- A+
1 eBPF简介
eBPF(extended Berkeley Packet Filter)是一种革命性的内核技术,它允许开发人员编写可动态加载到内核中的自定义代码,从而改变内核的运行方式。(如果你对内核还不太了解,不用担心,本章很快就会讲到)。
这使得新一代高性能网络、可观察性和安全工具成为可能。而且,正如你将看到的,如果你想用这些基于eBPF的工具来检测应用程序,你不需要以任何方式修改或重新配置应用程序,这要归功于eBPF在内核中的有利位置。
使用 eBPF 可以做的事情包括
- 对系统的几乎所有方面进行性能跟踪
- 具有内置可见性的高性能网络
- 检测和(可选)预防恶意活动
1.1 eBPF的起源:伯克利数据包过滤器
我们今天所说的"eBPF"起源于BSD包过滤器,1993年由劳伦斯伯克利国家实验室的Steven McCanne和Van Jacobson撰写的一篇论文首次对其进行了描述。这篇论文讨论了一种可以运行过滤器的伪机器,过滤器是为决定接受或拒绝网络数据包而编写的程序。这些程序是用BPF指令集编写的,这是一套32位指令的通用指令集,与汇编语言非常相似。下面是直接摘自该论文的一个示例:
ldh [12] jeq #ETHERTYPE IP, L1, L2 L1: ret #TRUE L2: ret #0 这一小段代码过滤掉了不是互联网协议(IP)数据包的数据包。该过滤器的输入是一个以太网数据包,第一条指令 (ldh) 从数据包的第12个字节开始加载一个2字节的值。在下一条指令(jeq)中,该值与代表IP数据包的值进行比较。如果匹配,执行将跳转到标有L1的指令,并通过返回非零值(此处标识为 #TRUE)来接受数据包。如果不匹配,则该数据包不是IP数据包,会被拒绝,返回0。
你可以根据数据包的其他方面做出更复杂的决定,你也可以在论文中找到更复杂的过滤程序的例子。重要的是,过滤器的作者可以编写自己的定制程序在内核中执行,这就是eBPF的核心功能。
BPF是"伯克利数据包过滤器"(Berkeley Packet Filter)的缩写,于1997年首次引入Linux,内核版本为2.1.75,当时它被用在tcpdump工具中,作为捕获要追踪的数据包的有效方法。
2012年,内核3.5版本引入了seccomp-bpf。这使得BPF程序可以决定是否允许或拒绝用户空间应用程序进行系统调用。我们将在第10章对此进行更详细的探讨。这是BPF从狭义的数据包过滤发展到今天的通用平台的第一步。从这时起,BPF名称中的 "包过滤 "一词就不再那么有意义了!
1.2 从BPF到eBPF
从2014年内核3.18版开始,BPF演进为我们所说的"扩展BPF"。这涉及几个重大变化:
- 为了在64位机器上更高效,BPF指令集进行了全面修改,解释器也完全重写。
- 引入了eBPF映射,这是一种数据结构,BPF程序和用户空间应用程序都可以访问,从而可以在它们之间共享信息。你将在第2章了解映射。
- 增加了bpf()系统调用,这样用户空间程序就可以与内核中的eBPF程序交互。
- 添加了几个 BPF 辅助函数。
- 添加了eBPF校验器,以确保eBPF程序可以安全运行
这为eBPF奠定了基础,但开发工作并未因此放缓!从那时起,eBPF有了长足的发展。
1.3 eBPF向生产系统的演进
自2005年以来,Linux内核中就存在一种名为kprobes(内核探测)的功能,允许在内核代码中的几乎所有指令上设置陷阱。开发人员可以编写内核模块,将函数附加到kprobes上,用于调试或性能测量。
2015年,kprobes增加了附加eBPF程序的功能,这是Linux系统追踪方式革命的起点。与此同时,内核网络堆栈中开始添加钩子,允许eBPF程序处理网络功能的更多方面。
到2016年,基于eBPF的工具已被用于生产系统。布兰登-格雷格(Brendan Gregg)在Netflix的跟踪工作在基础设施和运营圈广为人知,他关于eBPF"为Linux带来超级能力"的说法也广为人知。同年Cilium项目发布,这是首个在容器环境中使用eBPF替换整个数据路径的网络项目。
次年Facebook(现为 Meta将Katran列为开源项目。Katran作为第4层负载平衡器,满足了Facebook对高度可扩展和快速解决方案的需求。自2017年以来,Facebook.com的每一个数据包都经过eBPF/XDP.4。
2018年,eBPF成为Linux内核中的一个独立子系统,其维护者是来自Isovalent的Daniel Borkmann和来自Meta的Alexei Starovoitov(后来,同样来自Meta的Andrii Nakryiko也加入了他们的行列)。同年BPF类型格式(BTF BPF Type Format)问世,它使eBPF程序更具可移植性。
2020年,LSM BPF正式推出,eBPF程序可以连接到Linux 安全模块(LSM Linux Security Module)内核接口。这表明 eBPF的第三个主要用例已经确定:很明显,除了网络和可观察性之外,eBPF还是安全工具的绝佳平台。
多年来,由于300多名内核开发人员以及相关用户空间工具(如 bpftool,我们将在第 3 章中介绍)、编译器和编程语言库的众多贡献者的努力,eBPF的能力得到了大幅提升。程序曾被限制在4,096条指令以内,但现在这一限制已增加到100万条验证指令,而且由于支持尾调用和函数调用,这一限制实际上已变得无关紧要。
阿列克谢-斯塔罗沃伊托夫(Alexei Starovoitov)从软件定义网络(SDN)的根源出发,对BPF的历史进行了精彩的介绍。在这次演讲中,他讨论了让内核接受早期eBPF补丁所使用的策略,并透露eBPF的正式生日是2014年9月26日,这一天标志着第一套涵盖验证器、BPF系统调用和地图的补丁被接受。
Daniel Borkmann还讨论了BPF的历史及其支持联网和跟踪功能的演变。我强烈推荐他的演讲"eBPF和Kubernetes: 扩展微服务的小助手",其中充满了有趣的信息。
1.4 命名很难
eBPF的应用范围远远超出了数据包过滤的范畴,以至于这个缩写现在基本上毫无意义,它已经成为一个独立的术语。由于目前广泛使用的Linux内核都支持"扩展"部分,eBPF和BPF这两个术语在很大程度上可以互换使用。在内核源代码和eBPF编程中,常用术语是BPF。例如,我们将在第4章中看到,与eBPF交互的系统调用是bpf(),辅助函数以bpf_开头,不同类型的(e)BPF 程序以BPF_PROG_TYPE 开头。在内核社区之外,"eBPF"这个名字似乎已经深入人心,例如社区网站ebpf.io和eBPF基金会的名称。
1.5 Linux内核
要理解eBPF,你需要牢固掌握Linux内核和用户空间之间的区别。我在"什么是 eBPF?"报告中对此进行了阐述,并在接下来的几段中对部分内容进行了改编。
Linux内核是应用程序与运行硬件之间的软件层。应用程序运行在称为用户空间的非特权层中,不能直接访问硬件。相反,应用程序会使用系统调用(syscall)接口发出请求,要求内核代表它采取行动。硬件访问可能涉及读写文件、发送或接收网络流量,甚至只是访问内存。内核还负责协调并发进程,使许多应用程序能同时运行。如图所示。
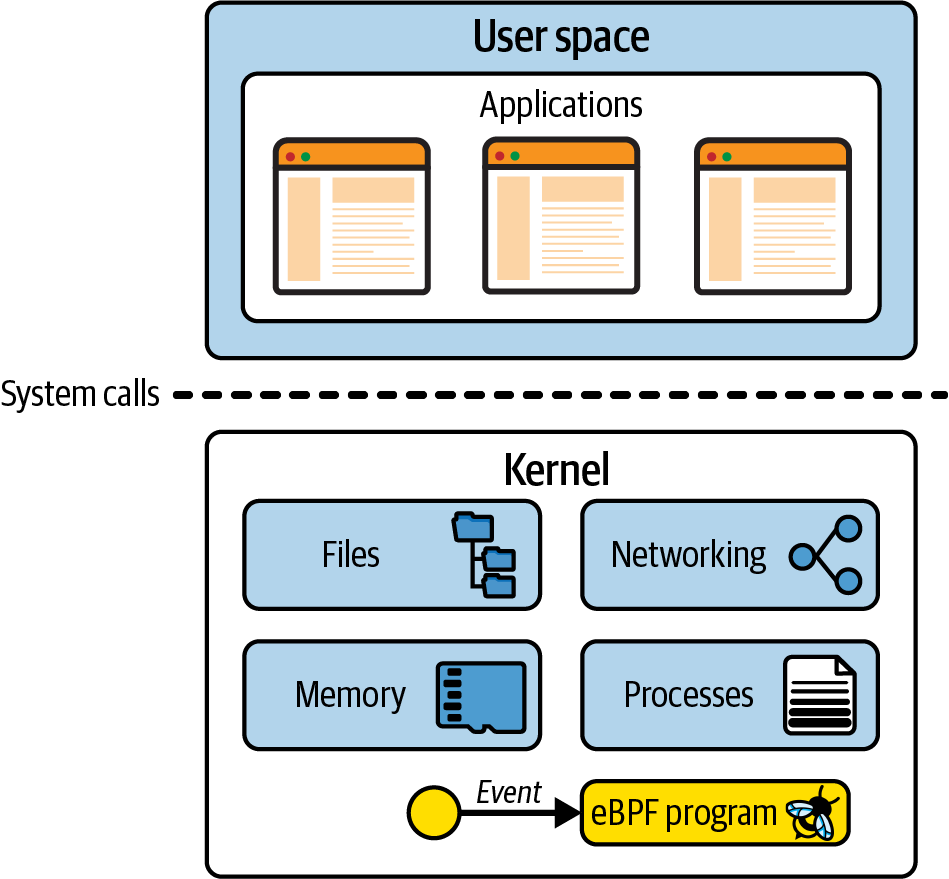
作为应用程序开发人员,我们通常不会直接使用系统调用接口,因为编程语言为我们提供了更容易编程的高级抽象和标准库接口。因此,很多人都不知道内核在我们程序运行时做了多少工作。如果你想了解内核被调用的频率,可以使用strace工具来显示应用程序进行的所有系统调用。
$ strace -c echo "hello" hello % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 0.00 0.000000 0 1 read 0.00 0.000000 0 1 write 0.00 0.000000 0 5 close 0.00 0.000000 0 9 mmap 0.00 0.000000 0 3 mprotect 0.00 0.000000 0 1 munmap 0.00 0.000000 0 3 brk 0.00 0.000000 0 4 pread64 0.00 0.000000 0 1 1 access 0.00 0.000000 0 1 execve 0.00 0.000000 0 2 1 arch_prctl 0.00 0.000000 0 1 set_tid_address 0.00 0.000000 0 3 openat 0.00 0.000000 0 4 newfstatat 0.00 0.000000 0 1 set_robust_list 0.00 0.000000 0 1 prlimit64 0.00 0.000000 0 1 getrandom 0.00 0.000000 0 1 rseq ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000000 0 43 2 total 由于应用程序对内核的依赖程度如此之高,这意味着如果我们能观察到应用程序与内核的交互,就能了解到应用程序的行为方式。有了eBPF,我们就可以在内核中添加仪器,从而获得这些信息。
例如如果能拦截打开文件的系统调用,就能准确了解应用程序访问了哪些文件。但如何进行拦截呢?让我们考虑一下,如果我们想修改内核,添加新代码,以便在调用系统调用时创建某种输出,会涉及到哪些问题。
1.6 为内核添加新功能
对任何代码库进行修改都需要对现有代码有一定程度的熟悉,所以除非你已经是内核开发人员,否则这很可能是一个挑战。
此外,如果你想把你的改动贡献给上游,你将面临一个不纯粹是技术上的挑战。Linux是一种通用操作系统,可用于各种环境和情况。这意味着,如果你想让你的改动成为Linux正式版本的一部分,就不仅仅是写出能正常运行的代码那么简单了。这些代码必须得到社区(更具体地说是Linux的创建者和主要开发者Linus Torvalds)的认可,被认为是对所有人都有利的改变。这并不是必然的,在提交的内核补丁中,只有三分之一被接受。
假设你已经找到了拦截打开文件的系统调用的好技术方法。经过几个月的讨论和艰苦的开发工作,我们假设内核接受了这一修改。好极了!但要多久才能在每个人的机器上实现呢?
Linux内核每两三个月就会发布一个新版本,但即使某项改动已被纳入其中一个版本,它距离在大多数人的生产环境中使用仍有一段时间。这是因为我们大多数人并不直接使用Linux内核,而是使用Debian、Red Hat、Alpine和Ubuntu等Linux发行版,这些发行版将Linux内核与其他各种组件打包在一起。你很可能会发现,你最喜欢的发行版使用的内核已经是几年前的版本了。

参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
1.7 内核模块
如果你不想等上好几年才能把你的改动加入内核,还有另一种选择。Linux内核是为接受内核模块而设计的,内核模块可以按需加载和卸载。如果你想改变或扩展内核行为,编写模块无疑是一种方法。内核模块可以独立于Linux内核的正式版本发布,供其他人使用,因此不必被上游的主要代码库所接受。
这里最大的挑战在于,这仍然是完全的内核编程。用户在使用内核模块时历来非常谨慎,原因很简单:如果内核代码崩溃,就会导致机器及其上运行的所有程序瘫痪。用户如何确信内核模块可以安全运行?
安全运行"并不仅仅意味着不会崩溃--用户想知道内核模块从安全角度来看是否安全。它是否包含攻击者可能利用的漏洞?我们是否相信模块作者不会在模块中加入恶意代码?由于内核是特权代码,它可以访问机器上的一切,包括所有数据,因此内核中的恶意代码会引起严重关切。这一点也适用于内核模块。
内核的安全性是Linux发行版需要很长时间才能发布新版本的一个重要原因。如果其他人已经在各种环境下运行了数月或数年的内核版本,那么问题应该已经被清除了。发行版的维护者就可以确信,他们提供给用户/客户的内核是经过加固的,也就是说,运行起来是安全的。
eBPF提供了一种非常不同的安全方法:eBPF校验器,它可以确保只有在运行安全的情况下才加载eBPF程序--它不会让机器崩溃或锁定在硬循环中,也不会让数据泄露。
1.7 动态加载eBPF程序
eBPF程序可以动态加载到内核或从内核中移除。一旦程序被附加到事件中,无论事件发生的原因是什么,它们都会被该事件触发。例如,如果将一个程序附加到打开文件的系统调用上,那么只要有进程试图打开文件,该程序就会被触发。至于程序加载时该进程是否已在运行,则无关紧要。与升级内核,然后必须重启机器才能使用新功能相比,这是一个巨大的优势。
这也是使用eBPF的可观察性或安全工具的一大优势--它可以立即查看机器上发生的一切。在运行容器的环境中,这包括对容器内以及主机上运行的所有进程的可见性。本章稍后我将深入探讨这对云原生部署的影响。
此外,如图所示,人们可以通过eBPF快速创建新的内核功能,而不需要其他所有Linux用户都接受相同的更改。

1.8 eBPF程序的高性能
eBPF程序是一种非常高效的添加方式。一旦加载并经过JIT编译,程序就能以本地机器指令的形式在CPU上运行。此外,处理每个事件都无需在内核和用户空间之间转换(这是一项昂贵的操作)。
2018年的论文介绍了eXpress Data Path(XDP),其中包括eBPF在网络中实现性能改进的一些示例。例如,与普通Linux 内核实现相比,在XDP中实施路由"可将性能提高2.5倍",而在负载平衡方面,"XDP比IPVS的性能提高了4.3倍"。
在性能跟踪和安全可观察性方面,eBPF的另一个优势是可以在内核中过滤相关事件,然后再将其发送到用户空间。毕竟,只过滤某些网络数据包才是最初BPF实现的重点。如今eBPF程序可以收集系统中各种事件的信息,并可以使用复杂、定制的程序过滤器,只向用户空间发送相关的信息子集。
1.9 云原生环境中的eBPF
如今许多企业都不选择直接在服务器上执行程序来运行应用程序。取而代之的是,许多组织使用云原生方法:容器、Kubernetes或ECS等编排器,或Lambda、云函数、Fargate等无服务器方法。这些方法都使用自动化来选择每个工作负载运行的服务器;在无服务器中,我们甚至不知道每个工作负载运行的服务器是什么。
尽管如此,还是有服务器参与其中,而且每台服务器(无论是虚拟机还是裸机)都运行着内核。在容器中运行应用时,如果它们运行在同一台(虚拟)机器上,就会共享同一个内核。在Kubernetes环境中,这意味着某个节点上所有pod中的所有容器都在使用同一个内核。当我们在内核中加入eBPF程序时,该节点上的所有容器化工作负载对这些eBPF程序都是可见的,如图所示。
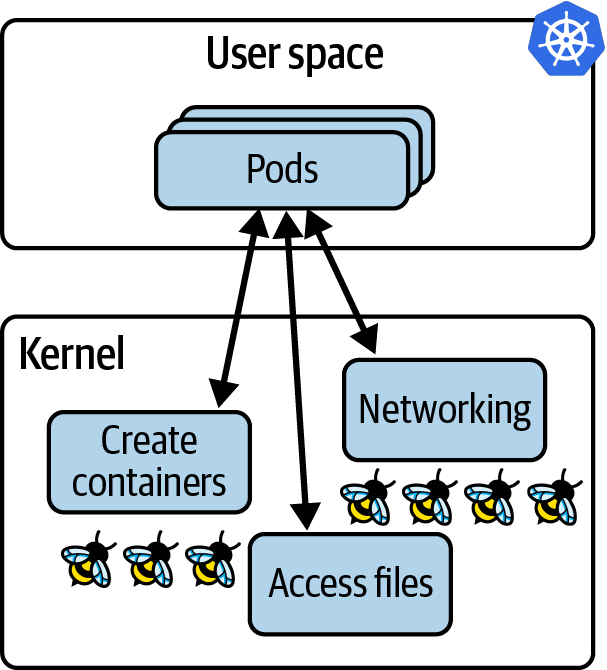
节点上所有进程的可见性,再加上动态加载eBPF程序的能力,让我们在云原生计算中真正拥有了基于eBPF工具的超强能力:
- 我们不需要改变应用程序,甚至不需要改变它们的配置方式,就能使用eBPF工具对它们进行检测。
- 只要将其加载到内核并附加到事件中,eBPF 程序就可以开始观察已有的应用程序进程。
这与侧卡(sidecar)模式形成了鲜明对比,后者被用于在Kubernetes应用程序中添加日志、跟踪、安全和服务网格功能等功能。在"侧卡"方法中,仪器以容器的形式运行,并被"注入"到每个应用程序pod中。这一过程包括修改定义应用程序pod的 YAML,并添加侧卡容器的定义。这种方法当然比在应用程序pod更方便。
sidecar方法也有一些缺点:
- 必须重新启动应用程序 pod 才能添加侧载。
- 必须修改应用程序 YAML。这通常是一个自动化流程,但如果出了差错,侧卡就不会被添加,这意味着pod不会被检测到。例如,一个部署可能会被注释为表明接纳控制器应将边卡YAML添加到该部署的pod规范中。但是,如果部署没有正确标注,侧卡就不会被添加,因此仪器也就无法看到它。
- 当pod中有多个容器时,它们可能会在不同时间达到就绪状态,其顺序可能无法预测。Pod的启动时间可能会因注入侧车而大大减慢,更有甚者,可能会导致竞赛条件或其他不稳定因素。例如,Open Service Mesh文档描述了应用容器在Envoy代理容器准备就绪之前,如何避免所有流量被丢弃。当服务网格等网络功能作为侧载实现时,必然意味着进出应用容器的所有流量都必须通过内核中的网络堆栈才能到达网络代理容器,从而增加了流量的延迟;如图所示。
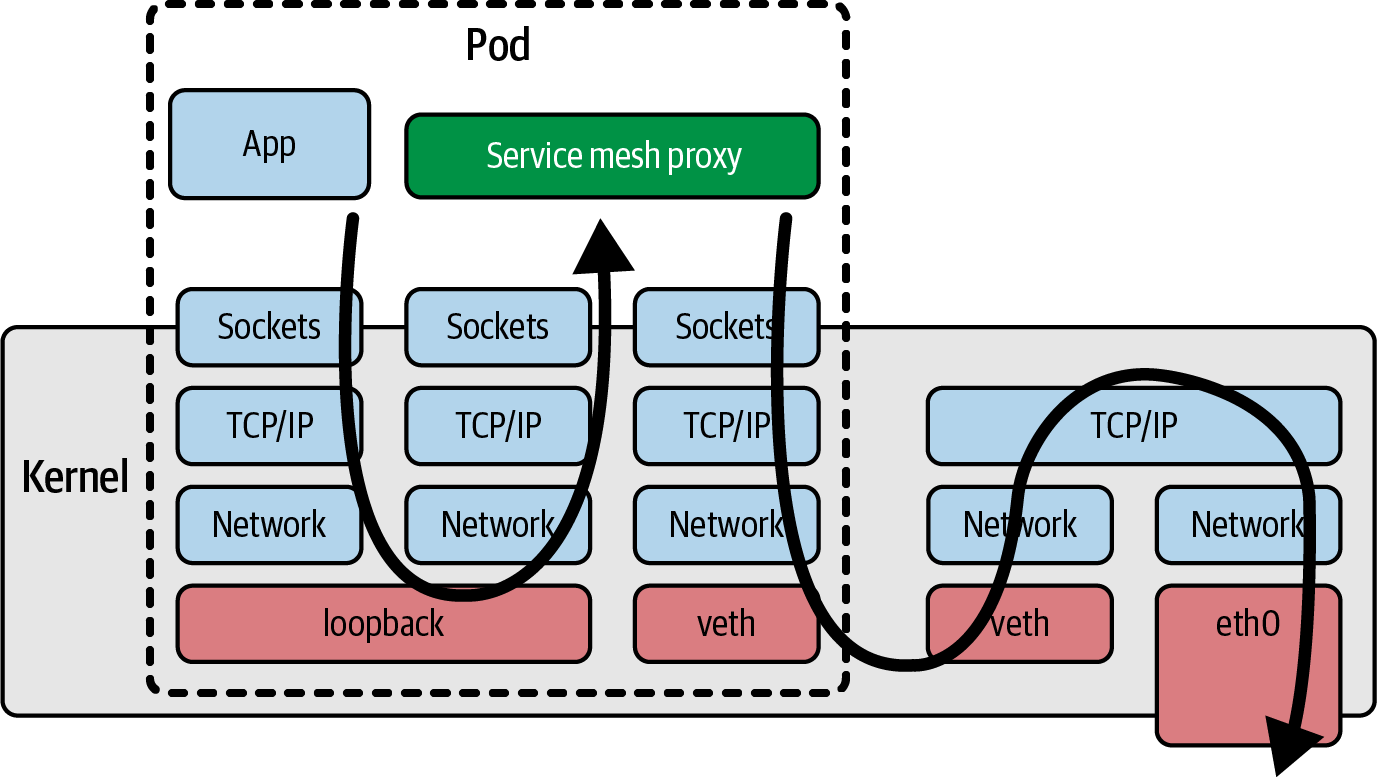
所有这些问题都是旁路模型的固有问题。幸运的是,现在有了eBPF作为平台,我们就有了可以避免这些问题的新模式。此外,由于基于eBPF的工具可以看到(虚拟)机器上发生的一切,因此坏人更难躲避。例如,如果攻击者设法在您的一台主机上部署了加密货币挖矿应用程序,他们可能不会使用您在应用程序工作负载上使用的侧卡对其进行检测。如果你依赖基于边卡的安全工具来防止应用程序进行意外的网络连接,那么如果没有注入边卡,该工具是不会发现挖矿应用程序连接到其矿池的。相比之下,eBPF实现的网络安全功能可以监控主机上的所有流量,因此可以轻松阻止这种加密货币挖矿操作。出于安全原因丢弃网络数据包的功能。
1.10 小结
希望本章能让你了解eBPF作为平台如此强大的原因。它允许我们改变内核的行为,为我们提供了构建定制工具或自定义策略的灵活性。基于eBPF的工具可以观察内核中的任何事件,从而观察(虚拟)机器上运行的所有应用程序,无论它们是否被容器化。
到目前为止,我们已经在相对概念化的层面上讨论了eBPF。在下一章中,我们将更具体地探讨基于eBPF的应用程序的各个组成部分。
9 值得庆幸的是,对现有功能的安全补丁提供得更快。
10 Høiland-Jørgensen T、Brouer JD、Borkmann D 等:《eXpress 数据路径:操作系统内核中的快速可编程数据包处理》。第 14 届新兴网络实验与技术国际会议(CoNEXT '18)论文集》。计算机械协会;2018:54-66.




