- A+
所属分类:.NET技术
博客后台接口优化-访问记录?
前言
博客地址:ZY知识库 · ZY - Home Page (pljzy.top) www.pljzy.top
一直没有更新文章了,曾梦想着每周更新一篇文章。直到上班之后才知道,根本不想写。我现在的状态就是下班回家吃完晚饭刷会视频看会剧,洗个澡儿,睡觉。下班之后根本不想写代码??。
如果是双休的话我可能会一周一更,但是单休的程序员,我真的一点动力都没有,已经被资本家压榨得干干净净了。
回到正题,虽然文章没有更新,但是博客还是有收到各大搜索引擎的爬虫(除开百度,因为博客备案到期了,我换到香港服务器了,百度不会爬取),导致访问记录持续增加,现在访问记录已经有172875条记录了

问题解析
博客很多地方的分页都是用的一款组件,叫做X.PagedList组件,这款组件使用起来还是方便的,但是他是将数据全部查询出来,加载到内存中进行分页,相当于我从数据库一次拿了172875条数据出来,然后进行分页。如果不搭配缓存的话,这样分页的效率是很低的。
抛开网络传输,本地测试看看接口响应需要多久,本地跑只要1.48秒,线上跑需要花7.99秒
本地

线上

那么就针对本地1.48秒进行优化。
解决办法
既然一次性去10万条数据慢,那我何不在查询sql的时候就分页呢。所以当我们去向数据库拿取数据的时候就只拿取当前页的数据,具体实现如下:
原本写法
public IPagedList<VisitRecord> GetPagedList(VisitRecordQueryParameters param) { var querySet = _myDbContext.visitRecords.ToArray(); // 搜索 if (!string.IsNullOrEmpty(param.Search)) { querySet = querySet.Where(a => a.RequestPath.Contains(param.Search)).ToArray(); } querySet = querySet.OrderByDescending(a => a.Id).ToArray(); return querySet.ToList().ToPagedList(param.Page, param.PageSize); } 生成的sql语句,放到数据库执行如下:
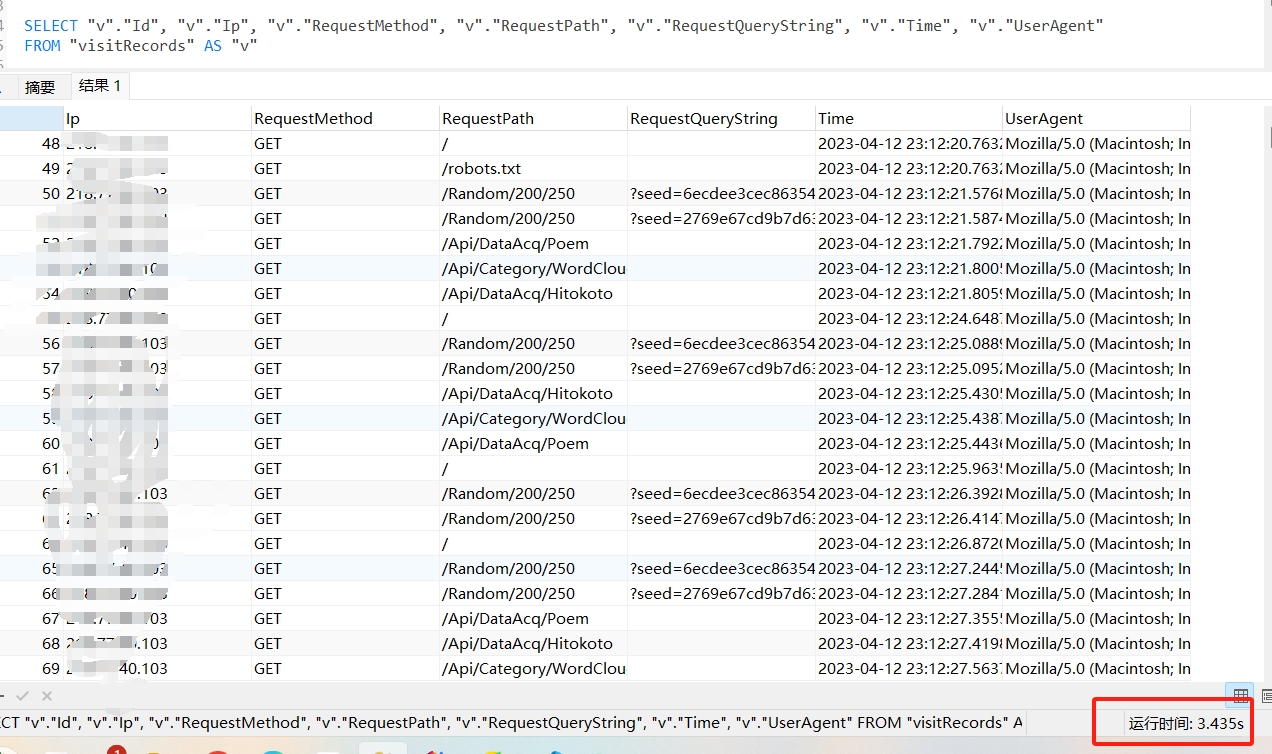
修改写法
public async Task<(List<VisitRecord>, PaginationMetadata)>GetPagedList(VisitRecordQueryParameters param) { var querySet = _myDbContext.visitRecords.AsQueryable(); // 搜索 if (!string.IsNullOrEmpty(param.Search)) { querySet = querySet.Where(a => a.RequestPath.Contains(param.Search)); } var data = await querySet .OrderByDescending(a => a.Id) .Skip((param.Page - 1) * param.PageSize) .Take(param.PageSize) .ToListAsync(); var pagination = new PaginationMetadata() { PageNumber = param.Page, PageSize = param.PageSize, TotalItemCount = await querySet.CountAsync() }; return (data, pagination); } 修改后生成的sql语句如下,在数据库分页。
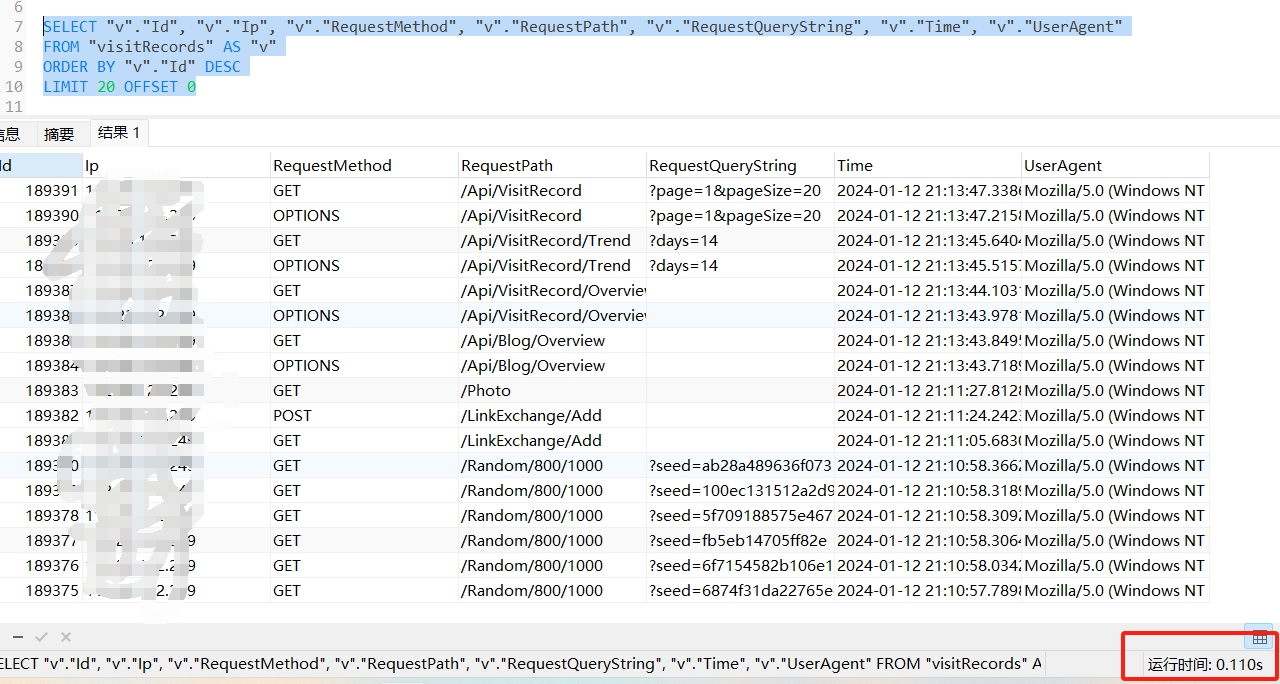
优化对比


可以看到还是优化了挺多的。
结尾
当数据量到达百万级,又该如何优化呢?
如果大家有更好的办法,可以评论私信~
如果不想自己写返回分页数据的类,可以使用CodeLab.Share,Nuget包。




