- A+
1. 常见的数据结构
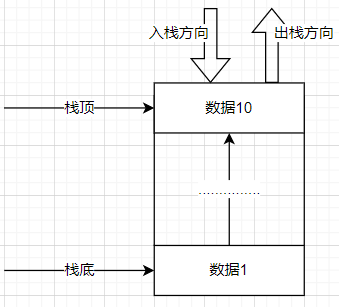
1. 栈(stack)
特点:先进后出,后进先出
2. 队列(Queue)
特点:先进先出

3. 数组(Array)

-
查询速度快:通过地址值与索引可快速定位到数据
-
删除效率低:删除数据后,要将每个数据前移
-
添加效率极低:添加位置后,每个数据都后移,再添加数据。
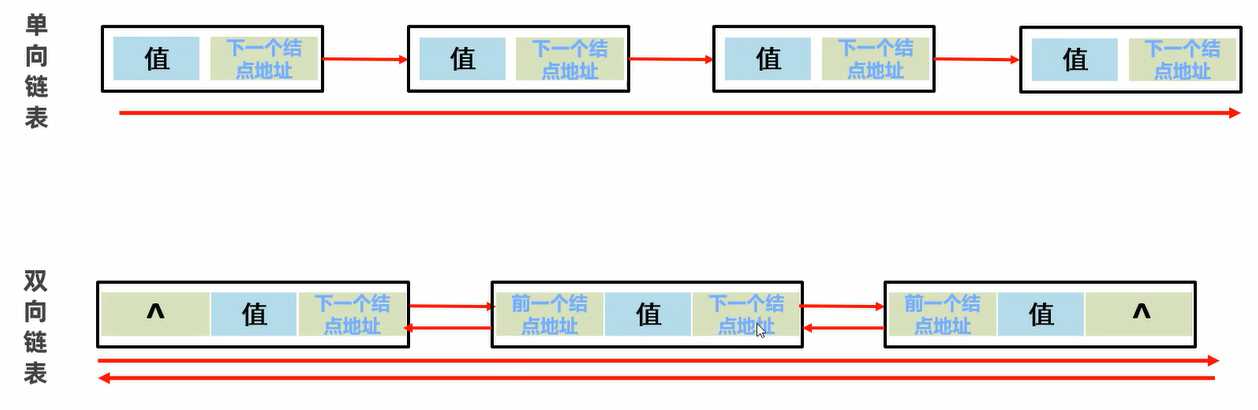
4. 链表

-
链接中的数据都是游离存储的,每个元素节点包含元素值与下一个元素的地址
-
查询速度慢,因为每次查询都要通过head 指针依次查询
-
添加,删除效率相对较高,因为只需要将指针重新指向新添加进来的元素,其他元素的位置不需要动。
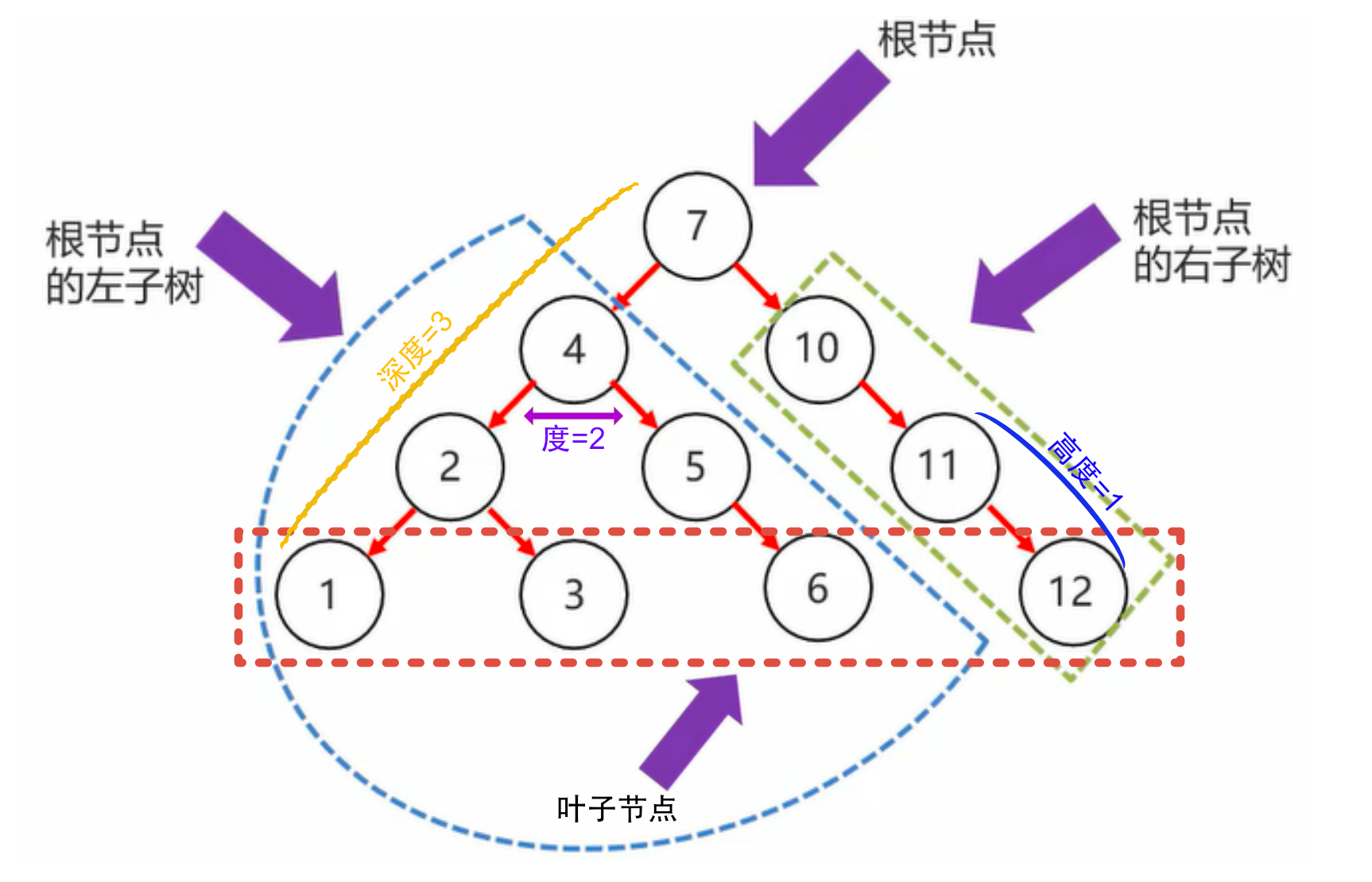
5. 二叉树
二叉树,全名叫二叉搜索树。存入的数据以第一条数据为基准,小于放左,大于放右。
-
只能有一个根节点,每个节点最多支持两个直接子节点
-
节点的度:节点拥有的子数的个数。节点的度数不大于2,如果度数为0,则称为叶子节点或者终端节点。
-
二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数。
-
二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数。
缺点:
虽然二叉树可以提高一些效率,但是面对节点多时,或者树的深度很高时,还是会面临着查找速度慢的情况,而且还很容易出现退化链表情况( 存放数据是有序 的时候)。
6. 平衡二叉树
数据结构在线地址: Data Structure Visualization (usfca.edu)
平衡二叉树是在满足二叉查找树的情况下,尽可能的让树的度数变低,以提高查询效率。
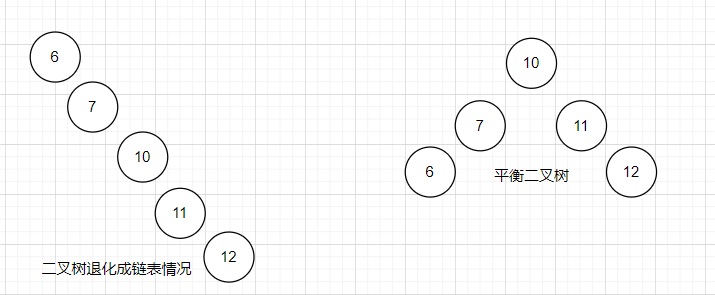
要求:任意节点的两个左右子树高度差不超过1,任意节点的左右子树都是一个平衡二叉树。
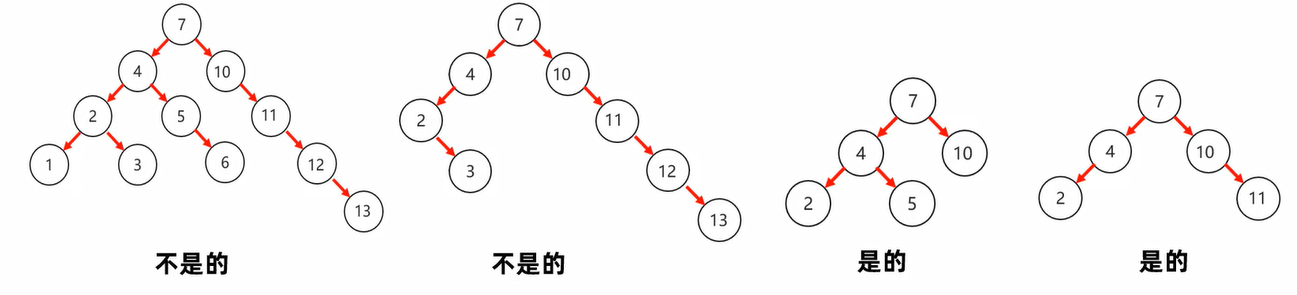
他底层在二叉树的基础上,对进行插入和删除操作时通过特定操作(如左旋转,右旋转等)保持二叉查找树的平衡,从而获得较高的查找性能。
什么是左旋转,右旋转呢?
左旋转:被旋转的节点从左侧上升到父节点
右旋转:被旋转的节点从右侧上升到父节点
缺点:
-
树的深度过高,还是查询慢
-
无法解决回旋查找问题。
-
添加节点效率过低,因为节点旋转有可能牵一发而动全身
7. 红黑树
红黑树是一种自平衡的二叉查找树,是计算机中用到的一种数据结构,1972年出现,当时又被称为“平衡二叉B树”。1978年被修改为“红黑树”。每一个节点可以是红或者黑;红黑树不是通过高度平衡的,它的平衡是通过“红黑规则”进行实现的。
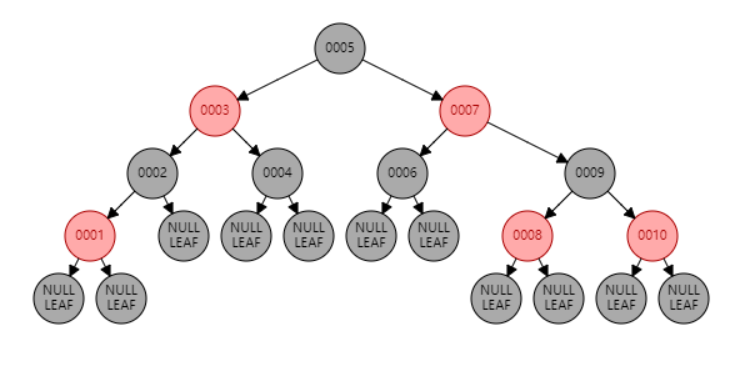
红黑规则:
-
每一个节点或是红色的,或者是黑色的,根节点必须是黑色。
-
如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)。
-
对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点。
-
如果一个节点没有子节点或者父节点,则该节点的相应指针属性值为Null,这些Null视为叶节点,叶节点是黑色。
添加节点:
-
添加的节点的颜色,可以是红色的,也可以是黑色的。
-
默认用红色效率高。(调整节点的次数会相对减少)
红黑树增删改查性能都比较好。
相对于要求严格的AVL树来说,它的旋转次数变少,所以对于搜索、插入、删除操作多的情况下,我们就用红黑树。
缺点: 虽然红黑树的深度已经较二叉树有所提升,但是当数据量过大时,如上万或者上百万条数据时他是深度会随之变高。效率较慢,而且红黑树和二叉树都有一个问题,就是回旋查找。
回旋查找
红黑树笔记中的案例图,要找比 6 小的数,它需要先找到6的位置然后回旋回去找父节点7,然后7还要去找5,然后一级一级找出所有小于6的数据 ,这样就十分缓慢 。
8. B 树
B树又称为多路平衡树。(Balance Tree),也叫B-树,他在树的基础上对节点进行横向的拉伸
B-树有如下特点:
所有键值分布在整颗树中(索引值和具体data都在每个节点里);
任何一个关键字出现且只出现在一个结点中;
搜索有可能在非叶子结点结束(最好情况O(1)就能找到数据);
在关键字全集内做一次查找,性能逼近二分查找;
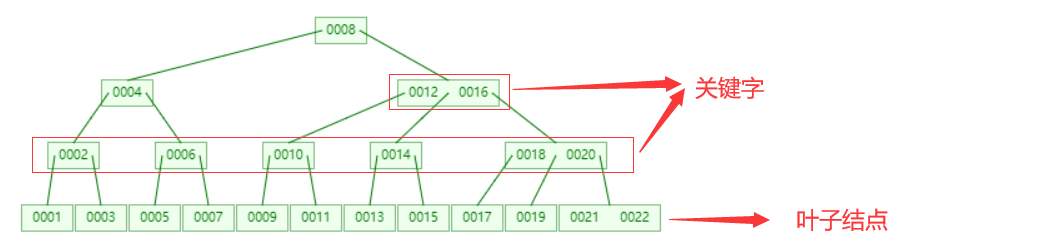
规则
-
每个结点最多有m个棵子树(m 称为阶)
-
除根结点外,其他每个分支结点至少有ceiling(m/2)棵子树 (ceiling 表示向上取整)
-
根结点至少包含两棵子树(除非B树只包含一个结点)
-
所有叶结点在同一层上,B树叶结点可以外成是外部结点,不包含任何信息。
-
有j 个孩子的非叶子结点恰好有 j-1 个关键字(关键码),关键码按递增次序排列。
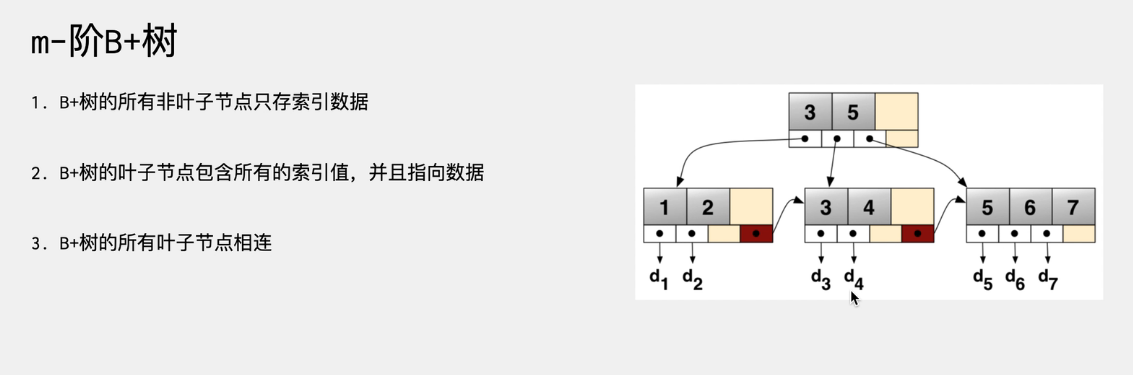
9. B+树
也是一种多路搜索树,和B树类似,B+树是B-树的变体,但对B树的基础上,做了一些改变,类似于C/C++。
一棵m阶的B+树主要有这些特点:
-
每个结点至多有m个子女;
-
非根节点关键值个数范围:ceiling⌈m/2⌉ - 1 <= k <= m-1
-
相邻叶子节点是通过指针连起来的,并且是关键字大小排序的。
一颗3阶的B+树如下:

B+树和B-树的主要区别如下:
-
B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。
-
B+树相邻的叶子节点之间是通过链表指针连起来的,B-树却不是。
-
查找过程中,B-树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束
-
B-树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多次。
B+树的插入 B+树插入要记住这几个步骤:
-
1.B+树插入都是在叶子结点进行的,就是插入前,需要先找到要插入的叶子结点。
-
2.如果被插入关键字的叶子节点,当前含有的关键字数量是小于阶数m,则直接插入。
-
3.如果插入关键字后,叶子节点当前含有的关键字数目等于阶数m,则插,该节点开始「分裂」为两个新的节点,一个节点包含⌊m/2⌋ 个关键字,另外一个关键字包含⌈m/2⌉个关键值。(⌊m/2⌋表示向下取整,⌈m/2⌉表示向上取整,如⌈3/2⌉=2)。
-
4.分裂后,需要将第⌈m/2⌉的关键字上移到父结点。如果这时候父结点中包含的关键字个数小于m,则插入操作完成。
-
5.分裂后,需要将⌈m/2⌉的关键字上移到父结点。如果父结点中包含的关键字个数等于m,则继续分裂父结点。
2. 索引
作用
提高查询速度.
定义
将结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,我们将这部分信息称之为索引.
1. 索引分类
聚集索引
聚集索引是一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。聚集索引也称为聚簇索引(Clustered Index) , 聚集索引是物理地址连续存放的索引
特点:只能有一个, 一般为主键(主键一定是聚集索引,聚集索引并不一定是主键)
什么情况下主键不是聚集索引呢?
答:在建表的时候,并没有加主键,这个时候如果说建立了一个聚集索引,再建立主键,那么这个时候主键就不是聚集索引了。
非聚集索引
非聚集索引(NonClustered Index)是表中记录的物理顺序和逻辑顺序不同的索引 (此外还有空间索引、筛选索引、XML索引)
特点:可以有多个(999)
索引说明
-
每张表上最大的聚集索引数为1;
-
每张表上最大的非聚集索引数为999;
-
每个索引最多能包含的键列数为16;
-
索引键记录大小最多为900字节
2. 索引数据结构
在SQL Server数据库中,索引的存储是以B+树(注意和二叉树的区别)结构来存储的,又称索引树,其节点类型为如下两种:
-
索引节点(Key);
-
叶子节点( Key + Value)
索引节点按照层级关系,有时又可以分为根节点和中间节点,其本质是一样的,都只包含下一层节点的入口值和入口指针;
叶子节点就不同了,它包含数据,这个数据可能是表中真实的数据行,也有可能是索引列值和行书签,前者对应于聚集索引,后者对应于非聚集索引。
名词介绍
B+Tree:一种数据结构( 也是一种多路平衡搜索树 )
数据页:数据库保存数据的最小单位。(SQL Server一个数据页的大小是 8K,一个表中所有的数据都被保存到一个个的数据页中)
索引组织表:大白话一张表有聚集索引就是索引组织表(把表中的数据页以 B+Tree 的方式组织起来)
索引表:一个索引对应一张索引表,索引表中每条数据都对应一张数据页。
3. 索引为什么选择B+树
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
个人 认为数据库索引采用B+树的主要原因是:B树在提高了IO性能的同时并没有解决元素遍历效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
4. 索引设计原则
是不是索引越多越好?
肯定不行。
-
索引也是需要空间存储,索引太多意味着占用的空间也越多。
-
索引页也需要系统维护,在增、删、改 数据时索引需要重新编排。就好像一本书某一页被撕掉了,对应的目录也需要重新进行编排。
-
索引堆积久了,由于维护数据过程中会产生过多的索引碎片,反而不利于数据查询。
什么情况下可以建立索引?
-
主键一定要建
-
外键一定要
-
经常查询的列
-
经常用作查询条件的列
-
经常用在order by ,group by, distinct 后面的列
-
重复值比较多的列不能建立索引
-
对于
text,image,bit这些类型的字段不能建立索引 -
经常存取的列不要建立索引
5. 使用索引
语法格式
create [unique] [clustered / nonclustered] index index_name on table_name(column_name1, column_name2, …)
unique:唯一索引
clustered:聚集索引
nonclustered:非聚集索引
index_name:索引名称
-- 建立聚集索引 create clustered index idx_userinfo_Id on UserInfo(Id); -- 创建非聚集索引(nonclustered 可省略) create nonclustered index idx_userinfo_Account on UserInfo(Account); -- 创建唯一非聚集索引 create unique nonclustered index idx_userinfo_pwd on UserInfo(Pwd);
唯一特点:索引字段必须唯一,但可以有一个值为NULL
查看索引
exec sp_helpindex 'dbo.UserInfo'
重命名索引
-- 重命名索引 -- exec sp_rename '表名.旧索引名','新索引名','index'; exec sp_rename 'userinfo.idx_userinfo_pwd','idx_userinfo_password','index';
删除索引
drop index idx_userinfo_Id on UserInfo
重建索引
alter index 索引名称 on 数据表名 rebuild
3. 视图
视图的作用:
-
提高安全性
-
简化查询过程
什么是视图
视图是用于简化查询过程、提高数据库安全性的数据库虚拟表对象。视图的本质,其实就是一堆封装好的SQL。
如何使用视图
创建视图
语法格式:
create view 视图名称 as select column_name from table_name [where 条件] --创建视图 create view v_studentscore as select a.*,b.Degree,c.Cno,Cname,d.* from Student a inner join Score b on a.Sno=b.Sno inner join Course c on b.Cno=c.Cno inner join Teacher d on c.Tno=d.Tno --使用视图 select * from v_studentscore where nickname='张旭'
修改视图
一定要记得把创建视图的代码保存起来,免得下次修改视图的时候,又要重新写一遍代码,特别是被加密的视图代码。
alter view v_studentscore --with encryption -- 加密 as select a.*,b.Degree,c.Cno,Cname,d.* from Student a inner join Score b on a.Sno=b.Sno inner join Course c on b.Cno=c.Cno inner join Teacher d on c.Tno=d.Tno
删除视图
--删除视图
drop view v_studentscore
视频配套链接:【SQLServer 数据库高级阶段】.net 6 开发系列 ,全网最新,最全!(已完结)_哔哩哔哩_bilibili
![[C#] Bgr24彩色位图转为灰度的Bgr24位图的跨平台SIMD硬件加速向量算法](https://www.ztsky.cn/wp-content/themes/ztsky/img/random/14.jpg)



