores, and the tock, at 20 percent instructions per clock (IPC) improvement on integer work
ICE Lake在网络转发上的延时更小、更稳定了:

指令集优化
新增等效于某种常见指令组合的指令。原来多个指令执行需要多个时钟周期,合并后的单条指令可以在一个时钟周期执行完成。例如FMA指令,就是一条指令计算A×B+C,而无需分两个时钟周期计算。这种指令一般来说现有程序直接就能用上,无需优化。限制在于只对特定代码有效,还是以FMA为例,更普遍的普通加法、乘法运算都不能从中获益。
案例, ssse3(Supplemental Streaming SIMD Extensions 3 ) 是simd的一种,在libc-2.17.so中就有使用到,如下是mysqld进程中采集到的
|
1
2
3
4
5
|
2.79% mysqld [.] MYSQLparse
2.27% libc-2.17.so [.] __memcpy_ssse3_back //ssse3
2.19% mysqld [.] ha_insert_for_fold_func
1.95% mysqld [.] rec_get_offsets_func
1.35% mysqld [.] malloc
|
AVX(Advanced Vector Extension,高级矢量扩展指令集)
英特尔在1996年率先引入了MMX(Multi Media eXtensions)多媒体扩展指令集,也开创了SIMD(Single Instruction Multiple Data,单指令多数据)指令集之先河,即在一个周期内一个指令可以完成多个数据操作,MMX指令集的出现让当时的MMX Pentium处理器大出风头。
SSE(Streaming SIMD Extensions,流式单指令多数据扩展)指令集是1999年英特尔在Pentium III处理器中率先推出的,并将矢量处理能力从64位扩展到了128位。
AVX 所代表的单指令多数据(Single Instruction Multi Data,SIMD)指令集,是近年来 CPU 提升 IPC(每时钟周期指令数)上为数不多的重要革新。随着每次数据宽度的提升,CPU 的性能都会大幅提升,但同时晶体管数量和能耗也会有相应的提升。因此在对功耗有较高要求的场景,如笔记本电脑或服务器中,CPU 运行 AVX 应用时需要降低频率从而降低功耗。
2013 年, 英特尔 发布了AVX-512 指令集,其指令宽度扩展为512bit,每个时钟周期内可打包32 次双精度或64 次单精度浮点运算,因此在图像/ 音视频处理、数据分析、科学计算、数据加密和压缩和 深度学习 等应用场景中,会带来更强大的性能表现,理论上浮点性能翻倍,整数计算则增加约33% 的性能。
Linus Torvalds :
AVX512 有很明显的缺点。我宁愿看到那些晶体管被用于其他更相关的事情。即使同样是用于进行浮点数学运算(通过 GPU 来做,而不是通过 AVX512 在 CPU 上),或者直接给我更多的核心(有着更多单线程性能,而且没有 AVX512 这样的垃圾),就像 AMD 所做的一样。
我希望通过常规的整数代码来达到自己能力的极限,而不是通过 AVX512 这样的功率病毒来达到最高频率(因为人们最终还是会拿它来做 memory-to-memory copy),还占据了核心的很大面积。
关于性能提升的小结
所以今天的2.6G单核skylake,能秒掉20年前2.6G的酷睿, 尤其是复杂场景。

CPU能耗公式:
P = C VV f
C是常数,f就是频率,V 电压。 f频率加大后因为充放电带来的Gate Delay,也就是频率增加,充放电时间短,为了保证信号的完整性就一定要增加电压来加快充放电。
所以最终能耗和f频率是 f^3 的指数关系。
The successive nodes of CMOS technologies lead to x1.4 decrease of the gate delays. It led to a 25% increase per year of clock frequencies from 740 kHz (Intel 4004) to 3 GHz (Intel Xeons with 45-nm nodes).
每一代光刻工艺的改进可以降低1.4倍的门延迟
即使不考虑散热问题,Core也没法做到无限大,目前光刻机都有最大加工尺寸限制。光刻机加工的最大尺寸,一般是 858mm²,而 Cerebras 和台积电紧密合作,做了一个 46255mm²,1.2T 个晶体管的世界第一大芯片。这也是超摩尔定律的一个突破。

主频和外频
主频=外频×倍频系数
不只是CPU需要一个切换频率,像GPU、cache、内存都需要一个外频来指导他们的电压脉冲的切换频率。CPU的发展比其它设备快,所以没法统一一个,于是就各自在外频的基础上X倍频系数。
超频:认为加大CPU的倍频系数,切换变快以后最大的问题是电容在短时间内充电不完整,这样导致信号失真,所以一般配套需要增加电压(充电更快),带来的后果是温度更高。
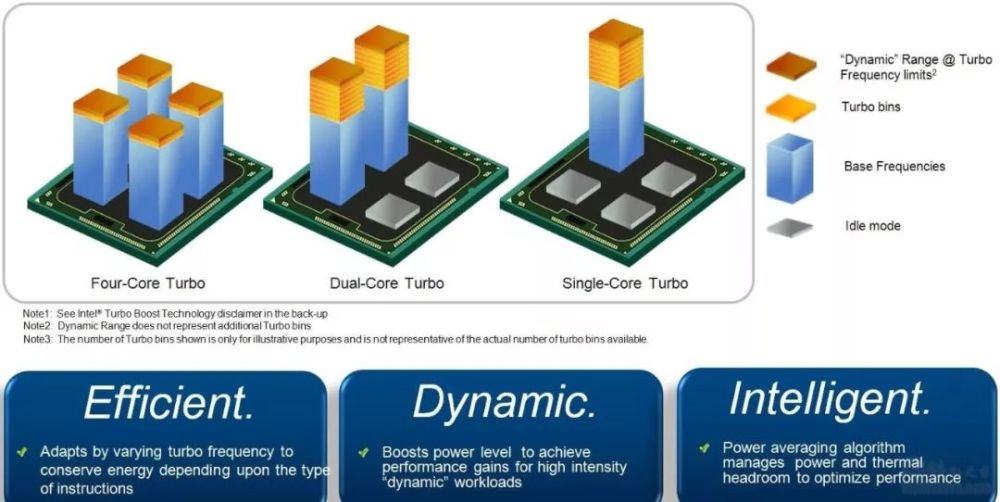
睿频:大多时候多核用不上,如果能智能地关掉无用的核同时把这些关掉的核的电源累加到在用的核上(通过增加倍频来实现),这样单核拥有更高的主频。也就是把其它核的电源指标和发热指标给了这一个核来使用。
多core通讯和NUMA
uma下cpu访问内存
早期core不多统一走北桥总线访问内存,对所有core时延统一
NUMA
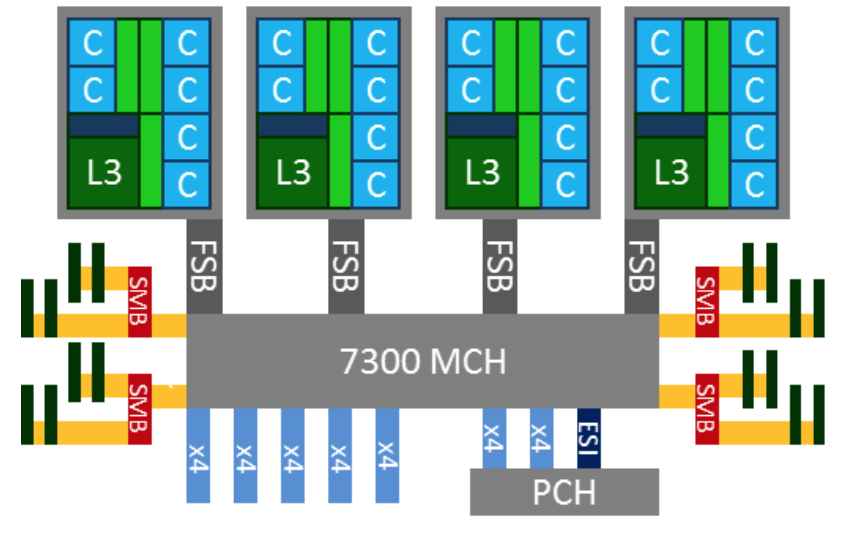
如下图,左右两边的是内存条,每个NUMA的cpu访问直接插在自己CPU上的内存必然很快,如果访问插在其它NUMA上的内存条还要走QPI,所以要慢很多。

如上架构是4路CPU,每路之间通过QPI相连,每个CPU内部8core用的是双Ring Bus相连,Memory Control Hub集成到了Die里面。一路CPU能连4个SMB,每个SMB有两个channel,每个channel最多接三个内存条(图中只画了2个)。
快速通道互联[1][2](英语:Intel QuickPath Interconnect,缩写:QPI)[3][4],是一种由英特尔开发并使用的点对点处理器互联架构,用来实现CPU之间的互联。英特尔在2008年开始用QPI取代以往用于至强、安腾处理器的前端总线(FSB),用来实现芯片之间的直接互联,而不是再通过FSB连接到北桥。Intel于2017年发布的SkyLake-SP Xeon中,用UPI(UltraPath Interconnect)取代QPI。
Ring Bus
2012年英特尔发布了业界期待已久的Intel Sandy Bridge架构至强E5-2600系列处理器。该系列处理器采用 Intel Sandy Bridge微架构和32nm工艺,与前一代的至强5600系列相比,具有更多的内核、更大的缓存、更多的内存通道,Die内采用的是Ring Bus。
Ring Bus设计简单,双环设计可以保证任何两个ring stop之间距离不超过Ring Stop总数的一半,延迟控制在60ns,带宽100G以上,但是core越多,ring bus越长性能下降迅速,在12core之后性能下降明显。
于是采用如下两个Ring Bus并列,然后再通过双向总线把两个Ring Bus连起来。
在至强HCC(High Core Count, 核很多版)版本中,又加入了一个ring bus。两个ring bus各接12个Core,将延迟控制在可控的范围内。俩个Ring Bus直接用两个双向Pipe Line连接,保证通讯顺畅。与此同时由于Ring 0中的模块访问Ring 1中的模块延迟明显高于本Ring,亲缘度不同,所以两个Ring分属于不同的NUMA(Non-Uniform Memory Access Architecture)node。这点在BIOS设计中要特别注意。
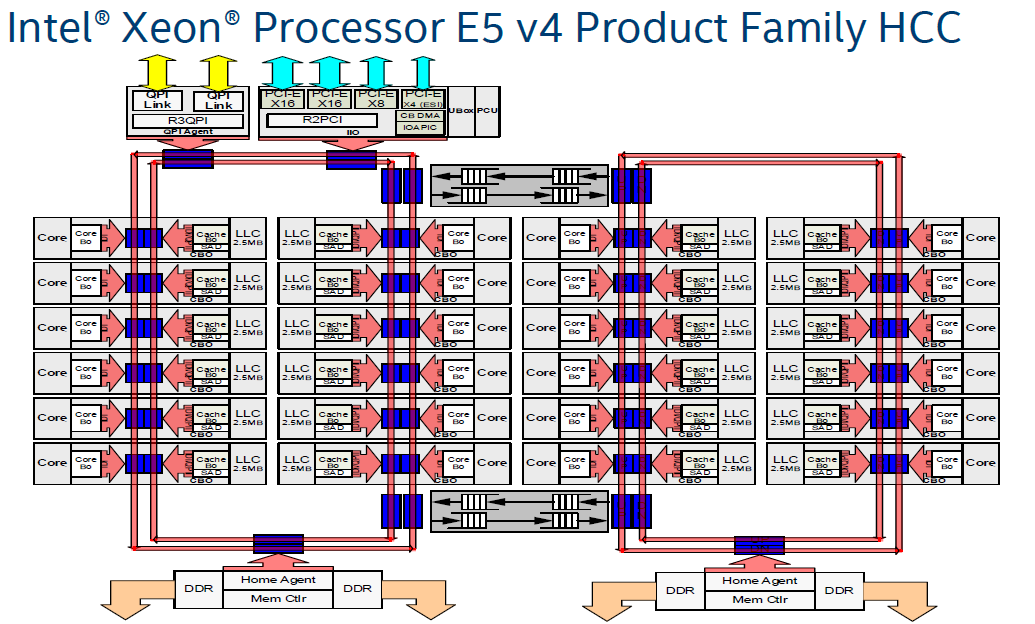
或者这个更清晰点的图:

Mesh网络
Intel在Skylake和Knight Landing中引入了新的片内总线:Mesh。它是一种2D的Mesh网络:
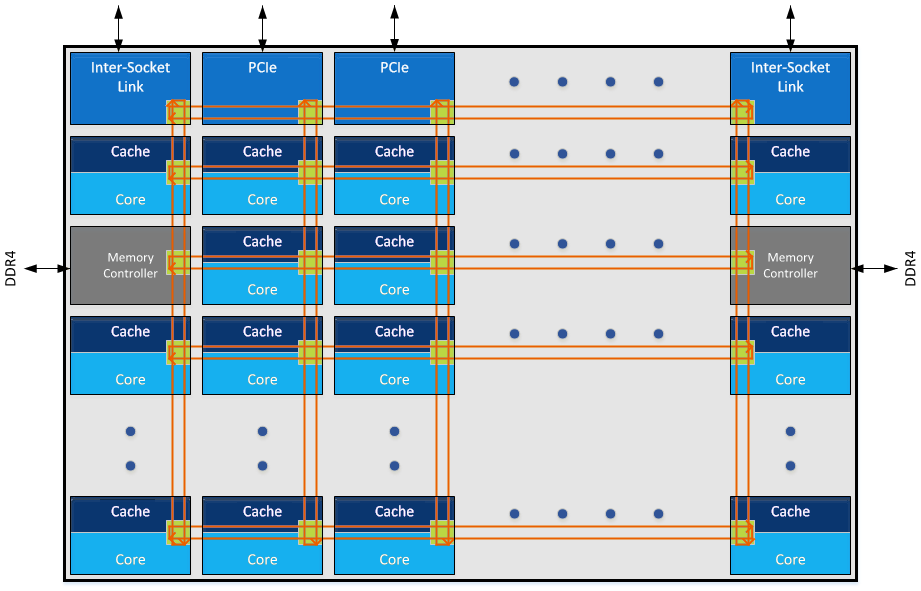
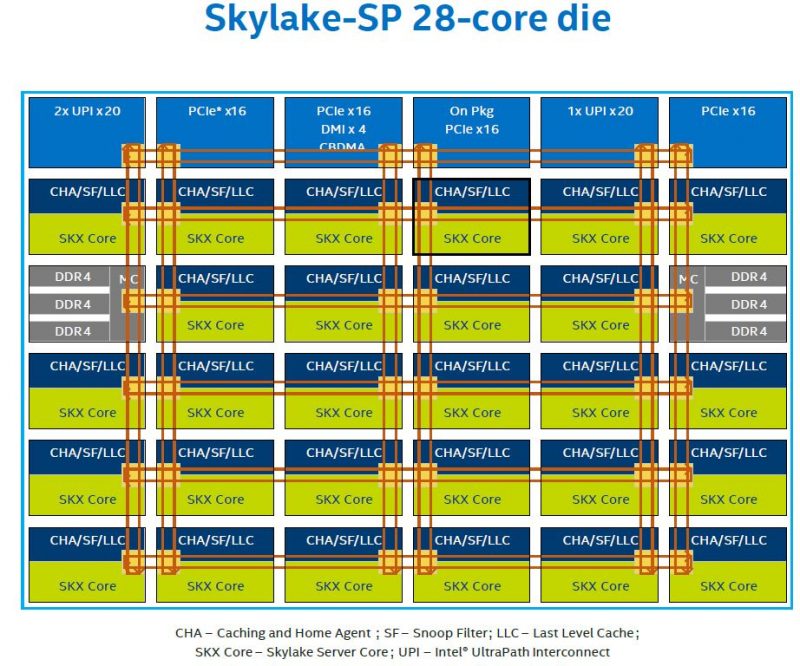
一个skylake 28core die的实现:
Mesh网络引入片内总线是一个巨大的进步,它有很多优点:
- 首先当然是灵活性。新的模块或者节点在Mesh中增加十分方便,它带来的延迟不是像ring bus一样线性增加,而是非线性的。从而可以容纳更多的内核。
- 设计弹性很好,不需要1.5 ring和2ring的委曲求全。
- 双向mesh网络减小了两个node之间的延迟。过去两个node之间通讯,最坏要绕过半个ring。而mesh整体node之间距离大大缩减。
- 外部延迟大大缩短
RAM延迟大大缩短:
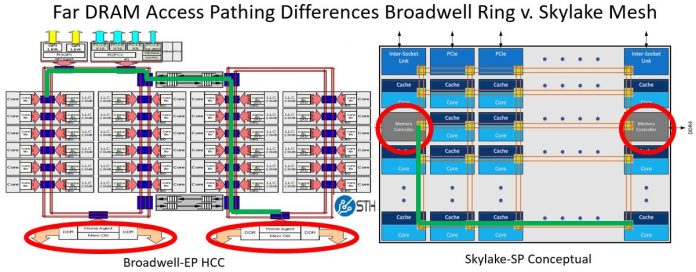
上图左边的是ring bus,从一个ring里面访问另一个ring里面的内存控制器。最坏情况下是那条绿线,拐了一个大圈才到达内存控制器,需要310个cycle。而在Mesh网络中则路径缩短很多。
Mesh网络带来了这么多好处,那么缺点有没有呢?网格化设计带来复杂性的增加,从而对Die的大小带来了负面影响
CPU的总线为铜薄膜,虽然摩尔定律使单位面积晶体管的密度不断增加,但是对于连接导线的电阻却没有明显的下降,导线的RC延迟几乎决定现有CPU性能,因此数据传输在CPU的角度来看是个极为沉重的负担。 虽然2D-mesh为数据提供了更多的迁移路径减少了数据堵塞,但也同样为数据一致性带来更多问题,例如过去ring-bus 结构下对于存在于某个CPU私用缓存的数据争抢请求只有两个方向(左和右), 但是在2D-mesh环境下会来自于4个方向(上,下,左,右)

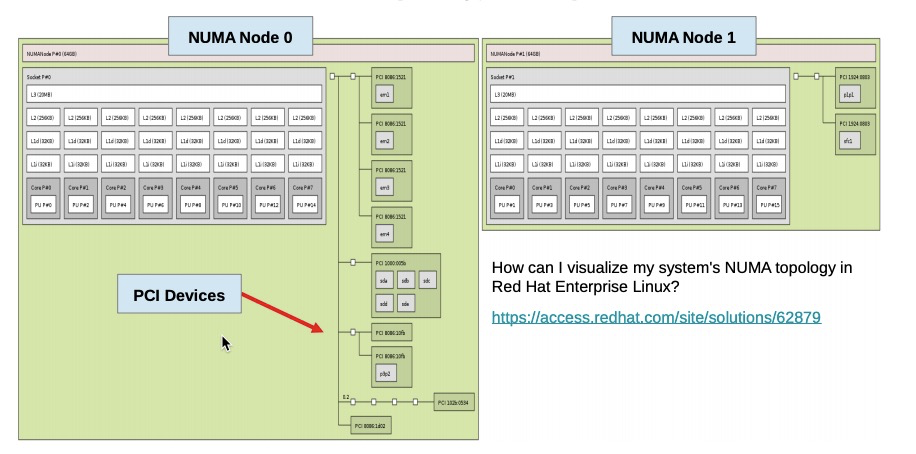
SUB_NUMA Cluster(SNC)
在intel 8269的CPU中,core比较多,core之间通信采取的是mesh架构,实际在BIOS中的NUMA NODE设置上,还有个sub_numa的设置,开启后,一个Die拆成了两个node

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
[root@registry Linux]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 104
On-line CPU(s) list: 0-103
Thread(s) per core: 2
Core(s) per socket: 26
座: 2
NUMA 节点: 4
厂商 ID: GenuineIntel
CPU 系列: 6
型号: 85
型号名称: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
步进: 7
CPU MHz: 1200.000
CPU max MHz: 2501.0000
CPU min MHz: 1200.0000
BogoMIPS: 5000.00
虚拟化: VT-x
L1d 缓存: 32K
L1i 缓存: 32K
L2 缓存: 1024K
L3 缓存: 36608K
NUMA 节点0 CPU: 0-3,7-9,13-15,20-22,52-55,59-61,65-67,72-74
NUMA 节点1 CPU: 4-6,10-12,16-19,23-25,56-58,62-64,68-71,75-77
NUMA 节点2 CPU: 26-29,33-35,39-41,46-48,78-81,85-87,91-93,98-100
NUMA 节点3 CPU: 30-32,36-38,42-45,49-51,82-84,88-90,94-97,101-103
|
不过在8269上开启sub_numa对性能的影响不是特别大,mlc测试如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
|
[root@registry Linux]# ./mlc
Intel(R) Memory Latency Checker - v3.9
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1 2 3
0 77.3 81.6 129.8 136.1
1 82.1 78.1 134.1 137.6
2 129.8 135.8 73.5 81.7
3 134.4 137.7 81.7 78.5
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 232777.7
3:1 Reads-Writes : 216680.7
2:1 Reads-Writes : 213856.4
1:1 Reads-Writes : 197430.7
Stream-triad like: 194310.3
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0 1 2 3
0 58908.9 59066.0 50548.0 50479.6
1 59111.3 58882.6 50539.0 50479.3
2 50541.7 50495.8 58950.2 58934.0
3 50526.3 50492.4 59171.9 58701.5
Measuring Loaded Latencies for the system
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Inject Latency Bandwidth
Delay (ns) MB/sec
==========================
00000 242.78 232249.0
00002 242.90 232248.8
00008 242.63 232226.0
00015 247.47 233159.0
00050 250.26 233489.7
00100 245.88 233253.4
00200 109.72 183071.9
00300 93.95 128676.2
00400 88.51 98678.4
00500 85.15 80026.2
00700 83.74 58136.1
01000 82.16 41372.4
01300 81.59 32184.0
01700 81.14 24896.1
02500 80.80 17248.5
03500 80.32 12571.3
05000 79.58 9060.5
09000 78.27 5411.6
20000 76.09 2911.5
Measuring cache-to-cache transfer latency (in ns)...
Local Socket L2->L2 HIT latency 45.0
Local Socket L2->L2 HITM latency 45.1
Remote Socket L2->L2 HITM latency (data address homed in writer socket)
Reader Numa Node
Writer Numa Node 0 1 2 3
0 - 48.2 107.2 109.2
1 50.6 - 111.2 113.1
2 107.6 109.6 - 48.0
3 111.6 113.5 49.7 -
Remote Socket L2->L2 HITM latency (data address homed in reader socket)
Reader Numa Node
Writer Numa Node 0 1 2 3
0 - 48.6 169.1 175.0
1 46.3 - 167.9 172.1
2 171.4 175.3 - 48.6
3 169.7 173.6 45.1 -
[root@registry Linux]# numactl -H
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 7 8 9 13 14 15 20 21 22 52 53 54 55 59 60 61 65 66 67 72 73 74
node 0 size: 64162 MB
node 0 free: 60072 MB
node 1 cpus: 4 5 6 10 11 12 16 17 18 19 23 24 25 56 57 58 62 63 64 68 69 70 71 75 76 77
node 1 size: 65536 MB
node 1 free: 63575 MB
node 2 cpus: 26 27 28 29 33 34 35 39 40 41 46 47 48 78 79 80 81 85 86 87 91 92 93 98 99 100
node 2 size: 65536 MB
node 2 free: 63834 MB
node 3 cpus: 30 31 32 36 37 38 42 43 44 45 49 50 51 82 83 84 88 89 90 94 95 96 97 101 102 103
node 3 size: 65536 MB
node 3 free: 63867 MB
node distances:
node 0 1 2 3
0: 10 11 21 21
1: 11 10 21 21
2: 21 21 10 11
3: 21 21 11 10
[root@registry Linux]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 104
On-line CPU(s) list: 0-103
Thread(s) per core: 2
Core(s) per socket: 26
座: 2
NUMA 节点: 4
厂商 ID: GenuineIntel
CPU 系列: 6
型号: 85
型号名称: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
步进: 7
CPU MHz: 1200.000
CPU max MHz: 2501.0000
CPU min MHz: 1200.0000
BogoMIPS: 5000.00
虚拟化: VT-x
L1d 缓存: 32K
L1i 缓存: 32K
L2 缓存: 1024K
L3 缓存: 36608K
NUMA 节点0 CPU: 0-3,7-9,13-15,20-22,52-55,59-61,65-67,72-74
NUMA 节点1 CPU: 4-6,10-12,16-19,23-25,56-58,62-64,68-71,75-77
NUMA 节点2 CPU: 26-29,33-35,39-41,46-48,78-81,85-87,91-93,98-100
NUMA 节点3 CPU: 30-32,36-38,42-45,49-51,82-84,88-90,94-97,101-103
|
| SKL-SP H0 | SKL-SP H0 | SKL-SP H0 | SKL-SP H0 | |
|---|---|---|---|---|
| DDR4 speed MT/s (32GB RDIMMs) | 2666 | 2666 | 2400 | 2400 |
| Page Policy | Adaptive | Adaptive | Adaptive | Adaptive |
| SNC (sub-NUMA cluster) | disabled | enabled | disabled | enabled |
| Uncore frequency (Mhz) | 2400 | 2400 | 2400 | 2400 |
| L1 cache latency (nsec) | 1.1 | 1.1 | 1.1 | 1.1 |
| L2 cache latency (nsec) | 4.7 | 4.6 | 4.7 | 4.6 |
| L3 cache latency (nsec) | 19.5 | 17.8 | 19.5 | 17.8 |
| Local mem latency (nsec) | 83 | 81 | 85 | 83 |
| Remote mem latency (nsec) | 143 | 139 | 145 | 141 |
uncore
“Uncore“ is a term used by Intel to describe the functions of a microprocessor that are not in the core, but which must be closely connected to the core to achieve high performance.[1] It has been called “system agent“ since the release of the Sandy Bridge microarchitecture.[2]
The core contains the components of the processor involved in executing instructions, including the ALU, FPU, L1 and L2 cache. Uncore functions include QPI controllers, L3 cache, snoop agent pipeline, on-die memory controller, on-die PCI Express Root Complex, and Thunderbolt controller).[3] Other bus controllers such as SPI and LPC are part of the chipset.[4]
一些Intel CPU NUMA结构参考
Intel Xeon Platinum 8163(Skylake)阿里云第四代服务器采用的CPU,Skylake架构,主频2.5GHz,计算性能问题。8163这款型号在intel官网上并没有相关信息,应该是阿里云向阿里云定制的,与之相近的Intel Xeon Platinum 8168,价格是$5890,约合¥38900元。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
|
lscpu:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz
Stepping: 6
CPU MHz: 2400.000
CPU max MHz: 3900.0000
CPU min MHz: 1000.0000
BogoMIPS: 4800.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-3,7-9,13-15,19,20,48-51,55-57,61-63,67,68
NUMA node1 CPU(s): 4-6,10-12,16-18,21-23,52-54,58-60,64-66,69-71
NUMA node2 CPU(s): 24-27,31-33,37-39,43,44,72-75,79-81,85-87,91,92
NUMA node3 CPU(s): 28-30,34-36,40-42,45-47,76-78,82-84,88-90,93-95
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8268 CPU @ 2.90GHz
Stepping: 6
CPU MHz: 3252.490
BogoMIPS: 5800.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s):
0,4,8,12,16,20,24,28,32,36,40,44,48,52,56,60,64,68,72,76,80,84,88,92
NUMA node1 CPU(s):
1,5,9,13,17,21,25,29,33,37,41,45,49,53,57,61,65,69,73,77,81,85,89,93
NUMA node2 CPU(s):
2,6,10,14,18,22,26,30,34,38,42,46,50,54,58,62,66,70,74,78,82,86,90,94
NUMA node3 CPU(s):
3,7,11,15,19,23,27,31,35,39,43,47,51,55,59,63,67,71,75,79,83,87,91,95
lscpu:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 192
On-line CPU(s) list: 0-191
Thread(s) per core: 1
Core(s) per socket: 24
Socket(s): 8 //每个物理CPU 24个物理core,这24个core应该是分布在2个Die中
NUMA node(s): 16
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz
Stepping: 7
CPU MHz: 2400.000
CPU max MHz: 3900.0000
CPU min MHz: 1000.0000
BogoMIPS: 4800.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-3,7-9,13-15,19,20
NUMA node1 CPU(s): 4-6,10-12,16-18,21-23
NUMA node2 CPU(s): 24-27,31-33,37-39,43,44
NUMA node3 CPU(s): 28-30,34-36,40-42,45-47
NUMA node4 CPU(s): 48-51,55,56,60-62,66-68
NUMA node5 CPU(s): 52-54,57-59,63-65,69-71
NUMA node6 CPU(s): 72-75,79-81,85-87,91,92
NUMA node7 CPU(s): 76-78,82-84,88-90,93-95
NUMA node8 CPU(s): 96-99,103,104,108-110,114-116
NUMA node9 CPU(s): 100-102,105-107,111-113,117-119
NUMA node10 CPU(s): 120-123,127,128,132-134,138-140
NUMA node11 CPU(s): 124-126,129-131,135-137,141-143
NUMA node12 CPU(s): 144-147,151-153,157-159,163,164
NUMA node13 CPU(s): 148-150,154-156,160-162,165-167
NUMA node14 CPU(s): 168-171,175-177,181-183,187,188
NUMA node15 CPU(s): 172-174,178-180,184-186,189-191
//v62
#lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 104
On-line CPU(s) list: 0-103
Thread(s) per core: 2
Core(s) per socket: 26
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
Stepping: 7
CPU MHz: 3200.097
CPU max MHz: 3800.0000
CPU min MHz: 1200.0000
BogoMIPS: 4998.89
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-25,52-77
NUMA node1 CPU(s): 26-51,78-103
//2016Intel开始出售Intel Xeon E5-2682 v4。 这是一种基于Broadwell架构的桌面处理器,主要为办公系统而设计。 它具有16 核心和32 数据流并使用, 售价约为7000人民币
#lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
Stepping: 1
CPU MHz: 2499.902
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 5000.06
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 40960K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch ida arat epb invpcid_single pln pts dtherm spec_ctrl ibpb_support tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt rdseed adx smap xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local cat_l3
|
intel 架构迭代
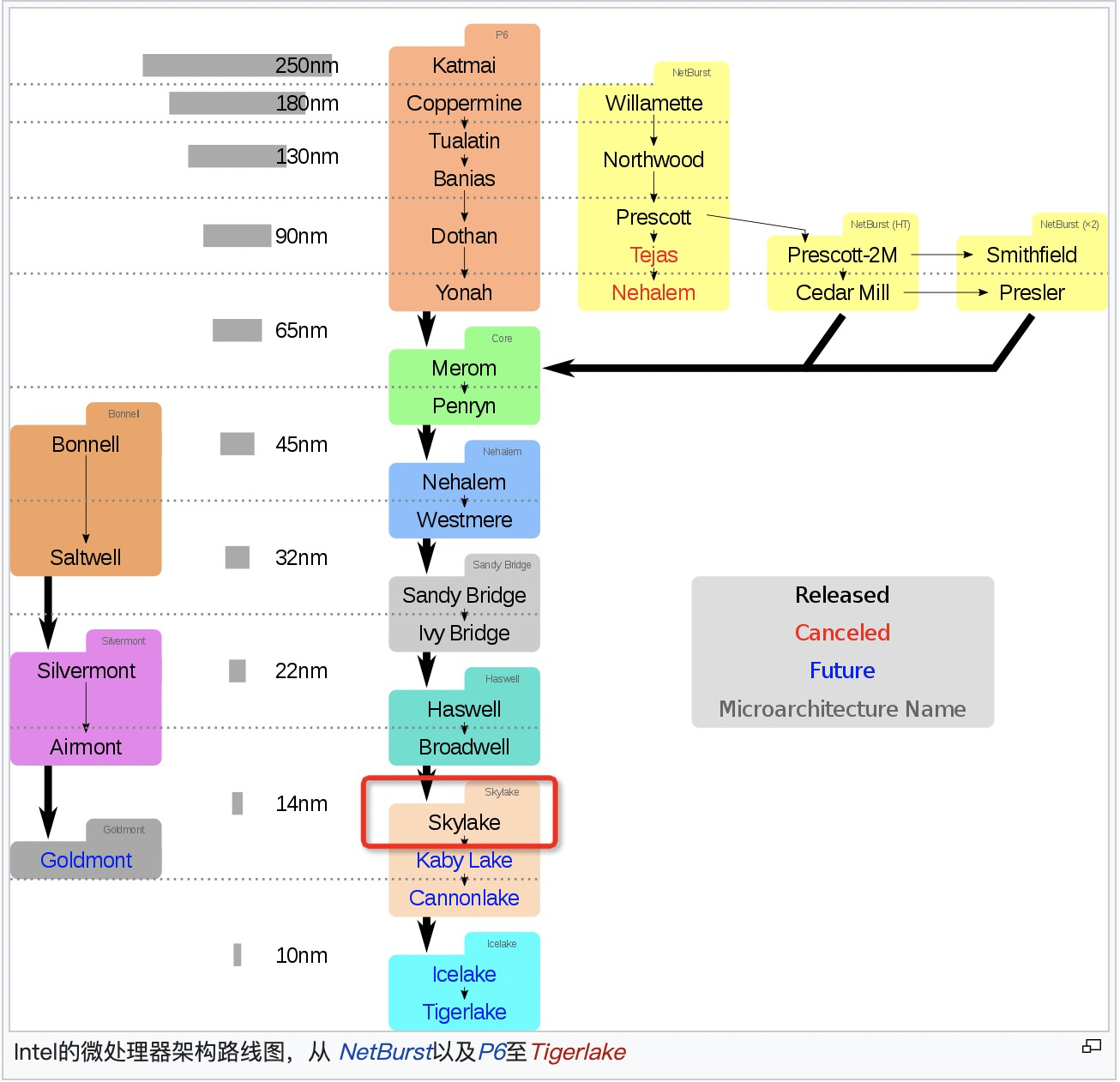
2006年90、65纳米工艺酷睿core Yonah上市,32位架构,仍然算是奔腾Pro系列;2006推出酷睿处理器是介于NetBurst和Core之间,其实是NetBurst的改版,Core 2是第一个基于Core架构的原生双核处理器,65nm工艺,使得AMD K8架构优势全无,直接投入开发原生四核架构K10去了。
2006年7月酷睿2处理器代号为“Conroe”,采用x86-64指令集与65纳米双核心架构。该处理器基于全新的酷睿微架构,虽然时脉大大降低,但在效率方面和性能方面有了重大改进。从这一时期开始,在深度流水线和资源混乱的运行引擎上维持每个周期的高指令(IPC)
2008年的 Nehalem (酷睿i7)是采用 45nm 工艺的新架构,主要优势来自重新设计的I/O和存储系统,这些系统具有新的Intel QuickPath Interconnect和集成的内存控制器,可支持三通道的DDR3内存。引入片内4-12MB的L3 Cache;重新加入超线程;分支预测分级;取消北桥,IMC(集成内存控制器)从北桥挪到片内
2009年的 Westmere 升级到 32nm;退出第一代I5/I3,Xeon 系列也开始推出第一代E命名的E7-x8xx系列。
2010年的 Lynnfield/Clarkdale 基于 45nm/32nm 工艺的新架构,第一代智能酷睿处理器;
2011年的 Sandy Bridge ,基于 32nm 工艺的新架构,第二代智能酷睿处理器,增加AVX指令集扩展, 对虚拟化提供更好支持;实现了GPU和CPU的融合
2012年的 IVY Bridge,是 Sandy Bridge 的 22nm 升级版,第三代智能酷睿处理器,Tick级改进;
2013年的 Haswell ,基于 22nm 工艺的新架构,第四代智能酷睿处理器,Tock级改进;
2014年的 Broadwell,是 Haswell 的 14nm 升级版,第五代智能酷睿处理器;
2015年则推出 SkyLake,基于 14nm 工艺的新架构, Tock级改进,Ring-Bus改成了Mesh架构,第6代Core i系列,8163就是这款;socket之间UPI互联,内存频率通道增强。不再使用Xeon命名,而是改用Bronze/Silver/Gold/Platinum 4个系列。青铜和白银系列支持双路(原本的 E5-24xx、E7-28xx 系列),黄金系列支持四路(原本的 E5-46xx、E7-48xx 系列),白金系列支持八路(原本的 E7-88xx 系列);
2019年的Cascade Lake(X2XX命名)也是Skylake的优化,是Intel首个支持基于3D XPoint的内存模块的微体系结构。同年也正式宣布了十代酷睿处理器,即i9-10900k,还是Skylake微内核不变。
2020年的10nm Ice Lake自家工厂无能,改由台积电加工。
Core 架构代号是 Yonah,把 NetBurst 做深了的流水线级数又砍下来了,主频虽然降下来了(而且即使后来工艺提升到 45nm 之后也没有超过 NetBurst 的水平),但是却提高了整个流水线中的资源利用率,所以性能还是提升了;把奔腾 4 上曾经用过的超线程也砍掉了;对各个部分进行了强化,双核共享 L2 cache 等等。
从 Core 架构开始是真的走向多核了,就不再是以前 “胶水粘的” 伪双核了,这时候已经有最高 4 核的处理器设计了。
Core 从 65nm 改到 45nm 之后,基于 45nm 又推出了新一代架构叫 Nehalem,新架构Nehalem采用 Intel QPI 来代替原来的前端总线,PCIE 和 DMI 控制器直接做到片内了,不再需要北桥。
2006年Intel也提出了Tick-Tock架构战略。Tick年改进制程工艺,微架构基本不做大改,重点在把晶体管的工艺水平往上提升;Tock年改进微架构设计,保持工艺水平不变,重点在用更复杂、更高级的架构设计。然后就是一代 Tick 再一代 Tock交替演进。
从2006年酷睿架构开始,基本是摁着AMD在地上摩擦,直到2017年的AMD Zen杀回来,性能暴增。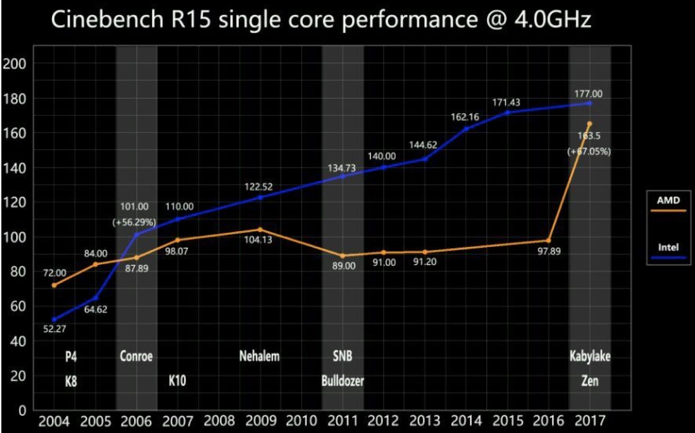
Sandy Bridge 引入核间的ring bus
感觉Broadwell前面这几代都是在优化cache、通信;接下来的Broadwell和SkyLake就开始改进不大了,疯狂挤牙膏(唯一比较大的改进就是Ring bus到Mesh)

命名规律
Intel E3、E5、E7代表了3个不同档次的至强CPU。EX是按性能和应用场景分的,以前是E3 E5 E7,E3核最少,轻负载应用,E5 核多均衡型,E7是超高性能,核最多。Xeon E5是针对高端工作站及服务器的处理器系列,此系列每年更新,不过架构落后Xeon E3一代。从skylake开始,不再使用EX(E3/E5/E7)了,而是铜、银、金、铂金四种组合。
V2 是ivy bridge,V3 是 haswell, V4 是broadwell,不带VX的是sandy bridge。所以2682是boradwell系列CPU。
然后到了4114,就是Silver,8186就是Platinum,81是skylake,82是cscadelake,再下一代是83。

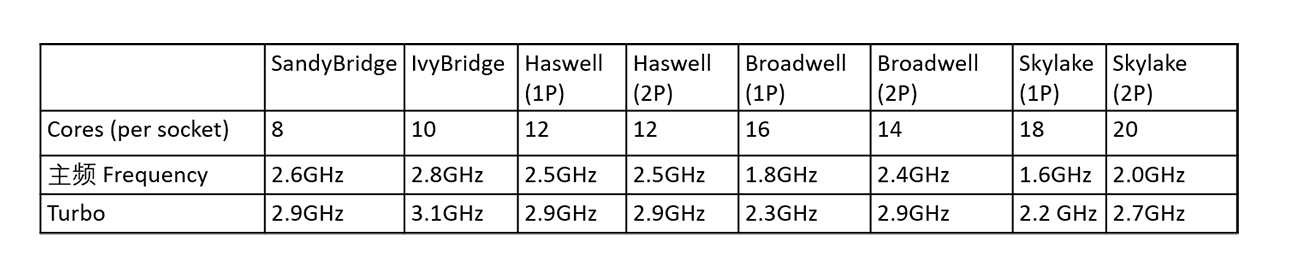
不同的架构下的参数
UEFI和Bios
UEFI,全称Unified Extensible Firmware Interface,即“统一的可扩展固件接口”,是一种详细描述全新类型接口的标准,是适用于电脑的标准固件接口,旨在代替BIOS(基本输入/输出系统)
电脑中有一个BIOS设置,它主要负责开机时检测硬件功能和引导操作系统启动的功能。而UEFI则是用于操作系统自动从预启动的操作环境,加载到一种操作系统上从而节省开机时间。
UEFI启动是一种新的主板引导项,它被看做是bios的继任者。UEFI最主要的特点是图形界面,更利于用户对象图形化的操作选择。

UEFI 图形界面:

简单的来说UEFI启动是新一代的BIOS,功能更加强大,而且它是以图形图像模式显示,让用户更便捷的直观操作。
如今很多新产品的电脑都支持UEFI启动模式,甚至有的电脑都已抛弃BIOS而仅支持UEFI启动。这不难看出UEFI正在取代传统的BIOS启动。
UEFI固件通过ACPI报告给OS NUMA的组成结构,其中最重要的是SRAT(System Resource Affinity Table)和SLIT(System Locality Information Table)表。
socket
socket对应主板上的一个插槽,也可以简单理解为一块物理CPU。同一个socket对应着 /proc/cpuinfo 里面的physical id一样。
一个socket至少对应着一个或多个node/NUMA
GPU
GPU只处理有限的计算指令(主要是浮点运算–矩阵操作),不需要分支预测、乱序执行等,所以将Core里面的电路简化(如下图左边),同时通过SIMT(Single Instruction,Multiple Threads, 类似 SIMD)在取指令和指令译码的阶段,取出的指令可以给到后面多个不同的 ALU 并行进行运算。这样,我们的一个 GPU 的核里,就可以放下更多的 ALU,同时进行更多的并行运算了(如下图右边) 。 在 SIMD 里面,CPU 一次性取出了固定长度的多个数据,放到寄存器里面,用一个指令去执行。而 SIMT,可以把多条数据,交给不同的线程去处理。

GPU的core在流水线stall的时候和超线程一样,可以调度别的任务给ALU,既然要调度一个不同的任务过来,我们就需要针对这个任务,提供更多的执行上下文。所以,一个 Core 里面的执行上下文的数量,需要比 ALU 多。
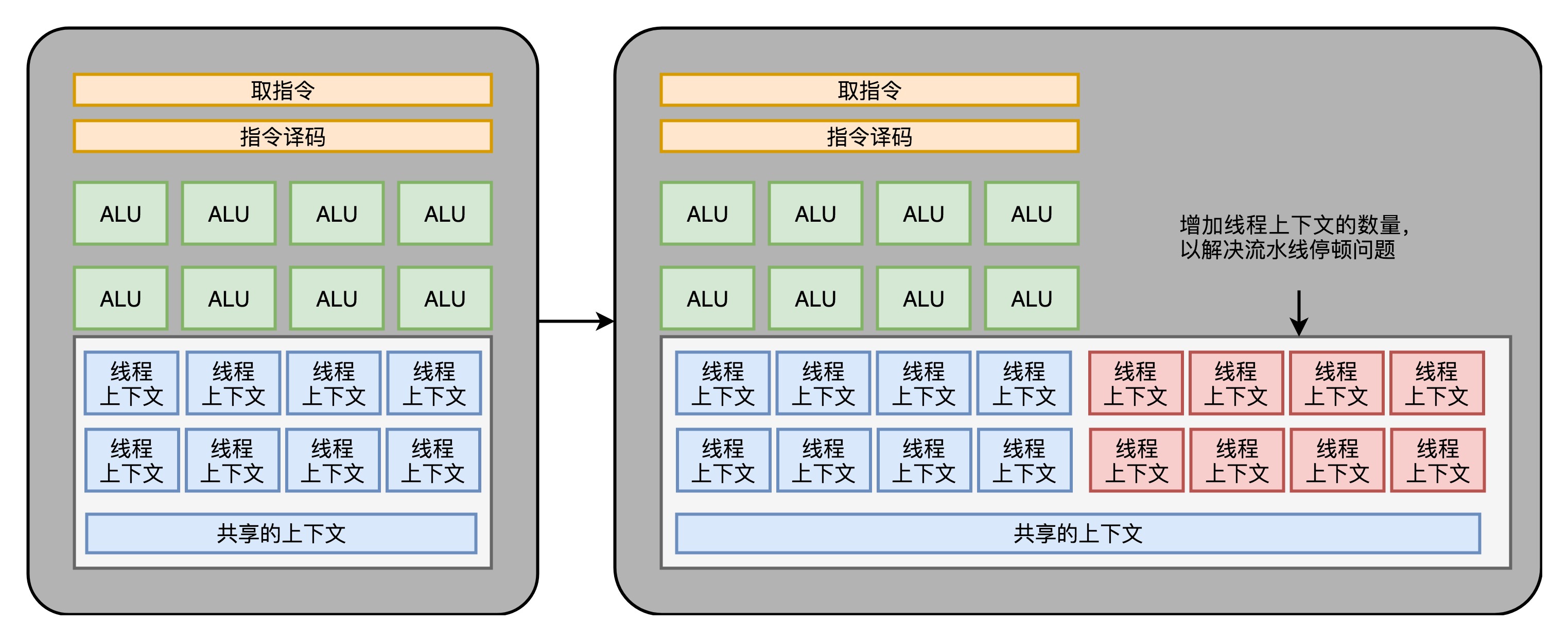
在通过芯片瘦身、SIMT 以及更多的执行上下文,我们就有了一个更擅长并行进行暴力运算的 GPU。这样的芯片,也正适合我们今天的深度学习和挖矿的场景。
NVidia 2080 显卡的技术规格,就可以算出,它到底有多大的计算能力。2080 一共有 46 个 SM(Streaming Multiprocessor,流式处理器),这个 SM 相当于 GPU 里面的 GPU Core,所以你可以认为这是一个 46 核的 GPU,有 46 个取指令指令译码的渲染管线。每个 SM 里面有 64 个 Cuda Core。你可以认为,这里的 Cuda Core 就是我们上面说的 ALU 的数量或者 Pixel Shader 的数量,46x64 呢一共就有 2944 个 Shader。然后,还有 184 个 TMU,TMU 就是 Texture Mapping Unit,也就是用来做纹理映射的计算单元,它也可以认为是另一种类型的 Shader。

2080 的主频是 1515MHz,如果自动超频(Boost)的话,可以到 1700MHz。而 NVidia 的显卡,根据硬件架构的设计,每个时钟周期可以执行两条指令。所以,能做的浮点数运算的能力,就是:
(2944 + 184)× 1700 MHz × 2 = 10.06 TFLOPS
最新的 Intel i9 9900K 的性能是多少呢?不到 1TFLOPS。而 2080 显卡和 9900K 的价格却是差不多的。所以,在实际进行深度学习的过程中,用 GPU 所花费的时间,往往能减少一到两个数量级。而大型的深度学习模型计算,往往又是多卡并行,要花上几天乃至几个月。这个时候,用 CPU 显然就不合适了。
为什么GPU比CPU快
GPU拥有更多的计算单元
GPU像是大卡车,每次去内存取数据取得多,但是Latency高(AP);CPU像是法拉利,更在意处理速度而不是一次处理很多数据,所以CPU有多级cache,都是围绕速度在优化(TP)。在GPU中取数据和处理是流水线所以能消除高Latency。
GPU的每个core拥有更小更快的cache和registry,但是整个GPU的registry累加起来能比CPU大30倍,同时带宽也是后者的16倍
总之GPU相对于CPU像是一群小学生和一个大学教授一起比赛计算10以内的加减法。
英伟达的GPU出圈
2016年之前英伟达的营收和市值基本跟intel一致,但是2021 年 4 月中旬的数字,Intel 是英伟达的近 5 倍,但是如果论市值,英伟达是 Intel 的 1.5 倍。
GPGPU:点亮并行计算的科技树
2007 年,英伟达首席科学家 David Kirk 非常前瞻性地提出 GPGPU 的概念,把英伟达和 GPU 从单纯图形计算拓展为通用计算,强调并行计算,鼓励开发者用 GPU 做计算,而不是局限在图形加速这个传统的领域。GPGPU,前面这个 GP,就是 General Purpose 通用的意思。
CUDA(Compute Unified Device Architecture,统一计算架构),CUDA 不仅仅是一个 GPU 计算的框架,它对下抽象了所有的英伟达出品的 GPU,对上构建了一个通用的编程框架,它实质上制定了一个 GPU 和上层软件之间的接口标准。
在 GPU 市场的早期竞争中,英伟达认识到软硬件之间的标准的重要性,花了 10 年苦功,投入 CUDA 软件生态建设,把软硬件之间的标准,变成自己的核心竞争力。
英伟达可以说是硬件公司中软件做得最好的。同样是生态强大,Wintel 的生态是微软帮忙建的,ARM-Android 的生态是 Google 建的,而 GPU-CUDA 的生态是英伟达自建的。
这个标准有多重要?这么说吧,一流企业定标准,二流企业做品牌,三流企业做产品。在所有的半导体公司中,制定出软件与硬件之间的标准,而且现在还算成功的,只有 3 个,一个是 x86 指令集,一个是 ARM 指令集,还有一个就是 CUDA 了。
GPU 相对 CPU 的 TOPS per Watt(花费每瓦特电能可以获得的算力)的差异竞争优势,它的本质就是将晶体管花在计算上,而不是逻辑判断上
2020 年超级计算机 TOP500 更新榜单,可以看到 TOP10 的超级计算机中有 8 台采用了英伟达 GPU、InfiniBand 网络技术,或同时采用了两种技术。TOP500 榜单中,有 333 套(三分之二)采用了英伟达的技术。
挖矿和深度学习撑起了英伟达的市值。
现场可编程门阵列FPGA(Field-Programmable Gate Array)
设计芯片十分复杂,还要不断验证。
那么不用单独制造一块专门的芯片来验证硬件设计呢?能不能设计一个硬件,通过不同的程序代码,来操作这个硬件之前的电路连线,通过“编程”让这个硬件变成我们设计的电路连线的芯片呢?这就是FPGA
- P 代表 Programmable,这个很容易理解。也就是说这是一个可以通过编程来控制的硬件。
- G 代表 Gate 也很容易理解,它就代表芯片里面的门电路。我们能够去进行编程组合的就是这样一个一个门电路。
- A 代表的 Array,叫作阵列,说的是在一块 FPGA 上,密密麻麻列了大量 Gate 这样的门电路。
- 最后一个 F,不太容易理解。它其实是说,一块 FPGA 这样的板子,可以在“现场”多次进行编程。它不像 PAL(Programmable Array Logic,可编程阵列逻辑)这样更古老的硬件设备,只能“编程”一次,把预先写好的程序一次性烧录到硬件里面,之后就不能再修改了。
FPGA 通过“软件”来控制“硬件”
专用集成电路ASIC(Application-Specific Integrated Circuit)
为解决特定应用问题而定制设计的集成电路,就是 ASIC(Application Specific IC)。当 ASIC 规模够大,逐渐通用起来,某类 ASIC 就会有一个专有名称,成为一个品类。例如现在用来解决人工智能问题的神经网络处理器。
除了 CPU、GPU,以及刚刚的 FPGA,我们其实还需要用到很多其他芯片。比如,现在手机里就有专门用在摄像头里的芯片;录音笔里会有专门处理音频的芯片。尽管一个 CPU 能够处理好手机拍照的功能,也能处理好录音的功能,但是我们直接在手机或者录音笔里塞上一个 Intel CPU,显然比较浪费。
因为 ASIC 是针对专门用途设计的,所以它的电路更精简,单片的制造成本也比 CPU 更低。而且,因为电路精简,所以通常能耗要比用来做通用计算的 CPU 更低。而我们所说的早期的图形加速卡,其实就可以看作是一种 ASIC。
因为 ASIC 的生产制造成本,以及能耗上的优势,过去几年里,有不少公司设计和开发 ASIC 用来“挖矿”。这个“挖矿”,说的其实就是设计专门的数值计算芯片,用来“挖”比特币、ETH 这样的数字货币。
如果量产的ASIC比较小的话可以直接用FPGA来实现,FPGA介于ASIC和PLA之间,PLA(可编程控制器)太简单,直接上ASIC又过于复杂、能耗高、成本高。
张量处理器TPU (tensor processing unit)
张量处理器(英语:tensor processing unit,缩写:TPU)是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计。
在性能上,TPU 比现在的 CPU、GPU 在深度学习的推断任务上,要快 15~30 倍。而在能耗比上,更是好出 30~80 倍。另一方面,Google 已经用 TPU 替换了自家数据中心里 95% 的推断任务,可谓是拿自己的实际业务做了一个明证。
其它基础知识
晶振频率:控制CPU上的晶体管开关切换频率。一次晶振就是一个cycle。
从最简单的单指令周期 CPU 来说,其实时钟周期应该是放下最复杂的一条指令的时间长度。但是,我们现在实际用的都没有单指令周期 CPU 了,而是采用了流水线技术。采用了流水线技术之后,单个时钟周期里面,能够执行的就不是一个指令了。我们会把一条机器指令,拆分成很多个小步骤。不同的指令的步骤数量可能还不一样。不同的步骤的执行时间,也不一样。所以,一个时钟周期里面,能够放下的是最耗时间的某一个指令步骤。
不过没有pipeline,一条指令最少也要N个circle(N就是流水线深度);但是理想情况下流水线跑满的话一个指令也就只需要一个circle了,也就是IPC能到理论最大值1; 加上超标流水线一般IPC都能4,就是一般CPU的超标量。
制程:7nm、14nm、4nm都是指的晶体大小,用更小的晶体可以在相同面积CPU上集成更多的晶体数量,那么CPU的运算能力也更强。增加晶体管可以增加硬件能够支持的指令数量,增加数字通路的位数,以及利用好电路天然的并行性,从硬件层面更快地实现特定的指。打个比方,比如我们最简单的电路可以只有加法功能,没有乘法功能。乘法都变成很多个加法指令,那么实现一个乘法需要的指令数就比较多。但是如果我们增加晶体管在电路层面就实现了这个,那么需要的指令数就变少了,执行时间也可以缩短。
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
功耗和电压的平方是成正比的。这意味着电压下降到原来的 1/5,整个的功耗会变成原来的 1/25。
堆栈溢出:函数调用用压栈来保存地址、变量等相关信息。没有选择直接嵌套扩展代码是避免循环调用下嵌套是个无尽循环,inline函数内联就是一种嵌套代码扩展优化。
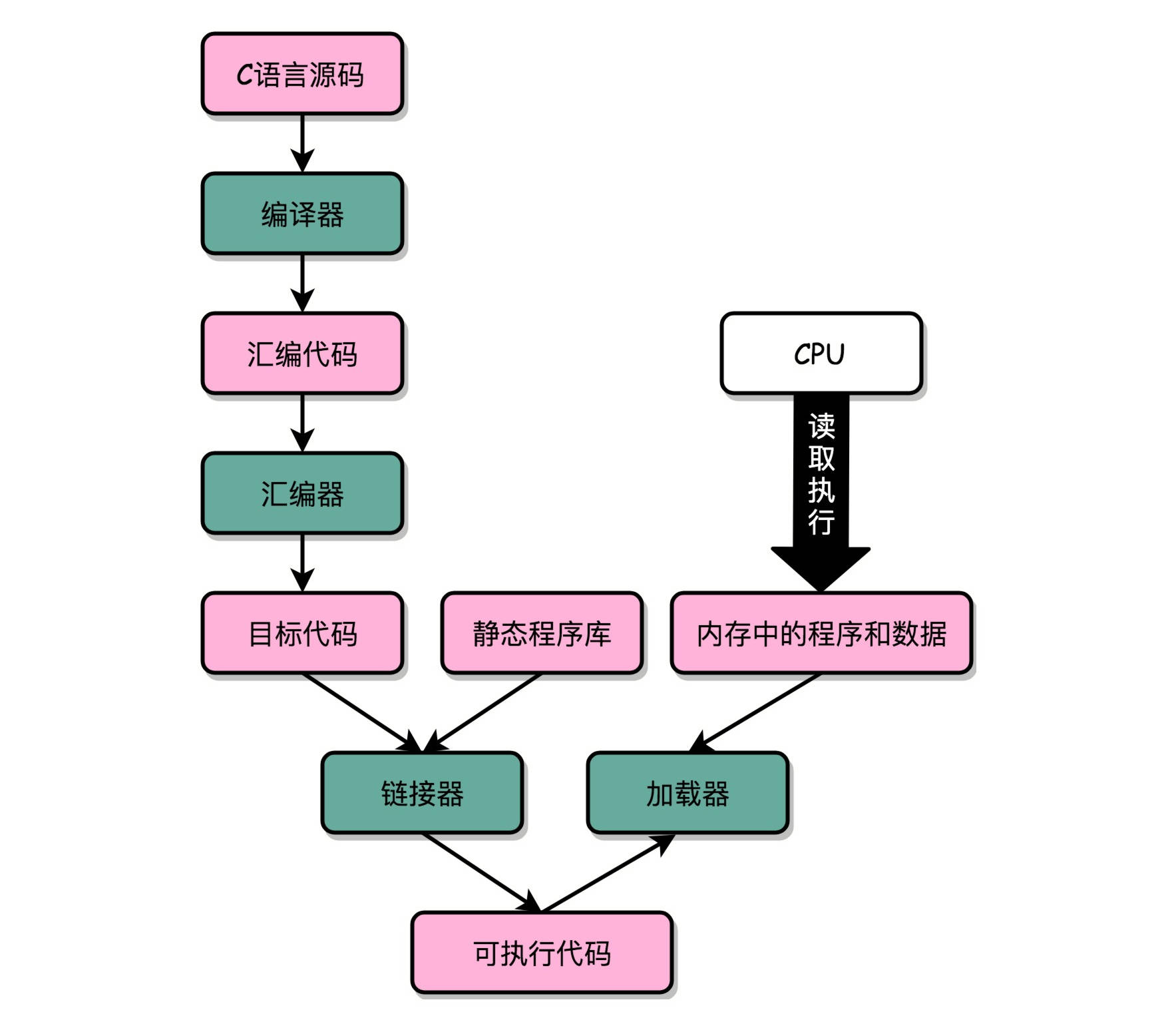
windows下的exe文件之所以没法放到linux上运行(都是intel x86芯片),是因为可执行程序要经过链接,将所依赖的库函数调用合并进来形成可执行文件。这个可执行文件在Linux 下的 ELF(Execuatable and Linkable File Format) 文件格式,而 Windows 的可执行文件格式是一种叫作 PE(Portable Executable Format)的文件格式。Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。而且windows和linux的库函数必然不一样,没法做到兼容。
链接器: 扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。
虚拟内存地址:应用代码可执行地址必须是连续,这也就意味着一个应用的内存地址必须连续,实际一个OS上会运行多个应用,没办法保证地址连续,所以可以通过虚拟地址来保证连续,虚拟地址再映射到实际零散的物理地址上(可以解决碎片问题),这个零散地址的最小组织形式就是Page。虚拟地址本来是连续的,使用一阵后数据部分也会变成碎片,代码部分是不可变的,一直连续。另外虚拟地址也方便了OS层面的库共享。
为了扩大虚拟地址到物理地址的映射范围同时又要尽可能少地节约空间,虚拟地址到物理地址的映射一般分成了四级Hash,这样4Kb就能管理256T内存。但是带来的问题就是要通过四次查找使得查找慢,这时引入TLAB来换成映射关系。
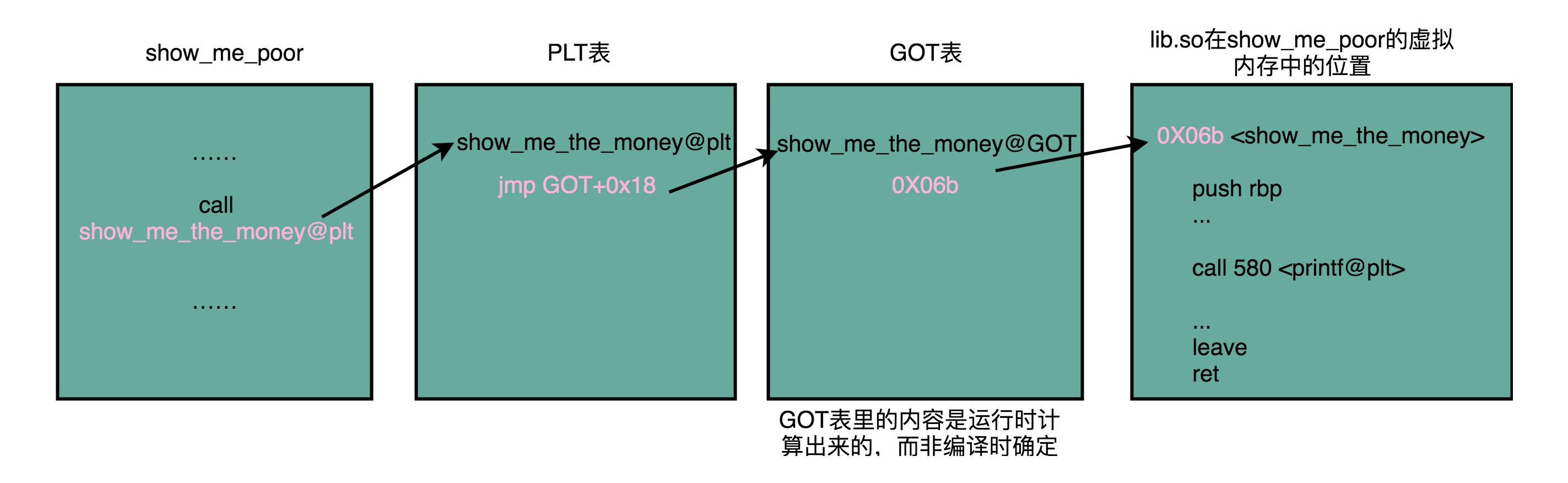
共享库:在 Windows 下,这些共享库文件就是.dll 文件,也就是 Dynamic-Link Libary(DLL,动态链接库)。在 Linux 下,这些共享库文件就是.so 文件,也就是 Shared Object(一般我们也称之为动态链接库). 不同的进程,调用同样的 lib.so,各自 全局偏移表(GOT,Global Offset Table) 里面指向最终加载的动态链接库里面的虚拟内存地址是不同的, 各个程序各自维护好自己的 GOT,能够找到对应的动态库就好了, 有点像函数指针。
符号表:/boot/System.map 和 /proc/kallsyms
超线程(Hyper-Threading): 在CPU内部增加寄存器等硬件设施,但是ALU、译码器等关键单元还是共享。在一个物理 CPU 核心内部,会有双份的 PC 寄存器、指令寄存器乃至条件码寄存器。超线程的目的,是在一个线程 A 的指令,在流水线里停顿的时候,让另外一个线程去执行指令。因为这个时候,CPU 的译码器和 ALU 就空出来了,那么另外一个线程 B,就可以拿来干自己需要的事情。这个线程 B 可没有对于线程 A 里面指令的关联和依赖。
宏观认识集成电路半导体行业
先从市场分布和市场占有率等几个行业宏观概念来了解半导体行业
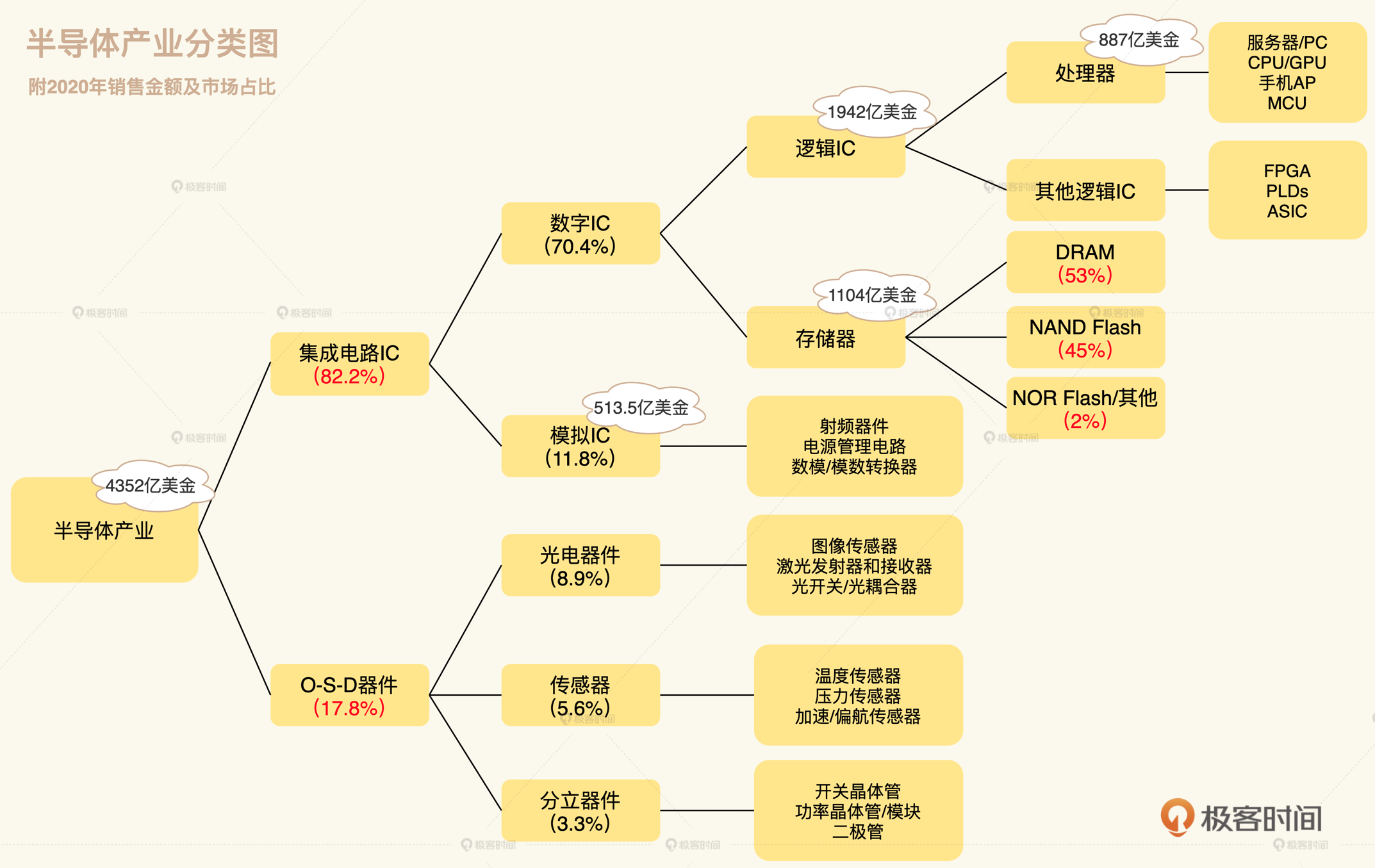
半导体产业的产值分布
下图中的处理器就是我们日常所说的CPU,当然还包含了GPU等
我们常说的内存、固态硬盘这些存储器也是数字IC,后面你会看到一个CPU core里面还会有用于存储的cache电路
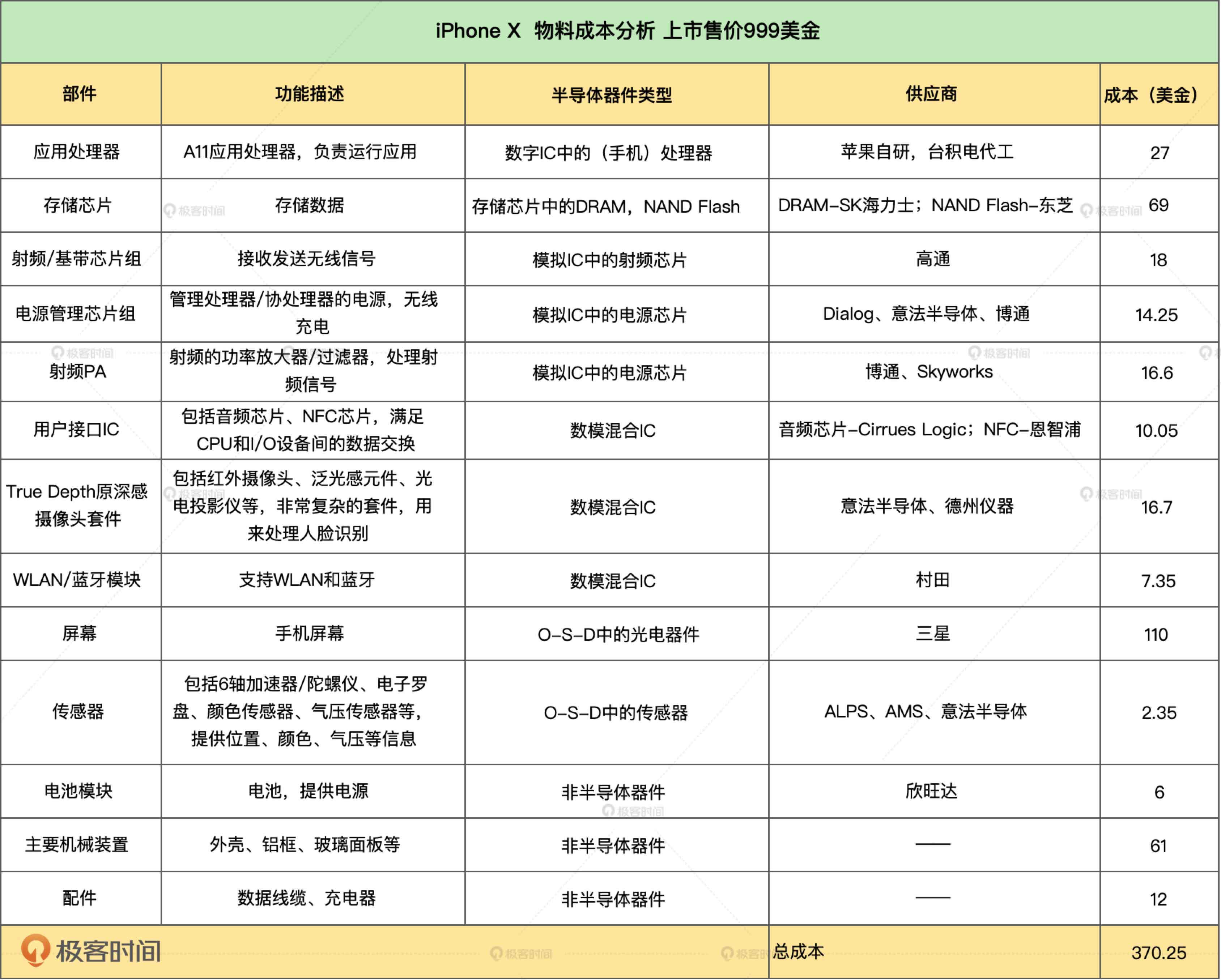
从一台iPhone来看集成电路和芯片
先看一台iPhone X拆解分析里面的所有芯片:
全球半导体营收分布
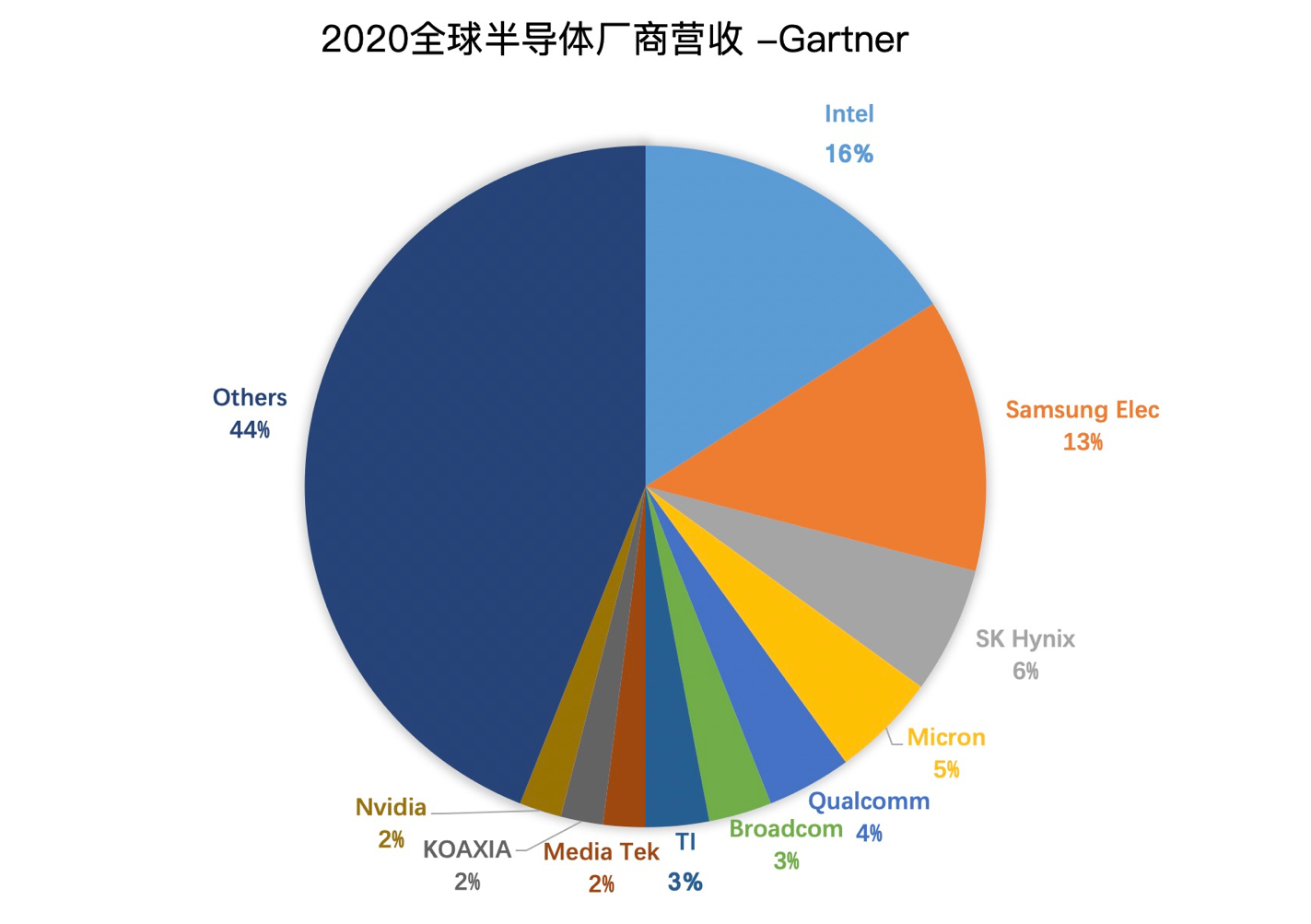
美光:美国;Hynix海力士:韩国现代;美国双通:高通(CDMA)、博通(各种买买买、并购,网络设备芯片);欧洲双雄(汽车芯片):恩智浦和英飞凌
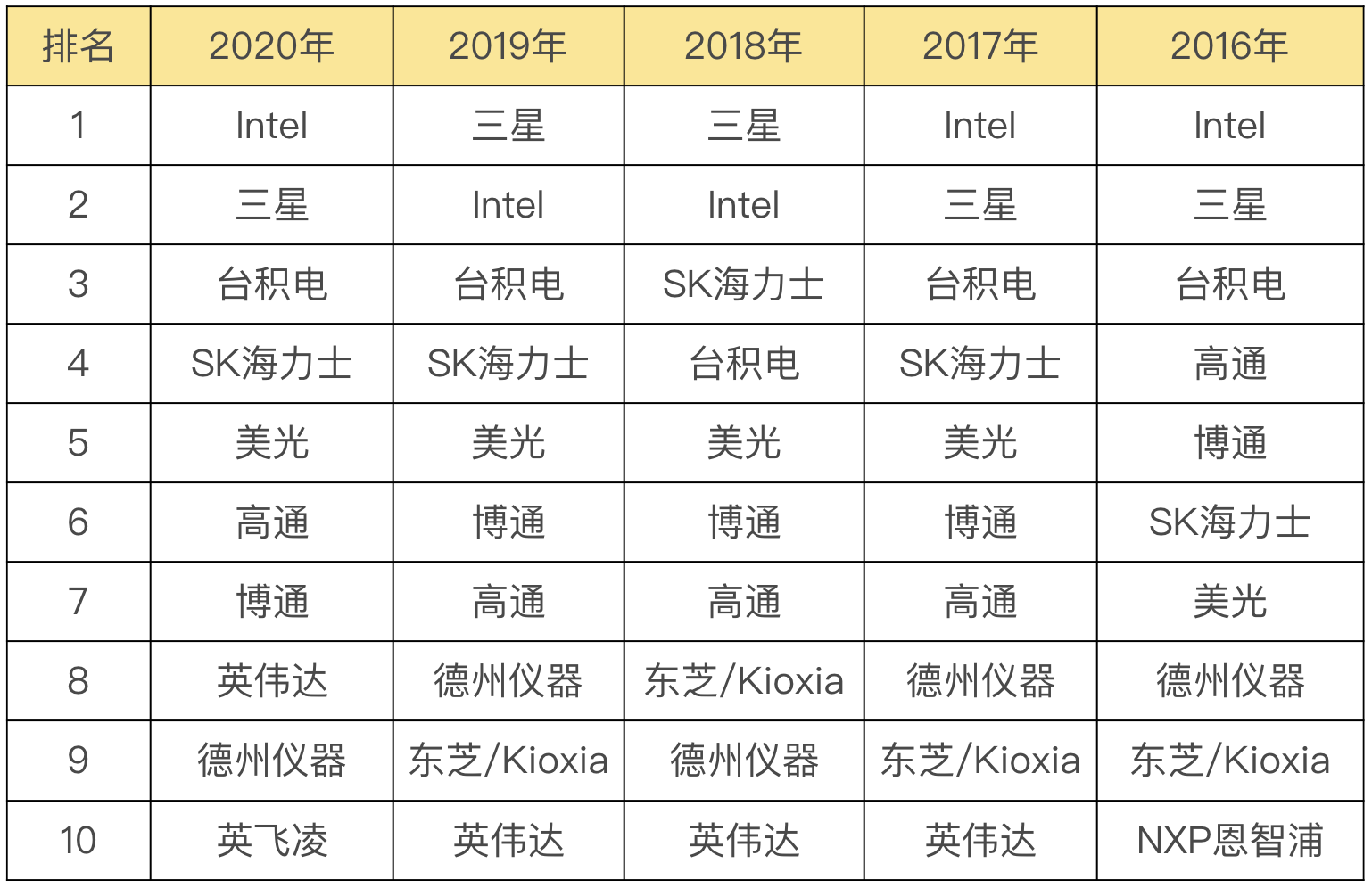
半导体行业近 5 年的行业前十的公司列了如下:
半导体产品的十大买家
BBK是步步高集团,包含vivo、oppo、oneplus、realme等

国内半导体市场情况
中国半导体协会总结过国产芯片的比例,2014 年出台的《国家集成电路产业发展纲要》和 2015 年的《中国制造 2025》文件中有明确提出:到 2020 年,集成电路产业与国际先进水平的差距逐步缩小;2020 年中国芯片自给率要达到 40%,2025 年要达到 50%。

国产化国家主导:紫光, 紫光的策略从收购转为自建,2016 年 12 月,合并武汉新芯,成立长江存储,与西数合资成立紫光西数。
长江存储在量产 64 层 NAND Flash 之后,2020 年首发 192 层 3D NAND,被预测 2021 会拿下 8% 的 NAND Flash 份额。同时,在存储芯片领域,中国还有一家公司叫做长鑫存储,长鑫存储以唯一一家中国公司的名号,杀入 DRAM 领域。在世界著名的行业分析公司 Yole 公司的报告上,显示长江存储和长鑫存储与三星、SK 海力士、美光和 Intel 齐头并进。
市场份额上,国产存储芯片市场,也许还有望达到 2025 的目标。
以上是我们对集成电路半导体行业的宏观认识。接下来我们从一颗CPU的生产制造开始讲
工艺
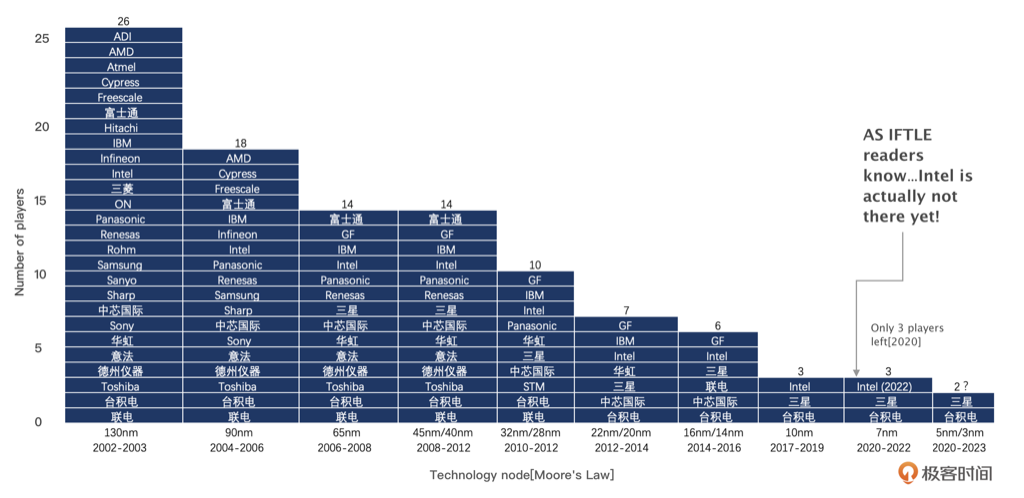
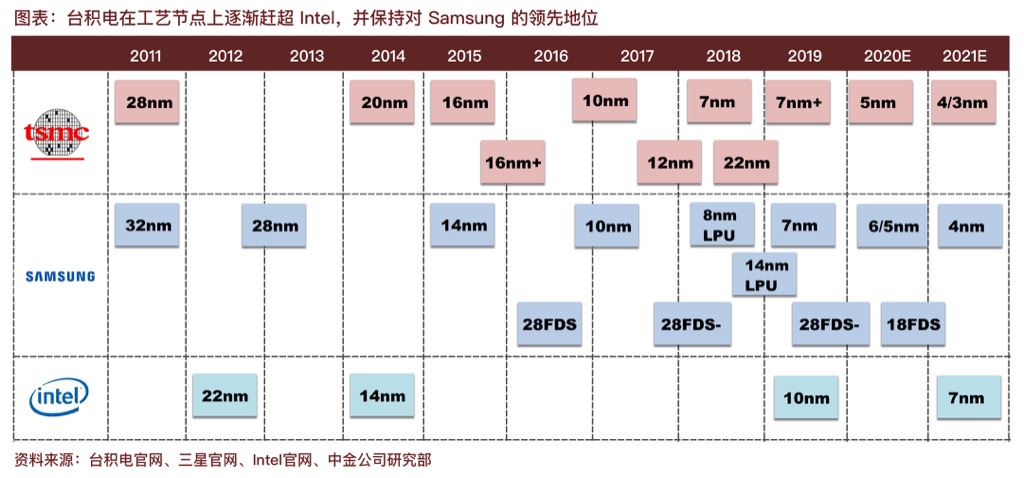
光刻的粒度越来越细,玩家也越来越少,基本主流都是代工模式:
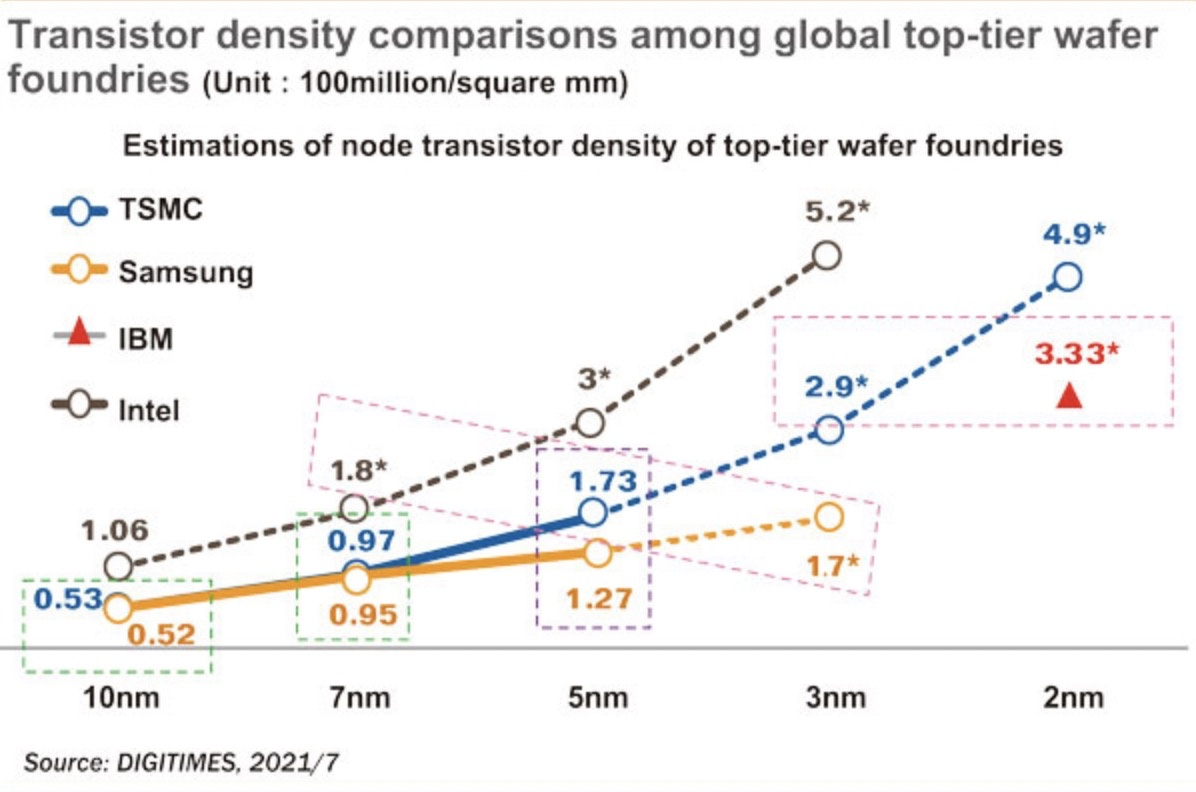
晶体管密度比较
计算机芯片发展总结和展望
从最早集成工艺驱动了CPU的性能符合摩尔定律发展,到现在工艺受限于物理上的客观因素:门延迟、电路间的绝缘层越薄漏电越严重–高温导致漏电呈指数级增加、电压无法随着尺寸降低而线性降低–130nm之前电压随线宽(工艺)而线性下降,到90nm工艺之后工作电压始终在1V左右无法进一步下降,越来越难进一步优化,导致摩尔定律基本已经做不到了。
下图显示最近几年CPU性能改进都在3%左右了(红色部分)
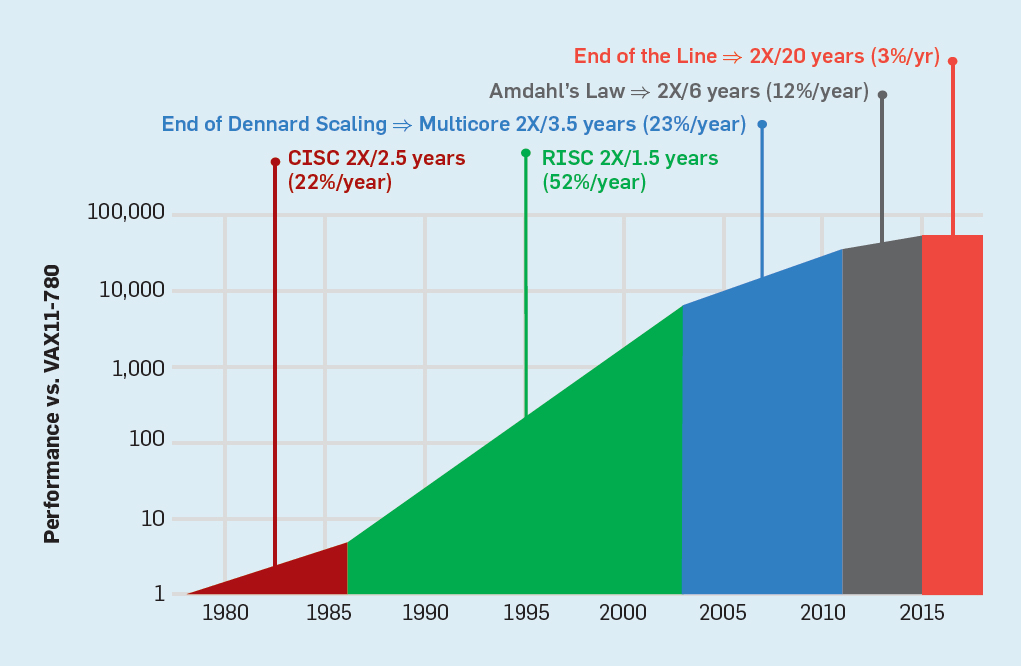
从上图可以看到性能的优化从最早CISC每年22%来自于指令本身优化,然后RISC(CISC内部也学习RISC将复杂指令编译成简单指令来适应流水线)每年52%,再到简单多核,然后到大规模多核,最后到红色无所改进。
登纳德缩放定律(Dennard scaling)指出,随着晶体管密度的增加,每个晶体管的能耗将降低,因此硅芯片上每平方毫米上的能耗几乎保持恒定。由于每平方毫米硅芯片的计算能力随着技术的迭代而不断增强,计算机将变得更加节能。登纳德缩放定律从 2007 年开始大幅放缓,2012 年左右接近失效(见下图)。
Dennard缩放定律(摩尔定律是经济定律,Dennard才是半导体专业定律):晶体管的尺寸在每一代技术中都缩小了30% (0.7倍),因此它们的面积减少了50%。这意味着电路减少了30% (0.7倍)的延迟,因此增加了约40% (1.4倍)的工作频率。最后,为了保持电场恒定,电压降低了30%,能量降低了65%,功率降低了50%。因此,在每一代技术中,晶体管密度增加一倍,电路速度提高40%,功耗(晶体管数量增加一倍)保持不变。
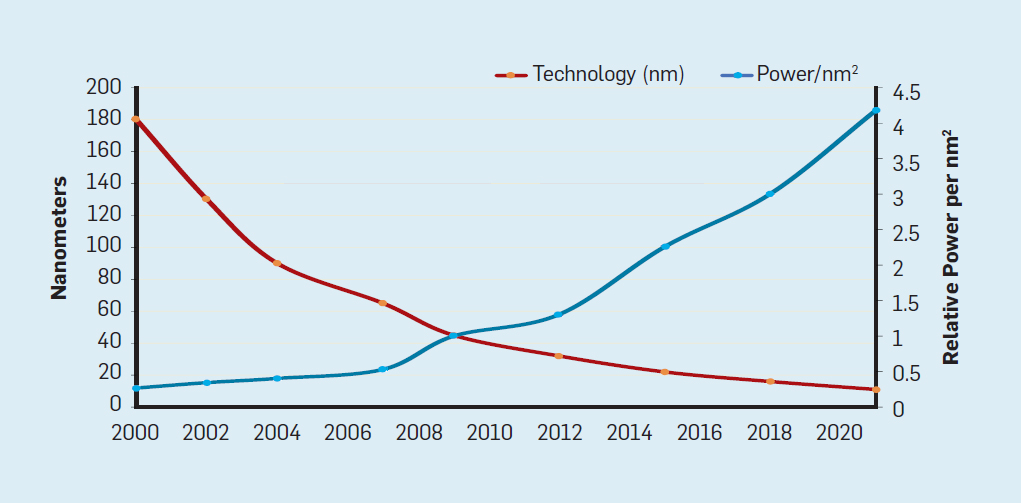
阿姆达尔定律(Amdahl’s Law)认为,并行计算机的加速受限于串行计算的部分。如下图假设只在一个处理器上执行时的串行执行的部分所占比例不同,与单个内核相比,最多 64 个内核的应用程序运行速度能快多少。例如,如果只有 1% 的时间是串行的,那么 64 核配置可加速大约 35 倍,但所需能量与 64 个处理器成正比,因此大约有 45% 的能量被浪费了。核数越多多核带来的提升效果越来越差(程序总有地方是串行的)
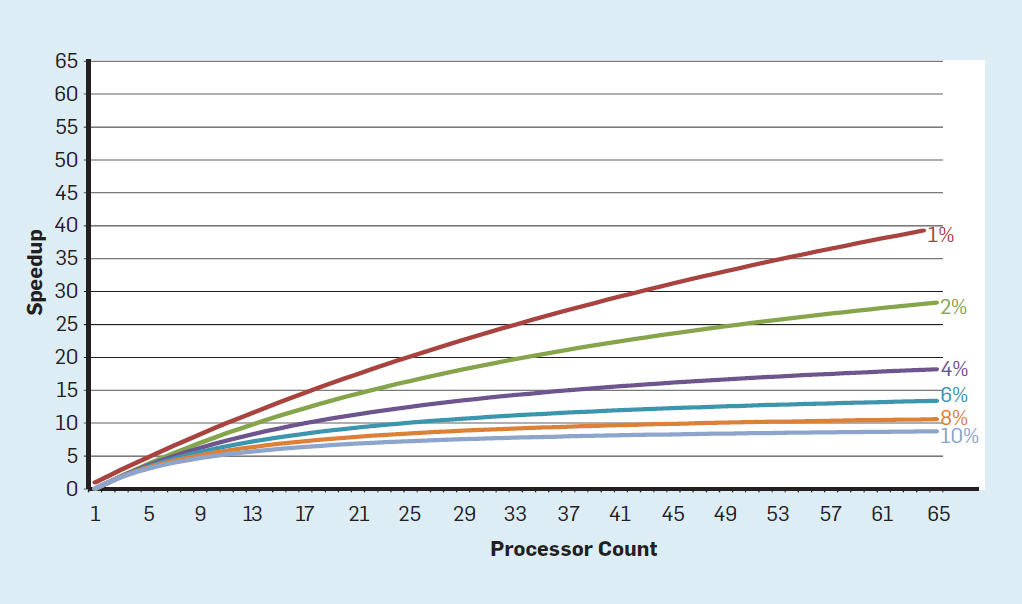
大概从2000年左右CPU的性能增长开始放缓,到2018年实际性能比摩尔定律预估的差了15倍(注意纵坐标是指数级),因为CMOS技术已经接近极限
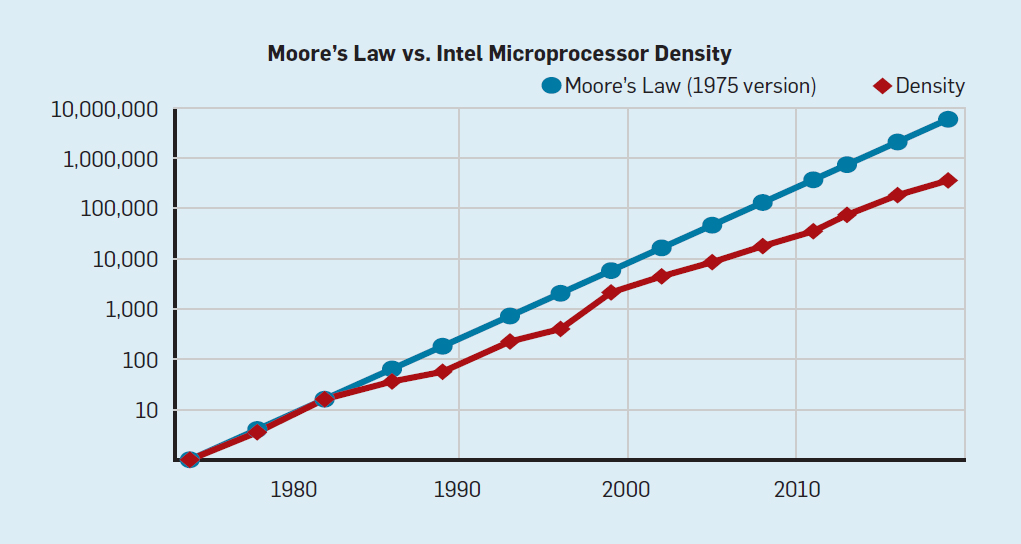
CMOS电路是互补型金属氧化物半导体电路(Complementary Metal-Oxide-Semiconductor)的英文字头缩写,它由绝缘场效应晶体管组成,由于只有一种载流子,因‘而是一种单极型晶体管集成电路,其基本结构是一个N沟道MOS管和一个P沟道MOS管
过去一些对性能或者便利性的改进以及对这些改进的打分:
虚拟地址在计算机体系结构里可以评为特优的一项技术,非性能上的改进,甚至对性能有负面影响;
超线程、流水线、多发射只是优;
cache 只是良好(成本高),cache整体肯定比超线程对性能提升要大,但是因为高成本导致得分不高
计算机架构的未来机遇
当实际集成度(性能)已经不再增长后,我们必须找到新的办法
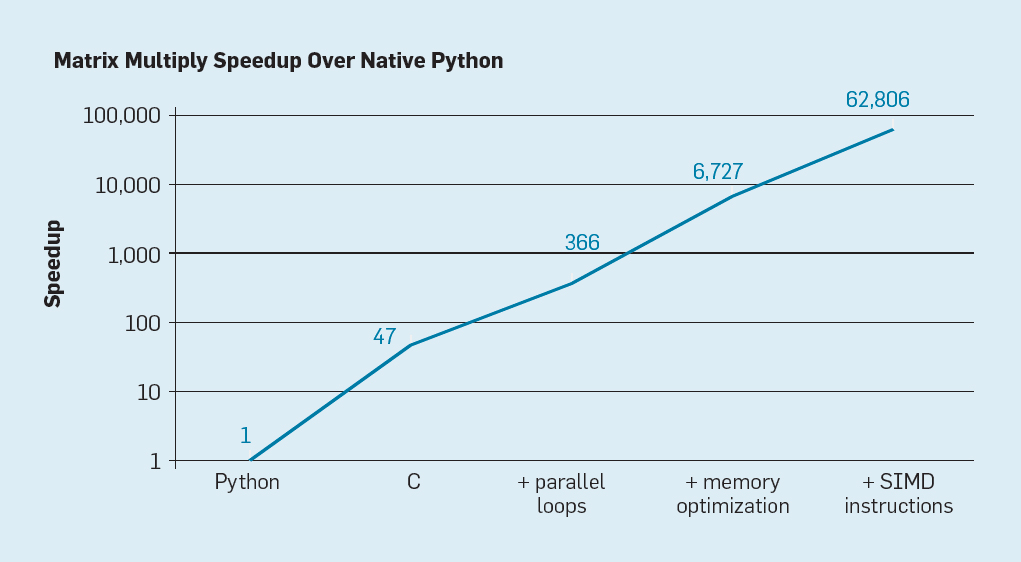
如下图是用Python实现的矩阵相乘的性能优化过程,简单地将 Python 语言代码重写为 C 代码就可以将性能提升 46 倍(Python 是典型的高级、动态类型语言)。在多核上运行并行循环(parallel loops)又将性能提升接近 7 倍。优化内存配置又将性能提升了近 19 倍,而通过单指令多数据(SIMD)并行化操作(一个指令执行 16 个 32-bit 运算)的硬件扩展,性能又提升了 8 倍多。也就是说,最终的高度优化版本在多核英特尔处理器上的运行速度是初始 Python 版本的 62,000 多倍。这当然只是一个很小的例子,但我们会期望程序员使用优化库。尽管这夸大了常见的性能差距,但很多程序的性能差距可能达到 100 到 1000 倍。
特定领域的体系结构(DSA)
特定领域的体系结构(DSA)–针对具体领域的特定优化和改进可以能是一个大的改进方向。比如SIMD,同时DSA和cache、内存的层次结构更匹配。
对特定领域降低精度,通用任务的 CPU 通常支持 32 和 64 位整型数和浮点数数据。对于很多机器学习和图像应用来说,这种准确率有点浪费了。例如在深度神经网络中(DNN),推理通常使用 4、8 或 16 位整型数,从而提高数据和计算吞吐量。同样,对于 DNN 训练程序,浮点数很有意义,但 32 位就够了,16 为经常也能用。
还可以在特定领域通过特定领域语言(DSL)编写的目标程序,这些程序可以实现更高的并行性(比如TPU、GPU)
开放式架构(Open Architectures)
RISC-V
总结
Wafer:晶圆,一片大的纯硅圆盘,新闻里常说的12寸、30寸晶圆厂说的就是它,光刻机在晶圆上蚀刻出电路
Die:从晶圆上切割下来的裸片(包含多个core、北桥、GPU等),Die的大小可以自由决定,得考虑成本和性能, Die做成方形便于切割和测试
封装:将一个或多个Die封装成一个物理上可以售卖的CPU
路:就是socket、也就是封装后的物理CPU
node:同一个Die下的多个core以及他们对应的内存,对应着NUMA
现在计算机系统的CPU和芯片组内核Die都是先封装到一个印制板上(PCB,printed circuit board),再通过LGA等等插槽(Socket)连上主板或直接焊接在主板上。这个过程叫做封装(Package),相关技术叫做封装技术。
系列文章
飞腾ARM芯片(FT2500)的性能测试的性能测试/)
Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的
作者|plantegg




