- A+
本章将和大家分享 Elasticsearch 的一些基本操作。话不多说,下面我们直接进入主题。
一、索引库操作
1、settings属性
settings属性可以设置索引库的一些配置信息,例如:配置分片数和副本数、配置自定义分词器等。
其中分片数量只能在一开始创建索引库的时候指定,后期不能修改。副本数量可以随时修改。
2、mapping属性
mapping属性是对索引库中文档的约束,常见的mapping属性包括:
1)type:字段数据类型,常见的数据类型在上一章已经介绍过了,此处就不再做过多的描述了。
2)index:是否需要创建倒排索引,默认值为true,如果设置为false那么表明该字段不能被检索,不构建倒排索引。因此,需要根据具体的业务判断该字段将来是否需要参与检索,如果需要的话就设置为true,否则就设置为false。
3)analyzer:使用哪种分词器,一般结合text(可分词的文本)数据类型一起使用。
4)properties:该字段的子字段。
3、创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:
PUT /索引库名称 { "mappings": { "properties": { "字段名":{ "type": "text", //分词 "analyzer": "ik_smart" //指定分词器 }, "字段名2":{ "type": "keyword", //不分词 "index": "false" //不创建倒排索引,不参与搜索 }, "字段名3":{ "type": "object", //对象类型 "properties": { "子字段": { "type": "keyword" } } }, // ...略 } } }
示例:
# 创建索引库 PUT /my_index { "mappings": { "properties": { "info":{ "type": "text", "analyzer": "ik_smart" }, "email":{ "type": "keyword", "index": false }, "name":{ "type": "object", "properties": { "firstName":{ "type":"keyword" }, "lastName":{ "type":"keyword" } } } } } }
运行结果如下所示:

{ "acknowledged" : true, "shards_acknowledged" : true, "index" : "my_index" }
4、查看索引库
查看索引库语法:
GET /索引库名
示例:
# 查看索引库 GET /my_index
运行结果如下所示:
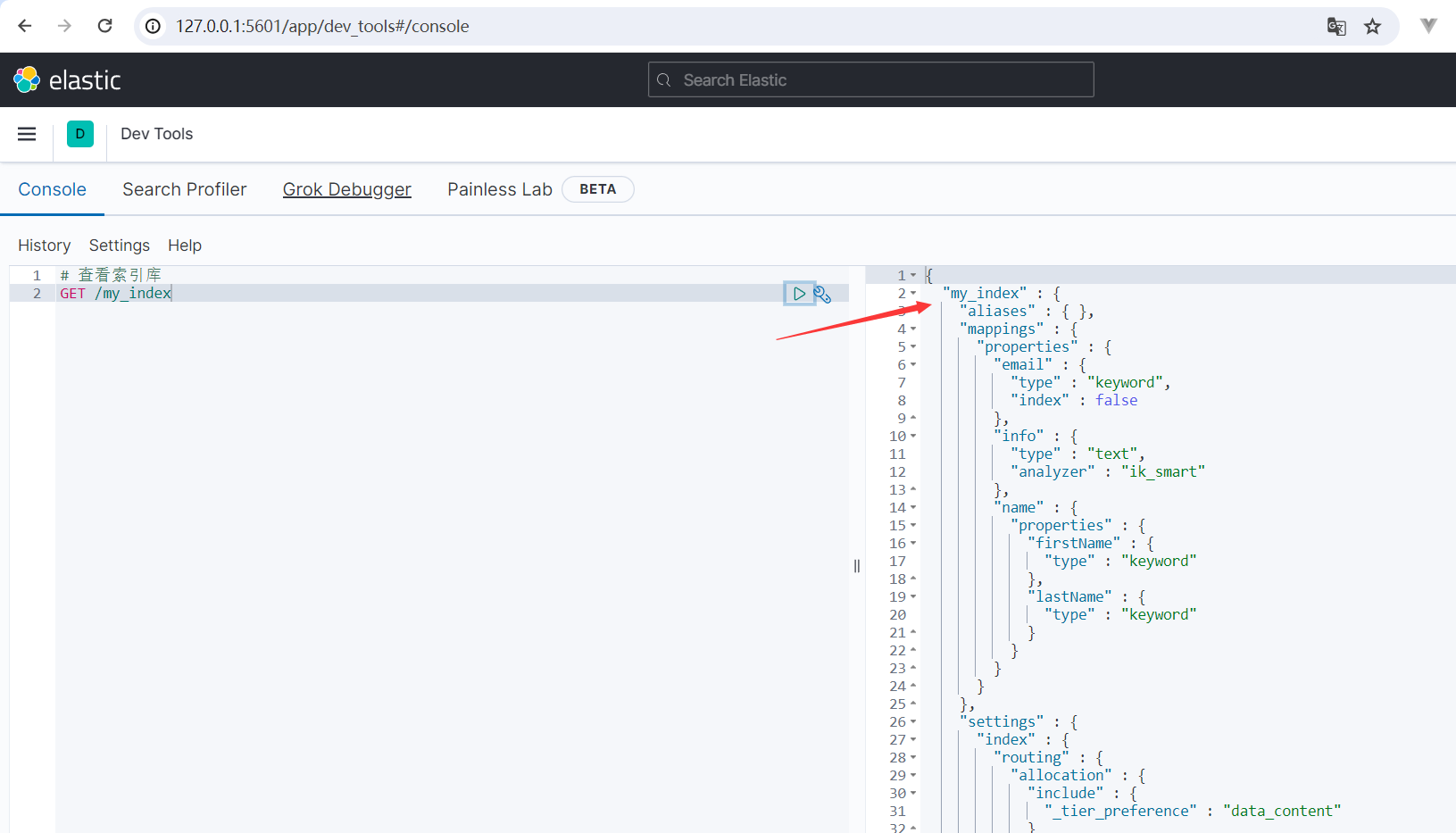
{ "my_index" : { "aliases" : { }, "mappings" : { "properties" : { "email" : { "type" : "keyword", "index" : false }, "info" : { "type" : "text", "analyzer" : "ik_smart" }, "name" : { "properties" : { "firstName" : { "type" : "keyword" }, "lastName" : { "type" : "keyword" } } } } }, "settings" : { "index" : { "routing" : { "allocation" : { "include" : { "_tier_preference" : "data_content" } } }, "number_of_shards" : "1", "provided_name" : "my_index", "creation_date" : "1701011238882", "number_of_replicas" : "1", "uuid" : "qb-XkR5xQ2y7WvohoWVw_Q", "version" : { "created" : "7120199" } } } } }
5、修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT /索引库名/_mapping { "properties": { "新字段名":{ "type": "integer" } } }
示例:
# 修改索引库,添加新的字段 PUT /my_index/_mapping { "properties": { "age": { "type": "integer" } } }
运行结果如下所示:

6、删除索引库
删除索引库的语法:
DELETE /索引库名
示例:
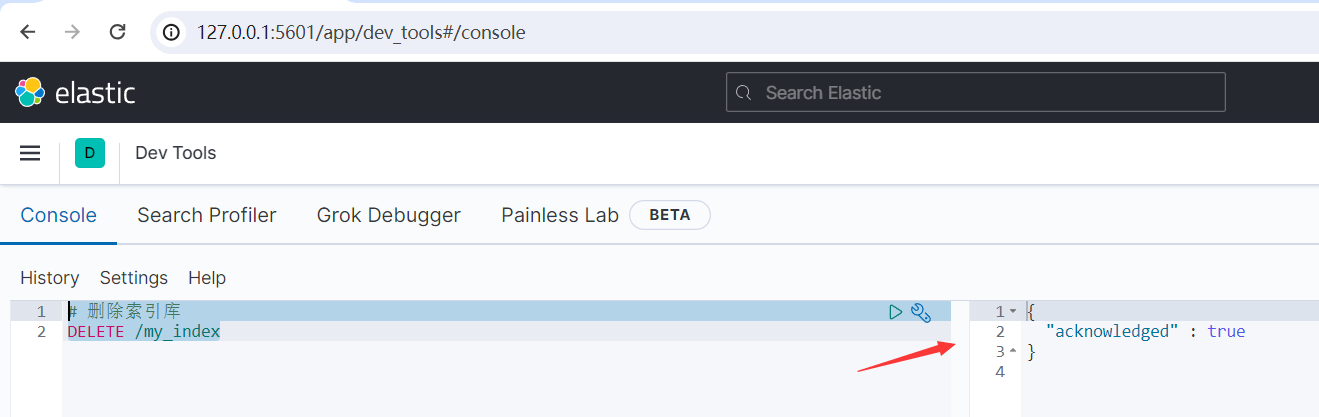
# 删除索引库 DELETE /my_index
运行结果如下所示:
二、文档操作
1、新增文档
新增文档的DSL语法如下:
POST /索引库名/_doc/文档id { "字段1": "值1", "字段2": "值2", "字段3": { "子属性1": "值3", "子属性2": "值4" }, // ... }
示例:
# 新增文档 POST /my_index/_doc/1 { "info": "黑马程序员菜鸟学员", "email": "12306@163.com", "name": { "firstName": "武", "lastName": "王" } }
运行结果如下所示:

{ "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 }
2、查询文档
查询文档的DSL语法如下:
GET /索引库名/_doc/文档id
示例:
# 查询文档 GET /my_index/_doc/1
运行结果如下所示:
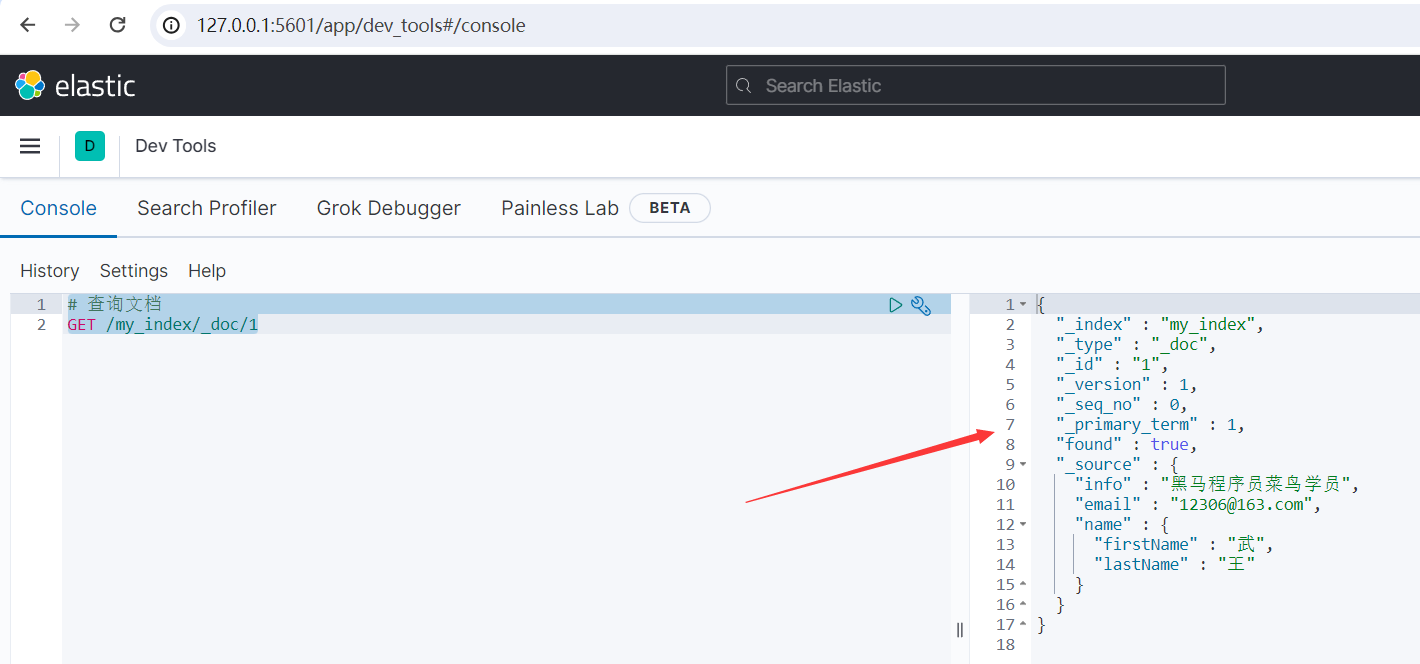
{ "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "info" : "黑马程序员菜鸟学员", "email" : "12306@163.com", "name" : { "firstName" : "武", "lastName" : "王" } } }
3、修改文档
方式一:全量修改文档,会删除旧文档,添加新文档。该方式既可以修改文档,也可以新增文档。对应的DSL语法如下:
PUT /索引库名/_doc/文档id { "字段1": "值1", "字段2": "值2", // ... 略 }
示例:
# 全量修改文档 PUT /my_index/_doc/1 { "info": "黑马程序员菜鸟学员,奥利给", "email": "12306@163.com", "name": { "firstName": "武", "lastName": "王" } }
运行结果如下所示:

方式二:局部修改(增量修改)文档字段,修改指定字段值。对应的DSL语法如下:
POST /索引库名/_update/文档id { "doc": { "字段名": "新的值", } }
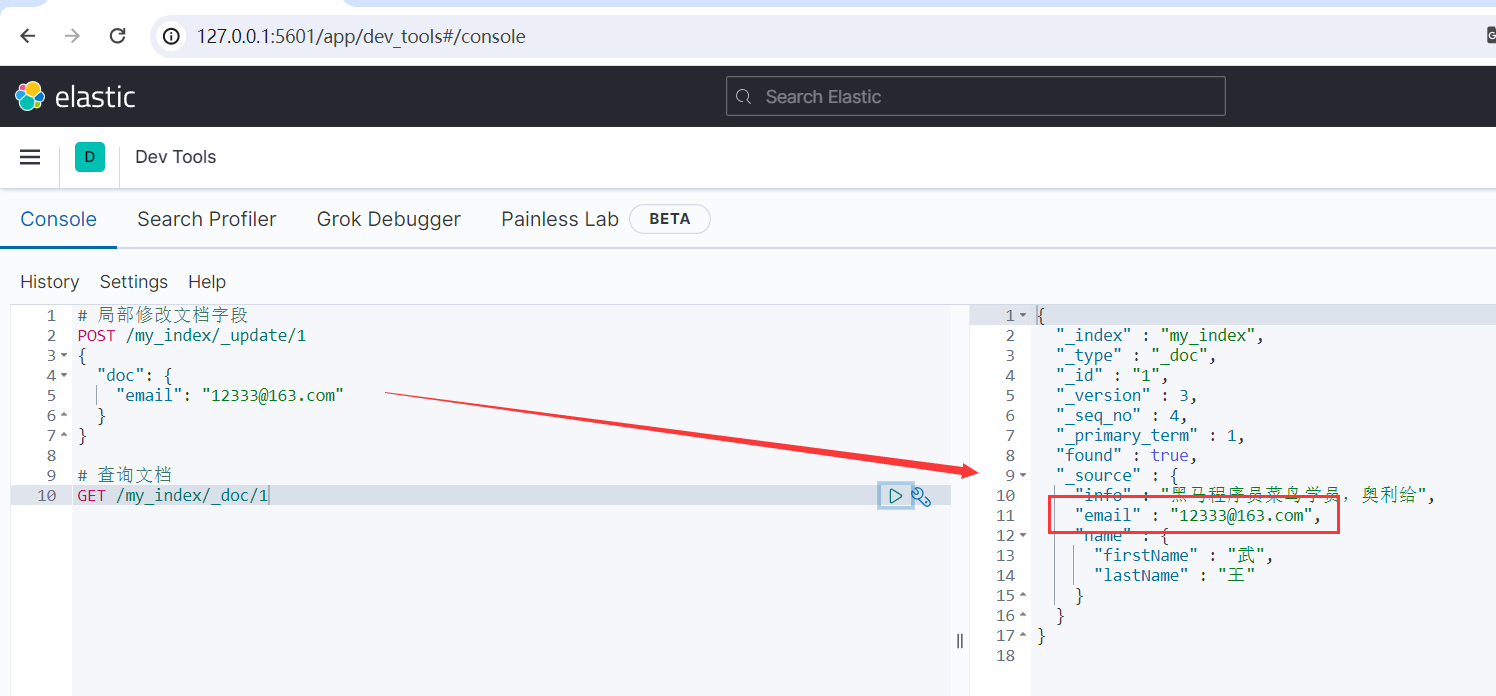
示例:
# 局部修改文档字段 POST /my_index/_update/1 { "doc": { "email": "12333@163.com" } }
运行结果如下所示:

4、删除文档
删除文档的DSL语法如下:
DELETE /索引库名/_doc/文档id
示例:
# 删除文档 DELETE /my_index/_doc/1
运行结果如下所示:

{ "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "deleted", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1 }
三、Query DSL 查询语法
1、数据准备
案例:根据提供的酒店数据创建索引库,索引库名称为hotel,mapping属性根据数据库表结构来定义。

其中 MySQL 数据库中 tb_hotel 酒店表的表结构如下所示:
CREATE TABLE `tb_hotel` ( `id` bigint(20) NOT NULL COMMENT '酒店id', `name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店', `address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路', `price` int(10) NOT NULL COMMENT '酒店价格;例:329', `score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分', `brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家', `city` varchar(32) NOT NULL COMMENT '所在城市;例:上海', `star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻', `business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥', `latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497', `longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925', `pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
首先分析其数据结构,在创建相应索引库做 mapping 映射时要考虑的问题,如下:
1)字段名、数据类型、是否参与搜索、是否分词、如果分词,分词器是什么?
2)ES中支持两种地理坐标数据类型,具体要使用哪一种?
- geo_point:由纬度(latitude)和经度(longitude)确定的一个点。例如:"32.8752345, 120.2981576"
- geo_shape:有多个geo_point组成的复杂几何图形。例如一条直线,"LINESTRING (-77.03653 38.897676, -77.009051 38.889939)"
很明显我们的酒店在地球上就是一个小点,因此要使用 geo_point 类型。
3)字段拷贝,可以使用 copy_to 属性将当前字段拷贝到指定字段。
示例:
"all": { "type": "text", "analyzer": "ik_max_word" }, "brand": { "type": "keyword", "copy_to": "all" }
分析完成后,接着我们就可以去创建相应的索引库了,如下所示:
# 创建酒店数据索引库 PUT /hotel { "settings": { "analysis": { "analyzer": { "text_anlyzer": { "tokenizer": "ik_max_word", "filter": "py" }, "completion_analyzer": { "tokenizer": "keyword", "filter": "py" } }, "filter": { "py": { "type": "pinyin", "keep_full_pinyin": false, "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "id": { "type": "keyword" }, "name": { "type": "text", "analyzer": "text_anlyzer", "search_analyzer": "ik_smart", "copy_to": "all" }, "address": { "type": "keyword", "index": false }, "price": { "type": "integer" }, "score": { "type": "integer" }, "brand": { "type": "keyword", "copy_to": "all" }, "city": { "type": "keyword" }, "starName": { "type": "keyword" }, "business": { "type": "keyword", "copy_to": "all" }, "location": { "type": "geo_point" }, "pic": { "type": "keyword", "index": false }, "all": { "type": "text", "analyzer": "text_anlyzer", "search_analyzer": "ik_smart" }, "suggestion": { "type": "completion", "analyzer": "completion_analyzer" } } } }
其中需要特别注意的是:
1)此处的 id 并不是定义成 long 类型,这是因为在 ES 中 id 字段比较特殊,我们一般都会把它定义成固定的 keyword 类型。
2)此处的 index 属性表示该字段是否需要参与搜索,默认值为 true 表示需要参与搜索,如果该字段不需要参与搜索则可以手动把它设置成 false 。
3)数据库中的 longitude(经度)字段 和 latitude(纬度)字段 合并成了 ES 中的 location(地理坐标) 字段,字段类型为 geo_point ,它的值其实就是字符串类型,由经度和纬度的字段值使用英文逗号拼接而成。
4)字段拷贝,可以使用 copy_to 属性将当前字段拷贝到指定字段上(字段名称可以随意)。我们知道根据一个字段去搜索的效率要明显高于根据多个字段去搜索的效率,但是有些需求就是需要根据多个字段去搜索,这时候就可以使用 copy_to 属性了,可以将多个需要同时搜索的字段拷贝到某个指定的字段上,将来再根据这个指定的字段来搜索,这样子就可以提升查询效率了。copy_to 能够实现在一个字段里面搜索多个字段的内容,而且这种拷贝它还做了优化,它并不是真的把文档拷贝进去了,而只是基于它创建倒排索引,所以将来你去查的时候其实你是看不到这个字段的,虽然看不到但是搜索却能根据它搜,这就很完美了。
最后可以通过 NEST 高级客户端将 MySQL 数据库中的酒店数据批量插入到我们的ES中,此步骤暂时先跳过,在后续的文章中我们会专门介绍 .Net 如何通过 NEST 高级客户端来操作我们的ES。

2、DSL查询分类
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
常见的查询类型包括:
1)查询所有:不加条件限制,查询出所有数据,一般测试用,虽然是查所有,但是它也会受到分页的限制,默认的也只会返回一部分数据。例如:
- match_all
2)全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。全文检索查询一般都是用来查text类型的字段(即需要分词的字段)。例如:
- match_query
- multi_match_query
3)精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。精确查询一般都是用来查不分词的字段。例如:
- ids
- range
- term
4)地理(geo)查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
5)复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
3、DSL基本语法
查询的基本语法如下:
GET /indexName/_search { "query": { "查询类型": { "查询条件": "条件值" } } }
示例:
# 查询所有 GET /hotel/_search { "query": { "match_all": {} } }
运行结果如下所示:

4、全文检索查询
全文检索查询,会对用户输入内容分词,常用于搜索框搜索:
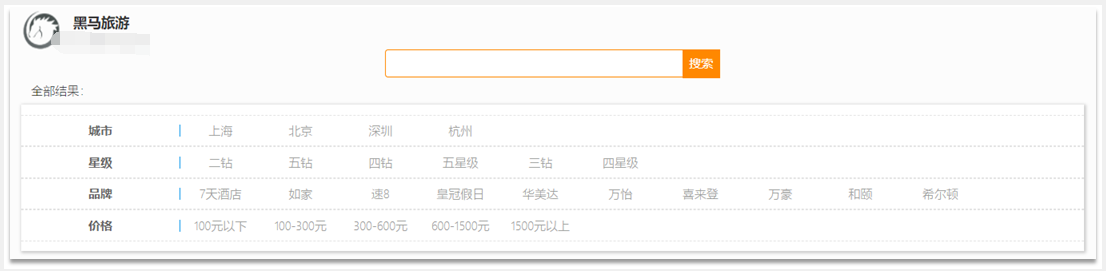

1)match查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索,语法如下:
GET /indexName/_search { "query": { "match": { "FIELD": "TEXT" } } }
示例:
# match查询 GET /hotel/_search { "query": { "match": { "all": "外滩如家" } } }
2)multi_match查询:与match查询类似,只不过允许同时查询多个字段,语法如下:
GET /indexName/_search { "query": { "multi_match": { "query": "TEXT", "fields": ["FIELD1", " FIELD12"] } } }
示例:
# multi_match查询 GET /hotel/_search { "query": { "multi_match": { "query": "外滩如家", "fields": ["brand", "name", "business"] } } }
3)match和multi_match的区别是什么?
- match:根据一个字段查询
- multi_match:根据多个字段查询,参与查询字段越多,查询性能越差。需要根据多个字段查询时建议使用 copy_to 属性。
5、精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段。
- range查询:根据数值范围查询,可以是数值、日期的范围。
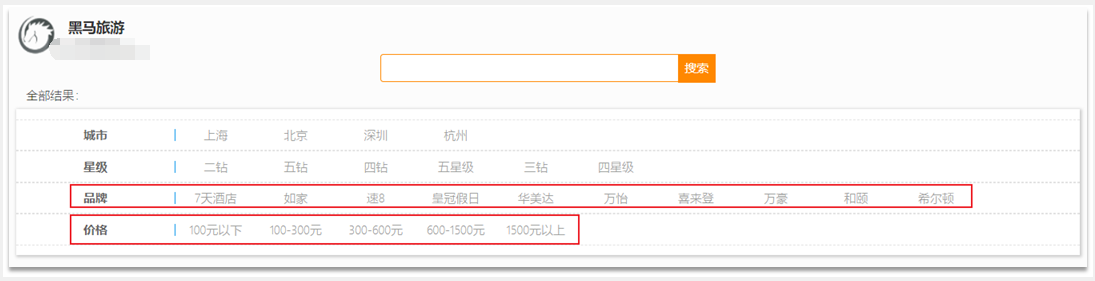
1)term查询,语法如下:
// term查询 GET /indexName/_search { "query": { "term": { "FIELD": { "value": "VALUE" } } } }
示例:
# term查询 GET /hotel/_search { "query": { "term": { "brand": { "value": "7天酒店" } } } }
2)range查询,语法如下:
// range查询 GET /indexName/_search { "query": { "range": { "FIELD": { "gte": 10, "lte": 20 } } } }
示例:
# range查询 GET /hotel/_search { "query": { "range": { "price": { "gte": 100, "lte": 150 } } } }
6、地理查询
根据经纬度查询,常见的使用场景包括:
- 携程:搜索我附近的酒店
- 滴滴:搜索我附近的出租车
- 微信:搜索我附近的人
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-queries.html
1)geo_bounding_box查询:查询geo_point值落在某个矩形范围内的所有文档。

语法如下:
# geo_bounding_box查询 GET /indexName/_search { "query": { "geo_bounding_box": { "FIELD": { "top_left": { "lat": 31.1, "lon": 121.5 }, "bottom_right": { "lat": 30.9, "lon": 121.7 } } } } }
2)geo_distance查询:查询到指定中心点小于某个距离值的所有文档。
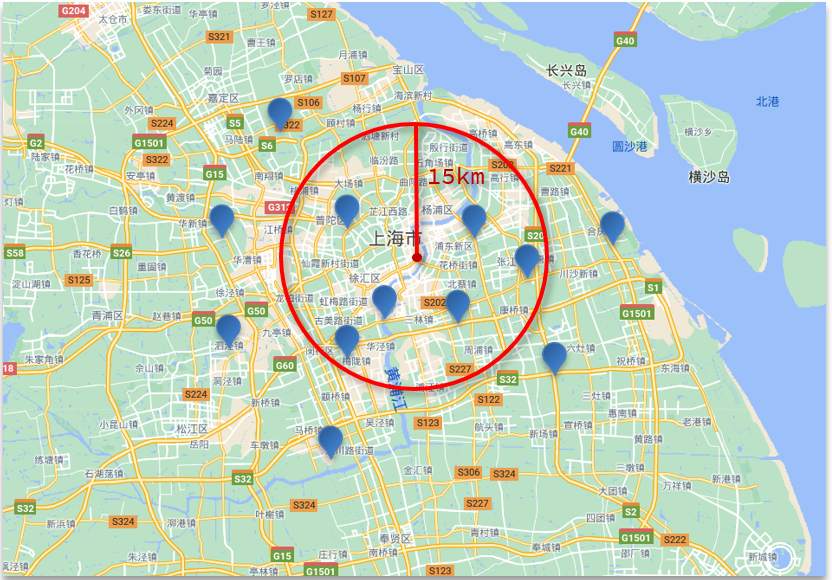
语法如下:
# geo_distance 查询 GET /indexName/_search { "query": { "geo_distance": { "distance": "15km", "FIELD": "31.21,121.5" } } }
7、复合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑,例如:
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名。
例如百度竞价,人工干预排名,掏钱的就可以往前排:

8、相关性算分
Elasticsearch中的相关性打分算法:
- TF-IDF:在Elasticsearch5.0之前,会随着词频增加而越来越大。
- BM25:在Elasticsearch5.0之后,会随着词频增加而增大,但增长曲线会趋于水平。

9、Function Score Query
使用 function score query,可以修改文档的相关性算分(query score),根据新得到的算分排序。
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-function-score-query.html
示例:
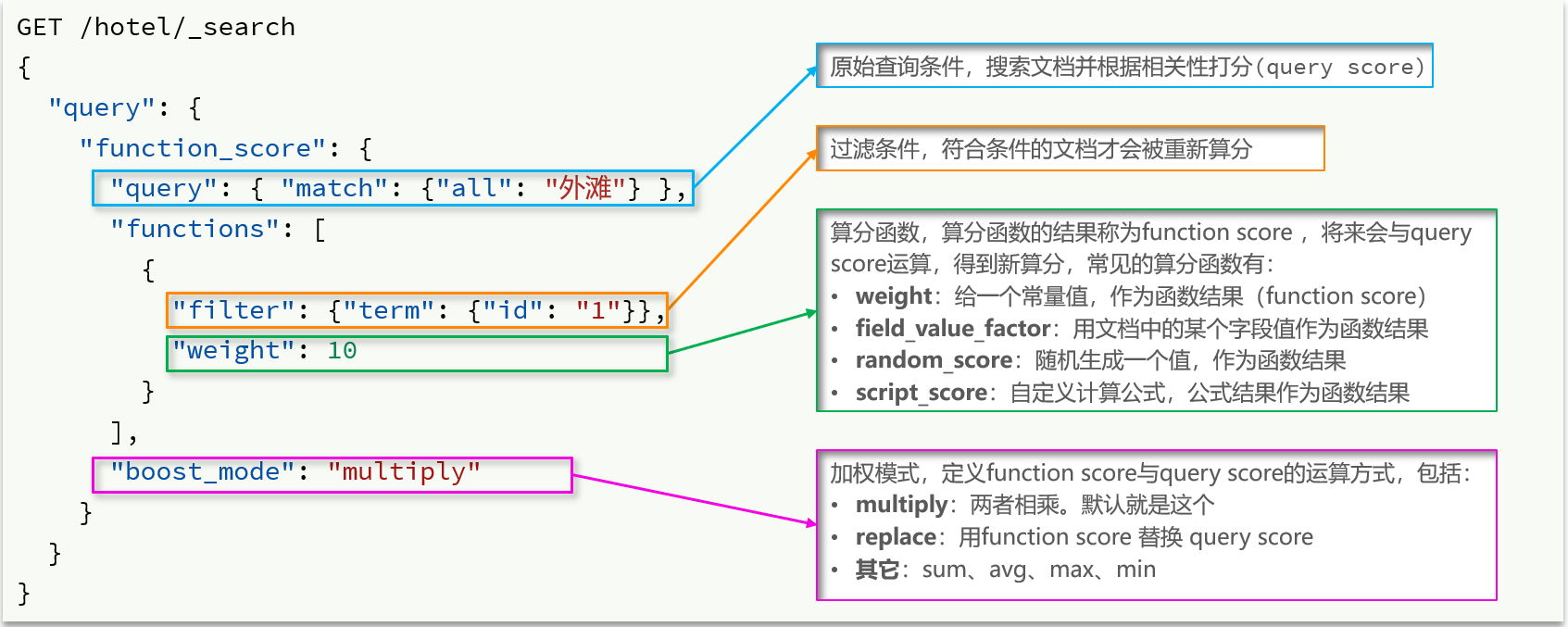
案例:给“如家”这个品牌的酒店排名靠前一些
把这个问题翻译一下,function score需要的三要素:
1)哪些文档需要算分加权?
品牌为如家的酒店
2)算分函数是什么?
weight就可以
3)加权模式是什么?
求和
示例如下所示:
# function score query GET /hotel/_search { "query": { "function_score": { "query": { // 原始查询条件 "match": { "all": "外滩" } }, "functions": [ // 算分函数 { "filter": { // 满足的条件,品牌必须是如家 "term": { "brand": "如家" } }, "weight": 10 // 算分权重为10 } ], "boost_mode": "sum" // 加权模式 } } }
10、Boolean Query
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”,参与算分。
- should:选择性匹配子查询,类似“或”,参与算分。
- must_not:必须不匹配的条件,类似“非”,不参与算分。
- filter:必须匹配每个子查询,类似“与”,不参与算分。
相关性打分算法是比较复杂的,因此每做一次算分其实是会消耗一些资源的,所以不参与算分比参与算分的性能要更好些。
虽然 filter 和 must 都表示“与”的意思,但是跟 must 不一样的是,filter 不参与算分,并且可以使用缓存,因此 filter 比 must 查询性能更高。
由此可见,将来在做搜索时,除了跟算分相关的(例如:关键字搜索)要使用 must 或 should 以外,其它的都应该尽量使用 must_not 或者 filter 来查询,尽可能的减少算分,提高查询效率。
语法示例如下:
GET /hotel/_search { "query": { "bool": { "must": [ {"term": {"city": "上海" }} ], "should": [ {"term": {"brand": "皇冠假日" }}, {"term": {"brand": "华美达" }} ], "must_not": [ { "range": { "price": { "lte": 500 } }} ], "filter": [ { "range": {"score": { "gte": 45 } }} ] } } }
案例:利用bool查询实现功能

需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
GET /hotel/_search { "query": { "bool": { "must": [ { "match": { "name": "如家" } } ], "must_not": [ { "range": { "price": { "gt": 400 } } } ], "filter": [ { "geo_distance": { "distance": "10km", "location": { "lat": 31.21, "lon": 121.5 } } } ] } } }
11、搜索结果处理-排序
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/sort-search-results.html
Elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
ES是允许你自己指定排序字段的,你一旦自己指定了排序字段,那么ES就会放弃打分,这样一来查询的效率也会有一定的提升。
排序语法示例如下:
第一种:适用于keyword类型、数值类型、日期类型等。
GET /indexName/_search { "query": { "match_all": {} }, "sort": [ { "FIELD": "desc" // 排序字段和排序方式ASC、DESC } ] }
第二种:适用于地理坐标类型。
GET /indexName/_search { "query": { "match_all": {} }, "sort": [ { "_geo_distance" : { "FIELD" : "纬度,经度", "order" : "asc", "unit" : "km" } } ] }
案例1:对酒店数据按照用户评价降序排序,评价相同的按照价格升序排序。
评价分是score字段,价格是price字段,按照顺序添加两个排序规则即可。

示例:
# sort排序 GET /hotel/_search { "query": { "match_all": {} }, "sort": [ { "score": "desc" }, { "price": "asc" } ] }
案例2:实现对酒店数据按照到你的位置坐标的距离升序排序。
获取经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/

示例:
# 找到 (121.612282,31.034661) 周围的酒店,距离升序排列 GET /hotel/_search { "query": { "match_all": {} }, "sort": [ { "_geo_distance": { "location": { "lat": 31.034661, "lon": 121.612282 }, "order": "asc", "unit": "km" } } ] }
运行结果如下所示:
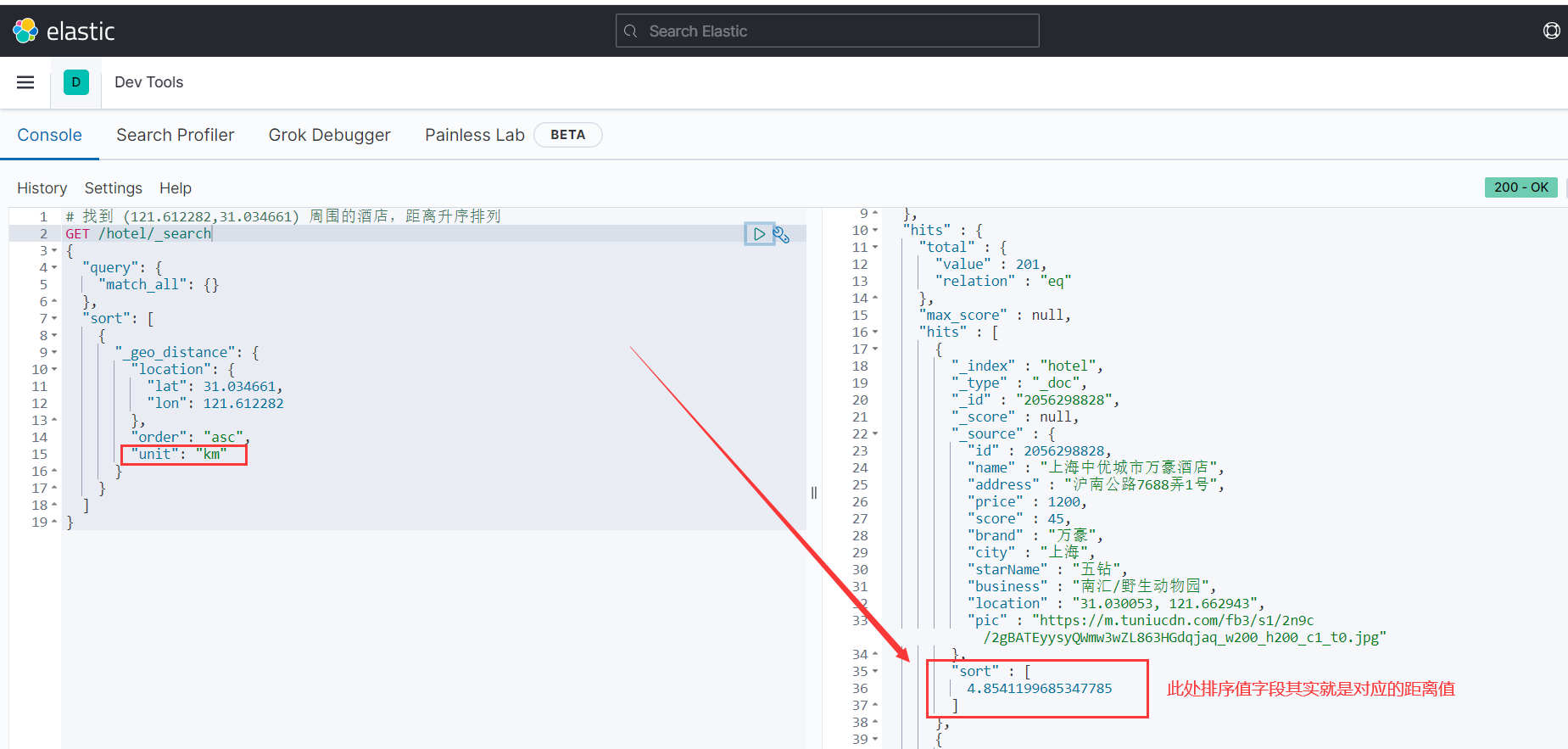
此处,搜索结果中sort字段的值,其实就是指到搜索点的距离值,其单位就是示例中设置的km。
12、搜索结果处理-分页
Elasticsearch默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
Elasticsearch中通过修改from、size参数来控制要返回的分页结果。
返回的分页结果集为:[from,from+size)
示例:
# 分页查询 GET /hotel/_search { "query": { "match_all": {} }, "from": 100, //分页开始的位置,默认为0 "size": 10, //期望获取的文档总数 "sort": [ { "price": "asc" } ] }
由于ES底层采用的是倒排索引,它的结构其实是不利于做分页的,所以呢它其实采用的是一种逻辑上的分页。
例如:你要查询 [990,1000) 这10条数据,对于ES来讲,它只能是先查出 [0,1000) 所有的数据,然后去截取 [990,1000) 这部分的数据。

13、搜索结果处理-深度分页问题
ES是分布式的,所以会面临深度分页问题。例如按price排序后,获取from=990,size=10的数据:

1)首先在每个数据分片上都排序并查询前1000条文档。
2)然后将所有节点的结果聚合,在内存中重新排序选出前1000条文档。
3)最后从这1000条中,选取从990开始的10条文档。
如果搜索页数过深,或者结果集(from + size)越大,对内存和CPU的消耗也就越高。因此ES设定结果集查询的上限是10000。

事实上,一般情况下我们会从业务层面上禁止它查超过10000条数据,例如:百度、京东、淘宝它们的搜索分页也都是有限制的。
14、搜索结果处理-深度分页解决方案
针对深度分页,ES提供了两种解决方案,官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
3种分页方式总结:
1)from + size
- 优点:支持随机翻页。
- 缺点:深度分页问题,默认查询上限(from + size)是10000。
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索。
2)after search
- 优点:没有查询上限(单次查询的size不超过10000)。
- 缺点:只能向后逐页查询,不支持随机翻页。
- 场景:没有随机翻页需求的搜索,例如手机向下滚动翻页。
3)scroll
- 优点:没有查询上限(单次查询的size不超过10000)。
- 缺点:会有额外内存消耗,并且搜索结果是非实时的。
- 场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search 方案。
15、搜索结果处理-高亮
高亮:就是在搜索结果中把搜索关键字突出显示。
原理是这样的:
- 将搜索结果中的关键字用标签标记出来
- 在页面中给标签添加css样式
语法如下:
GET /hotel/_search { "query": { "match": { "FIELD": "TEXT" } }, "highlight": { "fields": { // 指定要高亮的字段 "FIELD": { "pre_tags": "<em>", // 用来标记高亮字段的前置标签 "post_tags": "</em>" // 用来标记高亮字段的后置标签 } } } }
示例:
# 高亮查询,默认情况下ES搜索字段必须与高亮字段一致,不一致时需要将require_field_match设置为false GET /hotel/_search { "query": { "match": { "all": "如家" } }, "highlight": { "fields": { "name": { "require_field_match": "false", "pre_tags": "<font>", "post_tags": "</font>" } } } }
运行结果如下所示:

其中 pre_tags 前置标签默认值为 <em> ,post_tags 后置标签默认值为 </em> 。需要特别注意的是,设置时 pre_tags 和 post_tags 需要一起设置,否则的话会提示错误。
高亮查询,默认情况下ES搜索字段必须与高亮字段一致,不一致时需要将 require_field_match 设置为 false 。
16、搜索结果处理-整体语法
搜索结果处理整体语法如下所示:
# 整体语法 GET /hotel/_search { "query": { "match": { "all": "如家" } }, "from": 0, //分页开始的位置 "size": 20, //期望获取的文档总数 "sort": [ { "price": "asc" //普通排序 }, { "_geo_distance": { //距离排序 "location": "31.040699,121.618075", "order": "asc", "unit": "km" } } ], "highlight": { "fields": { //高亮字段 "name": { "require_field_match": "false", "pre_tags": "<em>", //用来标记高亮字段的前置标签 "post_tags": "</em>" //用来标记高亮字段的后置标签 } } } }
至此本文就全部介绍完了,如果觉得对您有所启发请记得点个赞哦!!!
Demo中用到的酒店数据:
链接:https://pan.baidu.com/s/14y7wl11RkgeIjXJU-IPutA 提取码:qnpb
此文由博主精心撰写转载请保留此原文链接:https://www.cnblogs.com/xyh9039/p/17845050.html
版权声明:如有雷同纯属巧合,如有侵权请及时联系本人修改,谢谢!!!




