- A+
所属分类:linux技术
一:创建maven项目
导入maven
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper --> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.6</version> </dependency> <!-- https://mvnrepository.com/artifact/junit/junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> </dependency> </dependencies>
junit是测试块的包
其他三个是hdfs连接需要的包
二:winuti处理(如果有就不需要处理)
1.解压hadoop-2.6.1到D盘
2.配置环境变量
配置变量的(https://jingyan.baidu.com/article/47a29f24610740c0142399ea.html)
二:相关操作
1:目录操作
相关操作:1:mkdirs 创建目录。
2:delete 删除文件或目录。
3:listStatus 列出目录的内容。
4:getFileStatus 显示文件系统的目录和文件的元数据信息。
5:getFileBlockLocations 显示文件存储位置
(1:创建一个目录
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class Test1 { FileSystem fs; @Before public void conn() throws URISyntaxException, IOException { //hadoop配置文件,自动获取hadoop的hdfs配置文件 Configuration conf = new Configuration(); conf.set("dfs.replication", "1");//设置副本数为一 //创建url 9000是端口号配置文件中有,master是主机名,如果没有配置映射可以是ip地址 URI uri = new URI("hdfs://master:9000"); //等同于客户端 fs = FileSystem.get(uri, conf); } @Test public void mkdir() throws IOException { //创建一个Path对象传入想要创建hdfs的路径 Path path = new Path("/data1"); //判断是否存在要是存在就删除,以免报错 if(fs.exists(path)){ fs.delete(path); } //创建目录 fs.mkdirs(path); } }
可以通过web界面查看有没有创建成功(master:50070)
(2:获取获取文件列表
@Test public void filestatus() throws IOException { //获取根目录下的文件列表 FileStatus[] fileStatuses = fs.listStatus(new Path("/")); //遍历 fileStatuses for (FileStatus fileStatus : fileStatuses) { System.out.println(fileStatus); }
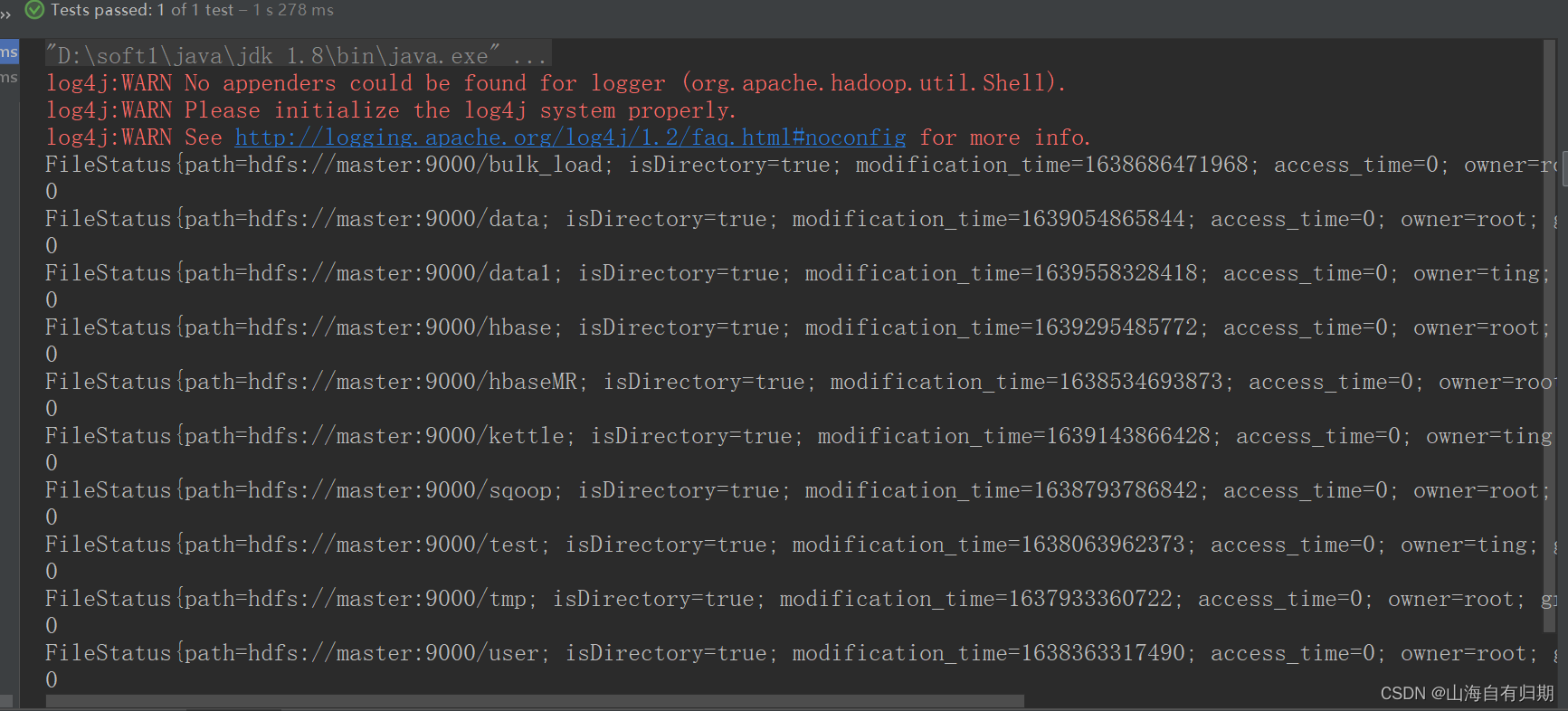
三:关于测试包
我用的junit测试,可以不用main方法需要运行哪个就运行哪个,每个@Test前面都有一个运行的一个@Test对应一个方法(函数),还有@Before,@After等。@Before是运行每个@Test之前都会运行,常用来做连接。@After相反是运行每个@Test之后都会运行常用在关闭连接的方法前面。
(原文链接:https://blog.csdn.net/weixin_50691399/article/details/121955946)
四:连接不上的问题
1.删除tmp
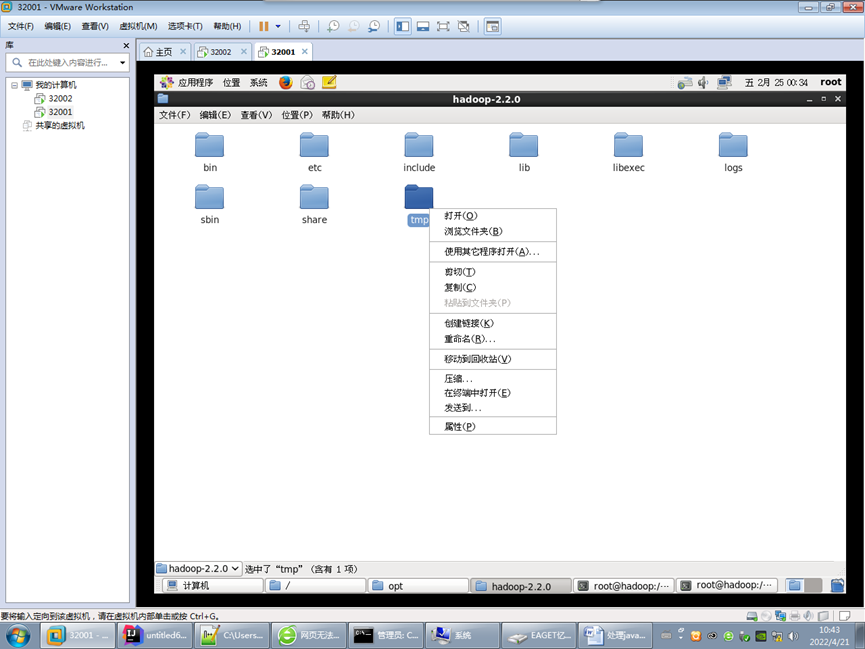
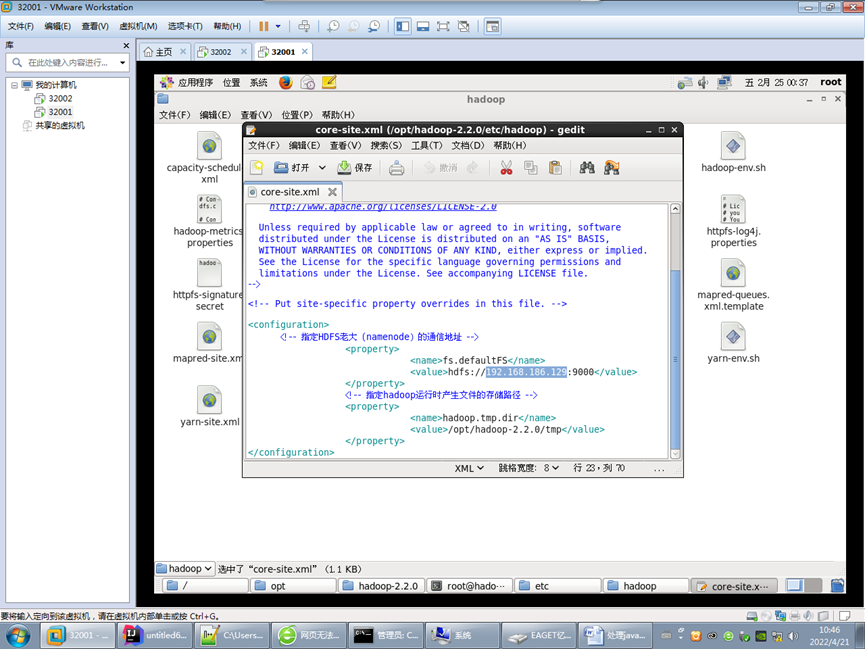
2.修改配置
修改namenode的地址为具体IP (之前写的localhost)
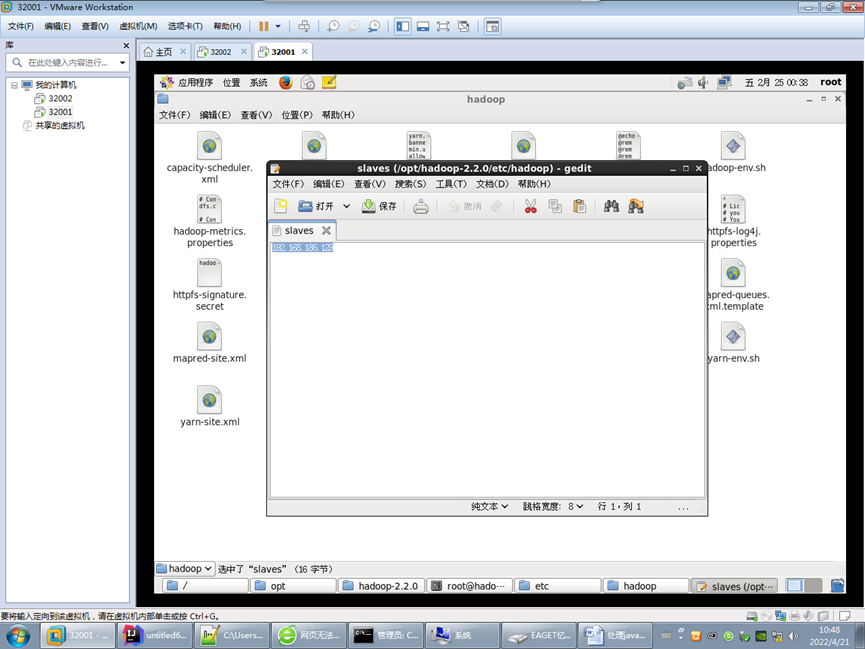
修改slaves文件,为具体IP
3. 格式化hdfs
hadoop namenode –format
4.启动HDFS
start-dfs.sh




