- A+
之前在《基于树状位压缩数组的字符集合》中介绍了一种利用位压缩数组来减少空间占用和提高集合操作效率的字符集合 CharSet。
实际测试下来,CharSet 的耗时只有 HashSet<char> 的 50%~80%,而集合操作的耗时更是只有 10%。旧文章里最后的测试结论有问题,应该是误使用 Debug 包来做性能测试导致的,最新的测试分别测试了下列五个场景的性能,并调整了测试的循环次数使得 HashSet<char> 耗时接近,便于对比:
- 单字符操作:包含 70%
Add调用和 30%Remove调用。 - 小范围操作:包含 70%
Add调用和 30%Remove调用,范围长度 1~10) - 大范围操作:包含 70%
Add调用和 30%Remove调用,范围长度 1~100) - 查找操作:
Contains调用。 - 集合操作:
UnionWith、ExceptWith,SymmetricExceptWith和IntersectWith调用。
结果如图 1 所示:
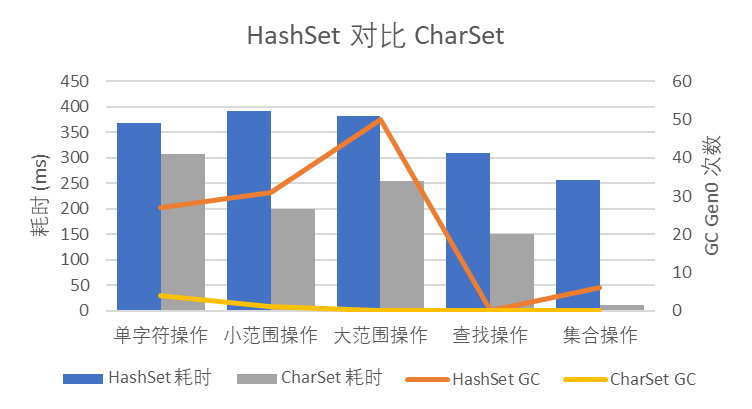
图 1 HashSet 对比 CharSet
可以看到,CharSet 的性能优于 HashSet<char>,特别是集合操作,位压缩数据可以批量进行集合操作,大大提高了性能。并且由于 CharSet 的内存消耗基本是固定的,GC 压力也远远小于 HashSet<char>。
但是在实际使用过程中,涉及 Unicode 范围的逻辑很少会对单个字符做操作,更多的是对字符范围做操作,之前在《判断字符宽度》中整理的宽字符范围就是一个很好的例子,这里用到了 45 个字符范围,大部分范围长度小于 10,但最大的一个字符范围达到了 22224 个字符。具体的字符范围统计情况可以参见下图。
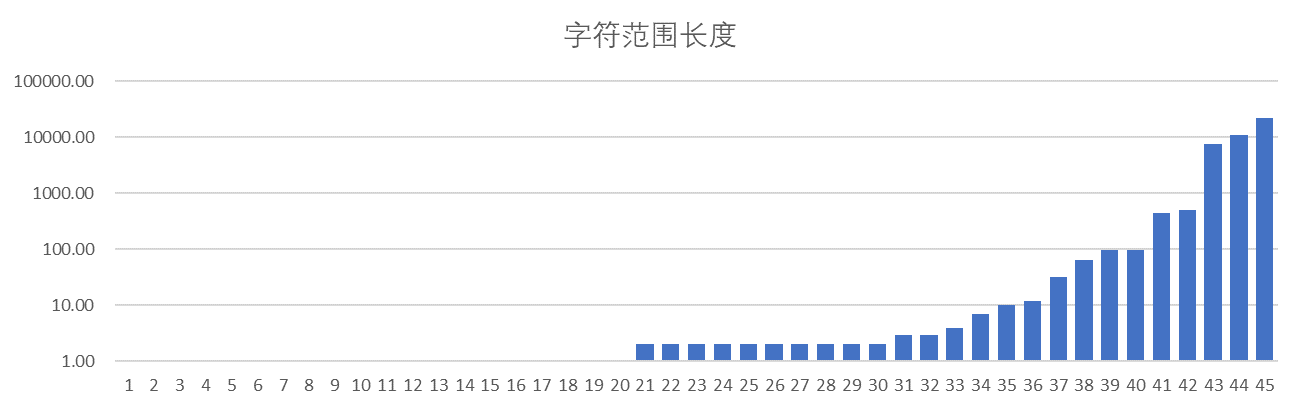
图 2 字符范围统计
对于这类大范围字符操作,虽然 CharSet 的效率还是比较高的,但与其他操作仍然处在在同一个水平。
基于平衡二叉树的字符集合
那么应该如何在范围操作这种常见场景下进行优化呢?一种想法是抛弃位压缩数组,直接将基于范围操作重新实现一套字符集合。这里选用了 AVL 树作为底层数据结构,与红黑树相比实现更为简单,性能也差别不大。
将字符范围的起始值作为 AVL 树的键,结束值作为相应节点的值,实现了一个 RangeCharSet。
但可惜的是,实测下来这样的实现性能并不高。如图 3 所示,RangeCharSet 的性能基本都明显差于 HashSet<char>,GC 压力也很高;只有作为优化目的的大范围操作性能明显极高,耗时只有 HashSet<char> 的 23%。
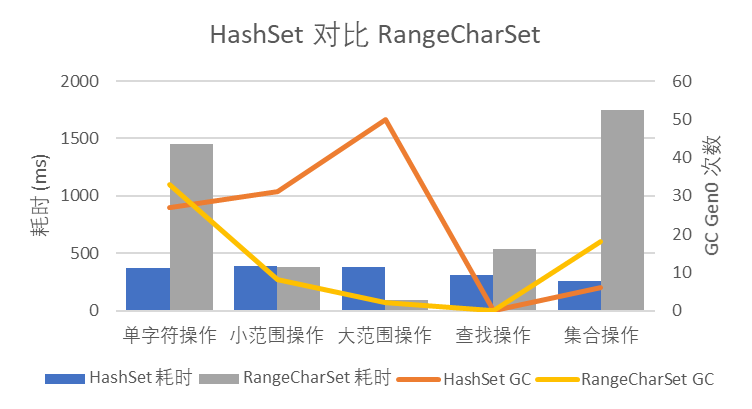
图 3 HashSet 对比 RangeCharSet
不过 RangeCharSet 的性能还是高于同样基于平衡二叉树的 SortedSet<char>,说明这里的瓶颈在于平衡二叉树,性能还是比不上哈希表的。
优化的基于树状位压缩数组的字符集合
第一条路走不通,只好再回来优化 CharSet 了。字符范围操作的性能不理想,原因在于需要对字符范围做遍历,越大的字符范围,这里的消耗就越大。
如何避免这里的遍历行为?可以同样利用位操作来进行批量操作。例如,需要将 x05 到 x32 范围内的所有位置置 1,可以直接通过 $(1 << 32) << 2 - (1 << 5)$ 计算出位掩码,再通过或操作实现置 1。
如果操作涉及到了数组内的多个位置,也是同样的操作,这样字符的遍历次数可以减少到原先的 1/64(将 ulong 作为存储单位),即使是完整 char 范围的操作,也只需要 1024 次操作。
同时,之前允许将 CharSet 第二层数组设置为 null 来表示数组范围的所有位置都是 0,那么可以考虑通过将第二层数组设置为 [] 来表示数组范围的所有值都是 1,就可以快速处理一些长度大于 1024(第二层数组可以容纳的字符数)的连续的 0 或 1。这样最大循环次数可以进一步减少到不超过 100。
在应用以上两类优化后,CharSet 的判断逻辑更为复杂,单字符操作和查找操作性能都有下降;集合操作性能基本持平;范围操作性能得到了极大提升。
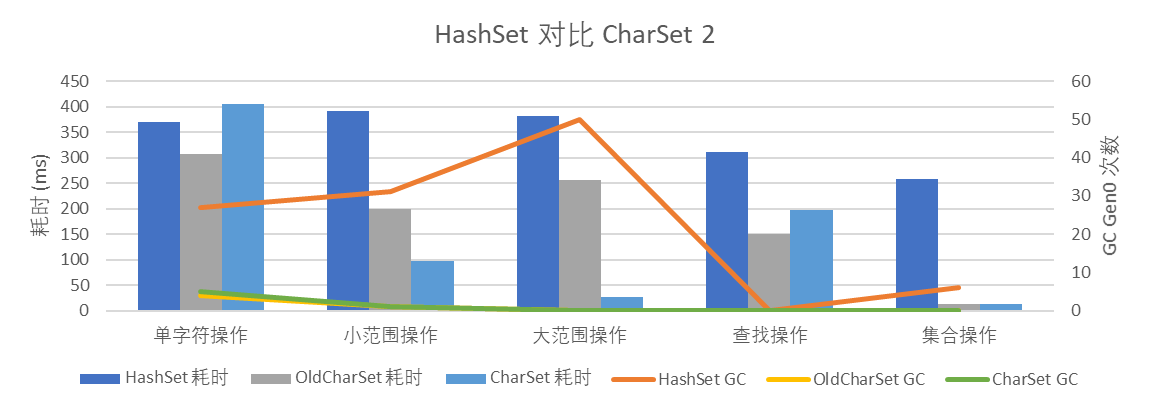
图 4 HashSet 对比 CharSet 2
新的 CharSet 减少了大范围连续 1 场景的内存消耗,也利用 ArrayPool 实现内存复用,整体对内存更为友好。
以前面提到的宽字符范围为例:
- 字符范围包含 42274 个字符,按
char[]存储需要 82.6KB。 CharSet只会包含 16 个底层数组,其他部分由于全为0或1而没有额外的内存消耗,总内存消耗约为 2.5KB。RangeCharSet包含 45 个 AVL 节点,总内存消耗约为 1.4KB。- 按只包含字符范围起止的
char[],需要 180B。这样的压缩表示下,二分查找进行匹配的性能略高于RangeCharSet,约为CharSet的 2.5 倍,只适合包含少量字符范围的简单的场景。
总的来说,CharSet 在提供高性能的同时并不需要消耗过多内存,可以完全取代任何用到 HashSet<char> 的场景。只有在极限优化内存的只读场景,才需要考虑是否使用只包含字符范围起止的 char[] 来代替。
CharSet 的所有代码可以在这里找到。




