- A+
原生 AOT
原生 AOT 在 .NET 7 中发布。它使 .NET 程序在构建时被编译成一个完全由原生代码组成的自包含可执行文件或库:在执行时不需要 JIT 来编译任何东西,实际上,编译的程序中没有包含 JIT。结果是一个可以有非常小的磁盘占用,小的内存占用,和非常快的启动时间的应用程序。在 .NET 7 中,主要支持的工作负载是控制台应用程序。现在在 .NET 8 中,已经投入了大量的工作来使 ASP.NET 应用程序在使用原生 AOT 编译时表现出色,同时也降低了总体成本,无论应用模型如何。
在 .NET 8 中,一个重要的焦点是减小构建应用程序的大小,这个效果非常容易看出来。让我们开始创建一个新的原生 AOT 控制台应用程序:
dotnet new console -o nativeaotexample -f net7.0 这将创建一个新的 nativeaotexample 目录,并向其中添加一个针对 .NET 7 的新的 "Hello, world" 应用程序。以两种方式编辑生成的 nativeaotexample.csproj:
- 将
<TargetFramework>net7.0</TargetFramework>更改为<TargetFrameworks>net7.0;net8.0</TargetFrameworks>,以便我们可以轻松地为 .NET 7 或 .NET 8 构建。 - 在
<PropertyGroup>...</PropertyGroup>中添加<PublishAot>true</PublishAot>,以便当我们 dotnet publish 时,它使用 Native AOT。
现在,为 .NET 7 发布应用程序。我目前正在针对 x64 的 Linux,所以我使用 linux-x64,但你可以在 Windows 上使用 Windows 标识符,如 win-x64,跟随操作:
dotnet publish -f net7.0 -r linux-x64 -c Release 这应该成功构建应用程序,生成一个独立的可执行文件,我们可以 ls/dir 输出目录以查看生成的二进制大小(这里我使用了 ls -s --block-size=k):
12820K /home/stoub/nativeaotexample/bin/Release/net7.0/linux-x64/publish/nativeaotexample 所以,在 Linux 上的 .NET 7,这个 "Hello, world" 应用程序,包括所有必要的库支持,GC,所有的东西,是 ~13Mb。现在,我们可以为 .NET 8 做同样的事情:
dotnet publish -f net8.0 -r linux-x64 -c Release 再次查看生成的输出大小:
1536K /home/stoub/nativeaotexample/bin/Release/net8.0/linux-x64/publish/nativeaotexample 现在在 .NET 8,那个 ~13MB 已经降到 ~1.5M!我们还可以使用各种支持的配置标志使其更小。首先,我们可以设置在 dotnet/runtime#85133 中引入的大小与速度选项,向 .csproj 添加 <OptimizationPreference>Size</OptimizationPreference>。然后,如果我不需要全球化特定的代码和数据,并且可以使用不变模式,我可以添加 <InvariantGlobalization>true</InvariantGlobalization>。也许我不在乎如果发生异常是否有好的堆栈跟踪?dotnet/runtime#88235 添加了 <StackTraceSupport>false</StackTraceSupport> 选项。添加所有这些并重新发布:
1248K /home/stoub/nativeaotexample/bin/Release/net8.0/linux-x64/publish/nativeaotexample 很好。
这些改进的大部分来自于一种无情的努力,涉及到在这里削减10Kb,那里削减20Kb。以下是一些降低这些大小的例子:
-
Native AOT 编译器需要创建各种数据结构,然后在应用程序执行时由运行时使用。dotnet/runtime#77884 添加了对这些数据结构的支持,包括包含指针的数据结构,可以存储到应用程序中,然后在执行时重新激活。即使在后续的 PR 以各种方式扩展之前,这就已经从应用程序大小中削减了几百千字节,无论是在 Windows 还是 Linux(但在 Linux 上更多)。
-
每个具有包含引用的静态字段的类型都有一个与之关联的包含几个指针的数据结构。dotnet/runtime#78794 使这些指针相对化,节省了 HelloWorld 应用程序大小的约0.5%(至少在 Linux 上,Windows 上稍微少一些)。dotnet/runtime#78801 对另一组指针做了同样的处理,又节省了约1%。
-
dotnet/runtime#79594 移除了一些过度积极的跟踪类型和方法,这些类型和方法需要存储关于它们的反射数据。这又在 HelloWorld 上节省了约32Kb。
-
在某些情况下,即使它们从未被使用并因此为空,也会创建泛型类型字典。dotnet/runtime#82591 摆脱了这些,又在一个简单的 ASP.NET 最小 API 应用程序上节省了约1.5%。dotnet/runtime#83367 通过摆脱其他空的类型字典,又节省了约20Kb。
-
在泛型类型上声明的成员有其代码复制并专门用于替代泛型类型参数的每个值类型。然而,如果通过一些调整,这些成员可以被非泛型化并移出类型,例如移入一个非泛型基类型,那么就可以避免这种复制。dotnet/runtime#82923 对数组枚举器做了这样的处理,移动了 IDisposable 和非泛型 IEnumerator 接口实现。
-
CoreLib 有一个空数组枚举器的实现,当枚举一个空的 T[] 时可以使用,这个单例可能在非数组的可枚举对象中使用,例如,枚举一个空的 (IEnumerable<KeyValuePair<TKey, TValue>>)Dictionary<TKey, TValue> 可能会产生那个数组枚举器单例。然而,那个枚举器有一个引用到 T[],在 Native AOT 世界中,使用枚举器意味着需要为 T[] 的各个成员产生代码。然而,如果问题中的枚举器是一个不太可能在其他地方使用的 T[](例如,KeyValuePair<TKey, TValue>[]),dotnet/runtime#82899 提供了一个专门的枚举器单例,它不引用 T[],避免强制创建和保留那个代码(例如,Dictionary<TKey, TValue> 的 IEnumerable<KeyValuePair<TKey, TValue>> 的代码)。
-
没有人会在 C# 编译器为异步方法生成的 AsyncStateMachine 结构上调用 Equals/GetHashCode 方法;它们是一个隐藏的实现细节,但即便如此,这些虚方法通常在 Native AOT 应用程序中保持根源(而 CoreCLR 可以使用反射为值类型提供这些方法的实现,Native AOT 需要为每个值类型发出定制的代码)。dotnet/runtime#83369 对这些进行了特殊处理,以避免它们被保留,从而在最小 API 应用程序上又节省了约1%。
-
dotnet/runtime#83937 减小了静态构造函数上下文的大小,这些数据结构用于在系统的各个部分之间传递关于类型的静态 cctor 的信息。
-
dotnet/runtime#84463 做了一些调整,最终避免了为 double/float 创建 MethodTables,并减少了对一些数组方法的依赖,从 HelloWorld 上又节省了约3%。
-
dotnet/runtime#84156 手动将一个方法分成两部分,使得一些较少使用的代码不总是在使用更常用的代码时引入;这又节省了几百千字节。
-
dotnet/runtime#84224 改进了处理常见模式 typeof(T) == typeof(Something) 的方式,这种模式经常用于进行泛型专门化(例如,在像 MemoryExtensions 这样的代码中),并以一种更容易去除被剪掉的分支的副作用的方式进行。
-
GC 包括一个名为 vxsort 的向量化排序实现。在使用优化大小的配置构建时,dotnet/runtime#85036 允许移除那个吞吐量优化,节省了几百千字节。
-
ValueTuple<...> 是一个非常方便的类型,但它带来了大量的代码,因为它实现了多个接口,这些接口然后在泛型类型参数上根源功能。dotnet/runtime#87120 从 SynchronizationContext 中移除了对 ValueTuple<T1, T2> 的使用,节省了约200Kb。
-
特别是在 Linux 上,一个大的改进来自 dotnet/runtime#85139。调试符号以前被存储在发布的可执行文件中;有了这个改变,符号从可执行文件中剥离出来,而是存储在旁边构建的一个单独的 .dbg 文件中。想要恢复到在可执行文件中保留符号的人可以在他们的项目中添加
<StripSymbols>false</StripSymbols>。
你已经明白了。然而,改进不仅仅在于 Native AOT 编译器内部的修修补补。单个库也做出了贡献。例如:
- HttpClient 支持自动解压响应流,包括 deflate 和 brotli,这反过来意味着任何 HttpClient 的使用都隐式地带有大部分的 System.IO.Compression。然而,默认情况下,这种解压缩是不启用的,你需要通过在使用的 HttpClientHandler 或 SocketsHttpHandler 上显式设置 AutomaticDecompression 属性来选择启用它。所以,dotnet/runtime#78198 使用了一个技巧,其中 SocketsHttpHandler 的主要代码路径不是直接依赖于执行这项工作的内部 DecompressionHandler,而是依赖于一个委托。存储该委托的字段开始时为 null,然后作为 AutomaticDecompression setter 的一部分,该字段被设置为一个将执行解压缩工作的委托。这意味着,如果修剪器没有看到任何访问 AutomaticDecompression setter 的代码,以便可以修剪掉 setter,那么所有的 DecompressionHandler 及其对 DeflateStream 和 BrotliStream 的依赖也可以被修剪掉。因为它有点难以理解,所以这里有一个表示它的图示:
private DecompressionMethods _automaticDecompression; private Func<Stream, Stream>? _getStream; public DecompressionMethods AutomaticDecompression { get => _automaticDecompression; set { _automaticDecompression = value; _getStream ??= CreateDecompressionStream; } } public Stream GetStreamAsync() { Stream response = ...; return _getStream is not null ? _getStream(response) : response; } private static Stream CreateDecompressionStream(Stream stream) => UseGZip ? new GZipStream(stream, CompressionMode.Decompress) : UseZLib ? new ZLibStream(stream, CompressionMode.Decompress) : UseBrotli ? new BrotliStream(stream, CompressionMode.Decompress) : stream; } 这里的 CreateDecompressionStream 方法是引用所有压缩相关代码的地方,唯一接触它的代码路径是在 AutomaticDecompression setter 中。因此,如果应用程序中没有任何东西访问 setter,那么 setter 可以被修剪,这意味着 CreateDecompressionStream 方法也可以被修剪,这意味着如果应用程序中的其他任何东西都没有使用这些压缩流,它们也可以被修剪。
-
runtime#80884 是另一个例子,当使用 Regex 时,只需在其实现中更有目的性地使用什么类型(例如,使用 bool[30] 而不是 HashSet
来存储位图),就可以节省约90Kb的大小。 -
或者特别有趣的,dotnet/runtime#84169,它为 System.Xml 添加了一个新的特性开关。System.Xml 中的各种 API 使用 Uri,这可能会触发 XmlUrlResolver 的使用,这反过来又引用了网络堆栈;一个使用 XML 但不使用网络的应用程序可能会无意中引入超过3MB的网络代码,只是通过使用像 XDocument.Load("filepath.xml") 这样的 API。这样的应用程序可以使用 dotnet/sdk#34412 中添加的
<XmlResolverIsNetworkingEnabledByDefault>MSBuild 属性来启用所有这些在 XML 中的代码路径被修剪掉。 -
Microsoft.Extensions.DependencyInjection.Abstractions 中的 ActivatorUtilities.CreateFactory 试图通过提前花费一些时间来构建一个然后非常有效地创建事物的工厂来优化吞吐量。它的主要策略是使用 System.Linq.Expressions 作为使用反射发射的更简单的 API,为正在构造的确切事物构建自定义 IL。当你有一个 JIT 时,这可以工作得很好。但是,当不支持动态代码时,System.Linq.Expressions 不能使用反射发射,而是回退到使用解释器。这使得在 CreateFactory 中的这种“优化”实际上是一种去优化,而且它带来了 System.Linq.Expression.dll 的大小影响。dotnet/runtime#81262 为 !RuntimeFeature.IsDynamicCodeSupported 添加了一个基于反射的替代方案,从而产生更快的代码,并允许修剪掉 System.Linq.Expression 的使用。
当然,虽然大小是 .NET 8 的一个重点,但是有许多其他方式可以提高 Native AOT 的性能。例如,dotnet/runtime#79709 和 dotnet/runtime#80969 避免了在读取静态字段时的辅助调用。BenchmarkDotNet 也支持 Native AOT,所以我们可以运行以下基准测试进行比较;我们只使用 --runtimes nativeaot7.0 nativeaot8.0,而不使用 --runtimes net7.0 net8.0(BenchmarkDotNet 目前也不支持 Native AOT 的 [DisassemblyDiagnoser]):
// dotnet run -c Release -f net7.0 --filter "*" --runtimes nativeaot7.0 nativeaot8.0 using BenchmarkDotNet.Attributes; using BenchmarkDotNet.Running; BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args); [HideColumns("Error", "StdDev", "Median", "RatioSD")] public class Tests { private static readonly int s_configValue = 42; [Benchmark] public int GetConfigValue() => s_configValue; } 对于这个,BenchmarkDotNet 输出:
| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| GetConfigValue | NativeAOT 7.0 | 1.1759 ns | 1.000 |
| GetConfigValue | NativeAOT 8.0 | 0.0000 ns | 0.000 |
包括:
// * Warnings * ZeroMeasurement Tests.GetConfigValue: Runtime=NativeAOT 8.0, Toolchain=Latest ILCompiler -> The method duration is indistinguishable from the empty method duration (当看到优化的输出时,这个警告总是让我笑了。)
dotnet/runtime#83054 是另一个好例子。它通过确保比较器可以存储在一个静态的只读字段中,以在消费者中实现更好的常量折叠,从而改进了 Native AOT 中的 EqualityComparer
// dotnet run -c Release -f net7.0 --filter "*" --runtimes nativeaot7.0 nativeaot8.0 using BenchmarkDotNet.Attributes; using BenchmarkDotNet.Running; using System.Runtime.CompilerServices; BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args); [HideColumns("Error", "StdDev", "Median", "RatioSD")] public class Tests { private readonly int[] _array = Enumerable.Range(0, 1000).ToArray(); [Benchmark] public int FindIndex() => FindIndex(_array, 999); [MethodImpl(MethodImplOptions.NoInlining)] private static int FindIndex<T>(T[] array, T value) { for (int i = 0; i < array.Length; i++) if (EqualityComparer<T>.Default.Equals(array[i], value)) return i; return -1; } } | Method | Runtime | Mean | Ratio |
|---|---|---|---|
| FindIndex | NativeAOT 7.0 | 876.2 ns | 1.00 |
| FindIndex | NativeAOT 8.0 | 367.8 ns | 0.42 |
作为另一个例子,dotnet/runtime#83911 避免了一些与静态类初始化相关的开销。正如我们在 JIT 部分讨论的,JIT 能够依赖分层来知道如果一个方法从 tier 0 提升到 tier 1,那么方法访问的静态字段必须已经被初始化,但是在 Native AOT 世界中,分层并不存在,所以这个 PR 添加了一个快速路径检查,以帮助避免大部分的开销。
其他基本的支持也有所改进。例如,dotnet/runtime#79519 改变了 Native AOT 的锁的实现方式,采用了一种混合方法,开始时使用轻量级的自旋锁,然后升级到使用 System.Threading.Lock 类型(这个类型目前是 Native AOT 的内部类型,但可能在 .NET 9 中公开发布)。
VM
粗略地说,VM 是运行时的一部分,不包括 JIT 或 GC。它处理的事情包括装配和类型加载。虽然整个过程中有很多改进,但我将突出三个显著的改进。
首先,dotnet/runtime#79021 优化了将指令指针映射到 MethodDesc(表示方法的数据结构,包含关于它的各种信息,如其签名)的操作,这在任何时候进行堆栈遍历(例如,异常处理,Environment.Stacktrace 等)以及作为一些委托创建的一部分时都会发生。这个改变不仅使这种转换更快,而且大部分都是无锁的,这意味着在以下的基准测试中,对于顺序使用有显著的改进,对于多线程使用的改进甚至更大:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0 using BenchmarkDotNet.Attributes; using BenchmarkDotNet.Running; using System.Runtime.CompilerServices; BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args); [HideColumns("Error", "StdDev", "Median", "RatioSD")] public class Tests { [Benchmark] public void InSerial() { for (int i = 0; i < 10_000; i++) { CreateDelegate<string>(); } } [Benchmark] public void InParallel() { Parallel.For(0, 10_000, i => { CreateDelegate<string>(); }); } [MethodImpl(MethodImplOptions.NoInlining)] private static Action<T> CreateDelegate<T>() => new Action<T>(GenericMethod); private static void GenericMethod<T>(T t) { } } | Method | Runtime | Mean | Ratio |
|---|---|---|---|
| InSerial | .NET 7.0 | 1,868.4 us | 1.00 |
| InSerial | .NET 8.0 | 706.5 us | 0.38 |
| InParallel | .NET 7.0 | 1,247.3 us | 1.00 |
| InParallel | .NET 8.0 | 222.9 us | 0.18 |
其次,dotnet/runtime#83632 提高了 ExecutableAllocator 的性能。这个分配器负责与运行时中所有可执行内存相关的分配,例如,JIT 使用它来获取内存,然后将生成的代码写入这些内存,然后需要执行这些代码。当内存被映射时,它有与之关联的权限,用于确定可以对该内存进行什么操作,例如,是否可以读取和写入,是否可以执行等。分配器维护一个缓存,这个 PR 通过减少缓存未命中的次数和减少这些缓存未命中时的成本来提高分配器的性能。
第三,dotnet/runtime#85743 进行了一系列的改变,主要目的是显著减少启动时间。这包括减少在 R2R 图像中验证类型所花费的时间,由于 R2R 图像中有专用的元数据,使得在 R2R 图像中查找泛型参数和嵌套类型变得更快,通过在方法描述中存储一个额外的索引,将 O(n^2) 的查找转变为 O(1) 的查找,以及确保 vtable 块始终被共享。
GC
在这篇文章的开头,我建议在用于运行这篇文章中的基准测试的 csproj 中添加 <ServerGarbageCollection>true</ServerGarbageCollection>。这个设置将 GC 配置为“服务器”模式,而不是“工作站”模式。工作站模式是为客户端应用程序设计的,资源消耗较少,更倾向于使用较少的内存,但可能以吞吐量和可扩展性为代价,如果系统承受更重的负载。相反,服务器模式是为大规模服务设计的。它对资源的需求要大得多,每个逻辑核心默认有一个专用堆,每个堆有一个专用线程来服务该堆,但它也显著地更可扩展。这种权衡通常会导致复杂性,因为虽然应用程序可能需要服务器 GC 的可扩展性,但它们也可能希望内存消耗接近工作站,至少在需求较低,服务不需要那么多堆的时候。
在 .NET 8 中,服务器 GC 现在支持动态堆计数,这要归功于 dotnet/runtime#86245,dotnet/runtime#87618,和 dotnet/runtime#87619,它们添加了一个被称为“动态适应应用程序大小”或 DATAS 的特性。它在 .NET 8 中通常是默认关闭的(尽管在为 Native AOT 发布时默认开启),但可以很容易地启用,要么通过将 DOTNET_GCDynamicAdaptationMode 环境变量设置为 1,要么通过 <GarbageCollectionAdaptationMode>1</GarbageCollectionAdaptationMode> MSBuild 属性。所使用的算法能够随着时间的推移增加和减少堆计数,试图最大化其对吞吐量的视图,并在此和总体内存占用之间保持平衡。
这里有一个简单的例子。我创建了一个控制台应用程序,.csproj 中有 <ServerGarbageCollection>true</ServerGarbageCollection>,并在 Program.cs 中有以下代码,它只是生成一堆不断分配的线程,然后反复打印出工作集:
// dotnet run -c Release -f net8.0 using System.Diagnostics; for (int i = 0; i < 32; i++) { new Thread(() => { while (true) Array.ForEach(new byte[1], b => { }); }).Start(); } using Process process = Process.GetCurrentProcess(); while (true) { process.Refresh(); Console.WriteLine($"{process.WorkingSet64:N0}"); Thread.Sleep(1000); } 当我运行这个程序时,我一直看到如下的输出:
154,226,688 154,226,688 154,275,840 154,275,840 154,816,512 154,816,512 154,816,512 154,824,704 154,824,704 154,824,704 然后,当我在 .csproj 中添加 <GarbageCollectionAdaptationMode>1</GarbageCollectionAdaptationMode> 时,工作集显著下降:
71,430,144 72,187,904 72,196,096 72,196,096 72,245,248 72,245,248 72,245,248 72,245,248 72,245,248 72,253,440 要更详细地了解这个特性和它的计划,请参阅“动态适应应用程序大小”。
Mono
到目前为止,我已经提到了“运行时”、“JIT”、“GC”等等。这都是在“CoreCLR”运行时的上下文中,这是用于控制台应用程序、ASP.NET 应用程序、服务、桌面应用程序等的主要运行时。然而,对于移动和浏览器 .NET 应用程序,使用的主要运行时是“Mono”运行时。在 .NET 8 中,它也有了一些巨大的改进,这些改进对于像 Blazor WebAssembly 应用这样的场景有所帮助。
正如 CoreCLR 既有 JIT 又有 AOT 的能力一样,Mono 也有多种方式可以发布代码。Mono 包括一个 AOT 编译器;对于 WASM 特别是,AOT 编译器使所有的 IL 都可以编译成 WASM,然后发送到浏览器。然而,就像 CoreCLR 一样,AOT 是可选的。WASM 的默认体验是使用解释器:IL 被发送到浏览器,然后解释器(本身就是编译成 WASM 的)解释 IL。当然,解释有性能影响,所以 .NET 7 增强了解释器,使用了一个类似于 CoreCLR JIT 使用的分层方案。解释器有自己的代码表示,当一个方法被调用几次时,它只是解释那个字节码,几乎不做优化。然后在足够多的调用之后,解释器会花一些时间优化那个内部表示,以加速后续的解释。然而,即使是这样,它仍然是在解释:它仍然是一个在 WASM 中实现的解释器,读取指令并执行它们。在 .NET 8 中,Mono 的最显著的改进之一是在解释器中引入了一个部分 JIT,扩展了这个分层。dotnet/runtime#76477 提供了这个“jiterpreter”的初始代码,有些人就是这样称呼它的。作为解释器的一部分,这个 JIT 能够参与解释器使用的相同的数据结构,并处理相同的字节码,它通过替换那个字节码的序列与即时生成的 WASM 来工作。这可能是一个整个方法,也可能只是一个方法中的热循环,或者只是几条指令。这提供了显著的灵活性,包括一个非常渐进的入口,可以逐步添加优化,将越来越多的逻辑从解释转移到 JIT 的 WASM。数十个 PR 为 .NET 8 的 jiterpreter 成为现实做出了贡献,比如 dotnet/runtime#82773 添加了基本的 SIMD 支持,dotnet/runtime#82756 添加了基本的循环支持,和 dotnet/runtime#83247 添加了一个控制流优化通道。
让我们看看这个在实践中的应用。我创建了一个新的 .NET 7 Blazor WebAssembly 项目,添加了对 System.IO.Hashing 项目的 NuGet 引用,并将 Counter.razor 的内容替换为以下内容:
@page "/counter" @using System.Diagnostics; @using System.IO.Hashing; @using System.Text; @using System.Threading.Tasks; <h1>.NET 7</h1> <p role="status">Current time: @_time</p> <button class="btn btn-primary" @onclick="Hash">Click me</button> @code { private TimeSpan _time; private void Hash() { var sw = Stopwatch.StartNew(); for (int i = 0; i < 50_000; i++) XxHash64.HashToUInt64(_data); _time = sw.Elapsed; } private byte[] _data = @"Shall I compare thee to a summer's day? Thou art more lovely and more temperate: Rough winds do shake the darling buds of May, And summer's lease hath all too short a date; Sometime too hot the eye of heaven shines, And often is his gold complexion dimm'd; And every fair from fair sometime declines, By chance or nature's changing course untrimm'd; But thy eternal summer shall not fade, Nor lose possession of that fair thou ow'st; Nor shall death brag thou wander'st in his shade, When in eternal lines to time thou grow'st: So long as men can breathe or eyes can see, So long lives this, and this gives life to thee."u8.ToArray(); } 然后我做了完全相同的事情,但是对于 .NET 8,我在 Release 中构建了它们,并运行了它们。当每个结果页面打开时,我点击了“Click me”按钮(点击了几次,但结果没有改变)。
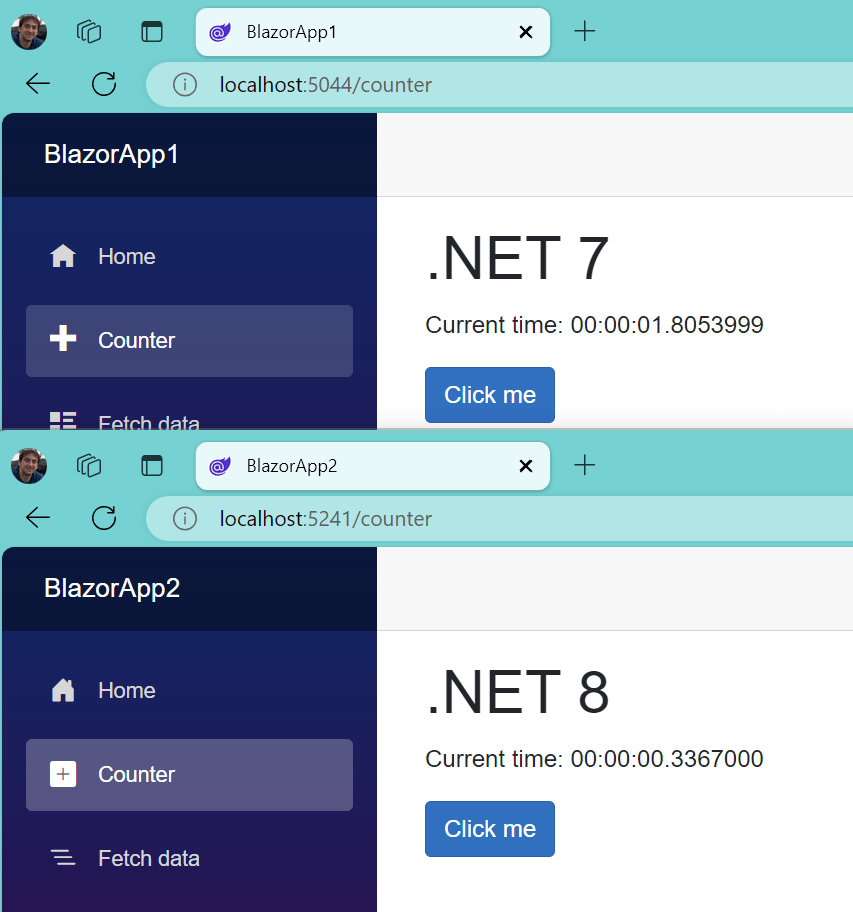
NET 7 与 .NET 8 中操作所需时间的测量结果自明。
除了 jiterpreter,解释器本身也有许多改进,例如:
dotnet/runtime#79165 为 stobj IL 指令添加了特殊处理,当值类型不包含任何引用,因此不需要与 GC 交互。
dotnet/runtime#80046 对比较后的 brtrue/brfalse 进行了特殊处理,为非常常见的模式创建了一个解释器操作码。
dotnet/runtime#79392 为解释器添加了一个用于字符串创建的内置函数。
dotnet/runtime#78840 为 Mono 运行时(包括但不限于解释器)添加了一个缓存,用于存储关于类型的各种信息,如 IsValueType,IsGenericTypeDefinition 和 IsDelegate。
dotnet/runtime#81782 为 Vector128 上的一些最常见操作添加了内置函数,dotnet/runtime#86859 增强了这个功能,以便对 Vector
dotnet/runtime#83498 对 2 的幂的除法进行了特殊处理,以使用移位操作代替。
dotnet/runtime#83490 调整了内联大小限制,以确保关键方法可以被内联,如 List
dotnet/runtime#85528 在有足够类型信息的情况下添加了去虚化支持。
我已经多次提到 Mono 中的向量化,但这本身就是 Mono 在 .NET 8 中的所有后端的一个重点关注领域。截至 dotnet/runtime#86546,该 PR 完成了对 Mono 的 AMD64 JIT 后端的 Vector128 支持,现在所有的 Mono 后端都支持 Vector128。Mono 的 WASM 后端不仅支持 Vector128,.NET 8 还包括新的 System.Runtime.Intrinsics.Wasm.PackedSimd 类型,这是特定于 WASM 的,并暴露了数百个重载,这些重载映射到 WASM SIMD 操作。这个类型的基础在 dotnet/runtime#73289 中引入,其中添加了初始的 SIMD 支持作为内部功能。dotnet/runtime#76539 通过添加更多功能并将类型公开,继续了这项工作,就像现在在 .NET 8 中一样。十几个 PR 继续构建它,比如 dotnet/runtime#80145 添加了 ConditionalSelect 内置函数,dotnet/runtime#87052 和 dotnet/runtime#87828 添加了加载和存储内置函数,dotnet/runtime#85705 添加了浮点支持,以及 dotnet/runtime#88595,它根据自初始设计以来的学习成果对表面区域进行了改造。
.NET 8 中,另一个与应用大小相关的工作是减少对 ICU 数据文件的依赖(ICU 是 .NET 和许多其他系统使用的全球化库)。相反,目标是尽可能依赖目标平台的原生 API(对于 WASM,由浏览器提供的 API)。这个工作被称为“混合全球化”,因为对 ICU 数据文件的依赖仍然存在,只是减少了,并且它带来了行为上的变化,所以它是可选的,适用于真正希望减小大小并愿意处理行为适应的情况。许多 PR 也为 .NET 8 实现这一目标做出了贡献,如 dotnet/runtime#81470,dotnet/runtime#84019 和 dotnet/runtime#84249。要启用这个特性,你可以在你的 .csproj 中添加
![[C#] Bgr24彩色位图转为灰度的Bgr24位图的跨平台SIMD硬件加速向量算法](https://www.ztsky.cn/wp-content/themes/ztsky/img/random/12.jpg)



