- A+
功能介绍
Cuckoo是一个开源的自动恶意软件分析系统,我们可以用它来自动运行和分析文件,并可以获取到全面的分析结果,它可以获取以下类型结果:
-
追踪由恶意软件产生的所有进程执行的调用
-
恶意软件在执行过程中创建、删除和下载的文件
-
恶意软件进程的内存转储
-
PCAP包格式的网络流量跟踪
-
执行恶意软件时拍摄的屏幕截图
-
机器的全内存转储
cuckoo沙箱能够分析的文件类型
用户可以创建新的分析包(细节请参考docs/book/customization/packages.rst文件),也可以在提交样本时指定分析包,指令如下:
cuckoo submit --package<package name> /path/to/malware 想要详细了解 submit 命令的参数,可以参考docs/book/usage/submit.rst文件
已存在的分析包,即 package
applet :用于分析 Java applets
bin :用于分析一般的二进制数据,比如 shellcode
cpl :用于分析 控制面板 Applets
dll :用于运行和分析 动态链接库
doc :用于运行和分析 Microsoft Word文档
exe :默认分析包,用于分析通用的 W****indows 可执行文件
generic :用于运行和分析 generic samples 通过cmd.exe
ie :用于分析Internet Explorer在打开给定的url或html文件时的行为
jar :用于分析 Java JAR 包
js :用于运行和分析 Javascript 文件
hta :用于运行和分析 HTML 应用 文件
msi :用于运行和分析 MSI windows 安装包
pdf :用于运行和分析 PDF文档
ppt :用于运行和分析 Microsoft PPT 文档
ps1 :用于运行和分析 PowerShell 脚本
python :用于运行和分析 Python 脚本
vbs :用于运行和分析 VBScript 文件
wsf :用于运行和分析 Windows 脚本文件
xls :用于运行和分析 Microsoft Excel 文档
zip :用于运行和分析 Zip 压缩包
生成报告解析
分析完成后,多个文件被存储在专用目录中。所有分析都存储在$CWD/storage/analyses/子目录下,子目录以数据库中分析任务的ID命名,分析目录的结构如下:
analysis.log:这是分析器生成的日志文件,它包含了在客户机环境中分析执行情况的跟踪。它将报告进程、文件的创建以及执行过程中的终结错误。
dump.pcap:网络转储,由tcpdump或任何其他相应的网络嗅探器生成。
dump_sorted.pcap:dump.pcap的排序版本。从某种意义上说,它允许Web接口快速查找TCP流。
memory.dmp:如果启用了它,这个文件包含分析机器的全内存转储。
files/:这个目录包含了被恶意软件操作过的所有文件,并且cuckoo可以将它转储。
files.json:该文件包含一个json编码的条目,用于每个被删除的文件(例如, files/, shots/中的所有文件)。它包含可用的元信息,关于所有操作文件的进程,以及在客户机中的原始文件路径等。
logs/:这个目录包含Cuckoo进程监控生成的所有原始日志。
reports/:这个目录包含Cuckoo生成的所有报告,在 ../installation/host/configuration一章中详述。
shots/:这个目录包含了恶意文件执行过程中客户机桌面的所有屏幕截图。
tlsmaster.txt:文件包含了分析期间捕获的TLS主密钥。TLS 主密钥能被用于解密SSL/TLS通信流,继而用于解密HTTPS流。
执行流程介绍(处理分析结果部分)
cuckoo/core/scheduler.py模块
这个模块主要负责沙箱的调度工作。通过submit模块上传样本后,主要由AnalysisManager类负责执行任务,run()函数中主要做了两件事:
- 启动分析
通过launch_analysis()函数发起分析,启动分析的过程中需要启动auxiliary模块中的一系列辅助分析工具,(利用mitmdump,抓取数据辅助分析,包括包重放、重启分析等;利用tcpdump,对pcap包进行嗅探)。选定不同的包(package),也就是判断不同的文件类型,来启动样本文件。样本运行结束后通过socket连接,将运行信息回传给ResultServer,接下来就是处理分析结果
- 处理分析结果
对运行结果的分析是通过process_results()进入。该函数通过三个核心类完成分析处理:
-
- RunProcessing,执行处理过程。Cuckoo提供了Processing框架,通过Processing基类派生了很多处理模块,我们可以添加自己的分析模块,继承自Processing即可。每个模块可以对数据进行分析,并选择性的可以产生自己的分析结果,Cuckoo框架会拿到你的结果最终汇集到全局的处理结果字典
- RunSignatures,执行特征匹配。Cuckoo提供了特征匹配框架,通过Signature基类派生了很多特征匹配模块,我们同样可以添加自己的特征匹配模块,继承自Signature即可。特征匹配模块提供了丰富的外部调用接口,供Cuckoo框架本身回调。
-
- RunReporting,执行结果上报,经过上面两步的分析处理,最终得到的结果需要上报处理了。我们可以选择生成json到文件,也可以选择上传到ElasticSearch非关系型数据库,还可以有我们自定义的上报方式。Cuckoo提供了强大的框架接口供我们实现。
def process_results(self): """Process the analysis results and generate the enabled reports.""" logger( "Starting task reporting", action="task.report", status="pending" ) # TODO Refactor this function as currently "cuckoo process" has a 1:1 # copy of its code. TODO Also remove "archive" files. results = RunProcessing(task=self.task).run() RunSignatures(results=results).run() RunReporting(task=self.task, results=results).run() RunSignatures类
run() 函数是RunSignature类的入口,用来完成主要逻辑
def run(self): """Run signatures.""" # Allow signatures to initialize themselves. for signature in self.signatures: # 完成signture自定义的初始化 signature.init() # 输出运行的signature数量 log.debug("Running %d signatures", len(self.signatures)) # Iterate calls and tell interested signatures about them. # 获取从RunProcessing中返回的结果,传递给call_signature # 调用signature类中的on_process和on_signature函数, # 调用中如果产生异常就提示签名运行失败 for proc in self.results.get("behavior", {}).get("processes", []): # Yield the new process event. for sig in self.signatures: sig.pid = proc["pid"] self.call_signature(sig, sig.on_process, proc) self.yield_calls(proc) # Iterate through all Yara matches. self.process_yara_matches() # Iterate through all Extracted matches. self.process_extracted() __init__() 完成成员初始化,预构建一个签名列表
def __init__(self, results): self.results = results self.matched = [] # Initialize each applicable Signature. self.signatures = [] # 遍历available_signatures列表中每一个可用的signature for signature in self.available_signatures: # 获取signature的运行平台,如果是windows # (默认是windows)返回true,添加进signatures # 列表中。否则返回对应的平台 if self.should_enable_signature(signature): self.signatures.append(signature(self)) # Cache of signatures to call per API name. self.api_sigs = {} # Prebuild a list of signatures that *may* be interested self.call_always = set() self.call_for_api = {} self.call_for_cat = {} for sig in self.signatures: # Direct dispatch per API call for n in dir(sig): # 如果signature字符串以“on_call_”开头 if n.startswith("on_call_"): self.call_for_api.setdefault(n[8:], set()).add(sig) if not self._on_call_defined(sig): # 判断python版本,如果是puthon3可以简单检查 # Not implemented... continue init_once() 全局初始化类属性available_signatures以及ttps
@classmethod def init_once(cls): cls.available_signatures = [] # Gather all enabled & up-to-date Signatures. for signature in cuckoo.signatures: # 遍历cuckoo规则库,调用should_load_signature判断 # 根据signature的成员属性等信息判断是否应该加载这个类, # 成功则追加到signatures列表 if cls.should_load_signature(signature): cls.available_signatures.append(signature) # Sort Signatures by their order. cls.available_signatures.sort(key=lambda sig: sig.order) 个性化定制
cuckoo提供接口让用户定制处理模块、签名库以及生成报告等,可以完成一些个性化设置,下面将详细介绍各个部分
处理模块-Processing
cuckoo处理模块是python脚本,可以自定义方法来分析沙箱生成的原始结果,并且可以利用signatures和reporting模块追加一些信息到全局容器中。
你可以创建任何你想要的模块,只要他们遵循本章中介绍的预定义结构
Global Container
分析完成后,cuckoo将调用 cuckoo/processing 目录中所有可用的处理模块,要添加的模块必须放在这个目录中
每个模块还应该在 $CWD/conf/processing.conf 文件有一个专门的部分进行说明。例如,如果创建一个模块 cuckoo/processing/foorbar.py ,必须追加以下内容到上述文件中 [foobar] enabled=yes
然后每个模块将被初始化并执行,返回的数据将被追加到 一个我们称之为global container 的数据结构中。
这个容器只是一个大型Python 字典,它包括了所有模块产生的抽象结果,并按照他们的检索表进行分类。
Cuckoo当前可用的默认处理模块:
详见附件-《processing模块分析文档》
-
AnalysisInfo (
cuckoo/processing/analysisinfo.py) - 生成当前分析的一些基本信息,如时间戳,cuckoo版本等 -
ApkInfo (
cuckoo/processing/apkinfo.py) - 生成当前APK分析的一些基本信息(Android分析) -
Baseline (
cuckoo/processing/baseline.py) - 从收集的信息中获得基线结果 -
BehaviorAnalysis (
cuckoo/processing/behavior.py) - 解析原始行为日志并执行一些初始的转换和解释,包括完整的流程跟踪、行为总结和流程树 -
Buffer (
cuckoo/processing/buffer.py) - 缓冲区分析 -
Debug (
cuckoo/processing/debug.py) - 包含分析器生成的错误和analysis.log -
Droidmon (
cuckoo/processing/droidmon.py) - 从Droidmon日志中提取动态API调用信息 -
Dropped (
cuckoo/processing/dropped.py) -包含被恶意程序删除的和被cuckoo转储的文件信息 -
DumpTls (
cuckoo/processing/dumptls.py) - 交叉引用从监视器提取的TLS主密钥和从PCAP提取的密钥信息来转储主密钥文件 -
GooglePlay (
cuckoo/processing/googleplay.py) - 分析会话中的Google Play信息 -
Irma (
cuckoo/processing/irma.py) - IRMA连接器 -
Memory (
cuckoo/processing/memory.py) - 在全内存转储上执行volatile -
Misp (
cuckoo/processing/misp.py) - MISP连接器 -
NetworkAnalysis (
cuckoo/processing/network.py) - 解析PCAP文件并提取一些网络信息,如DNS流量,域,IPs, HTTP请求,IRC和SMTP流量 -
ProcMemory (
cuckoo/processing/procmemory.py) - 对进程内存转储进行分析。注意:该模块能够处理data/ Yara /memory/index_memory.yar中用户定义的Yara规则。只需编辑此文件,添加您的Yara规则 -
ProcMon (
cuckoo/processing/procmon.py) - 从procmon.exe的输出中提取事件 -
Screenshots (
cuckoo/processing/screenshots.py) - 屏幕截图和OCR分析 -
Snort (
cuckoo/processing/snort.py) - Snort 处理模块 -
StaticAnalysis (
cuckoo/processing/static.py) - 对PE32文件执行一些静态分析 -
Strings (
cuckoo/processing/strings.py) - 从分析的二进制文件中提取字符串 -
Suricata (
cuckoo/processing/suricata.py) - Suricata 处理模块 -
TargetInfo (
cuckoo/processing/targetinfo.py) - 包含有关分析文件的信息,如Hash值 -
VirusTotal (
cuckoo/processing/virustotal.py) - 通过VirusTotal.com搜索分析文件的反病毒签名。注意:文件没有上传到VirusTotal.com上,如果文件之前没有上传到网站上,结果将不会被检索。
为了使cuckoo能够使用这些分析模块,他们必须放在 cuckoo/processing/ 目录下。处理模块示例:
from cuckoo.common.abstracts import Processing class MyModule(Processing): def run(self): self.key = "key" data = do_something() return data 每一个处理模块应该包含:
-
一个继承自
Processing的类 -
一个
run()函数 -
一个self.key的属性,定义用于返回数据的子容器的名字
-
一个被附加到全局容器中的数据集合(list,dictionary,string等等)
你也可以指定一个
order值,他允许你按顺序运行可用的处理模块,默认所有处理模块的order值都为1,并且按照字母顺序执行。如果你想要改变这个值,你的模块应该是这样:
from cuckoo.common.abstracts import Processing class MyModule(Processing): order = 2 def run(self): self.key = "key" data = do_something() return data 你也可以通过设置 enabled 属性为 False 来禁用一个处理模块:
from cuckoo.common.abstracts import Processing class MyModule(Processing): enabled = False def run(self): self.key = "key" data = do_something() return data 处理模块提供了一些属性,用于访问给定分析的原始结果
-
self.analysis_path: 结果文件夹路径(e.g.,$CWD/storage/analysis/1) -
self.log_path: analysis.log 文件路径 -
self.file_path: 分析文件的路径 -
self.dropped_path: 包含被删除文件的文件夹路径 -
self.logs_path: 包含原始行为日志的文件夹路径。 -
self.shots_path: 截屏文件夹路径 -
self.pcap_path: 网络pcap转储的路径。 -
self.memory_path: 全内存转储的路径(如果创建的话)。 -
self.pmemory_path: 进程内存转储的路径(如果创建的话)。通过这些属性,你可以轻松地访问cuckoo存储的所有原始结果,并对它们执行分析操作。最后要注意的是,当你遇到想要报告给cuckoo的问题时,建议使用
CuckooProcessingError异常模块,可以通过导入类来实现:
from cuckoo.common.exceptions import CuckooProcessingError from cuckoo.common.abstracts import Processing class MyModule(Processing): def run(self): self.key = "key" try: data = do_something() except SomethingFailed: raise CuckooProcessingError("Failed") return data 签名库-Signature
使用 Cuckoo,可以创建一些自定义签名,可以针对分析结果运行这些signatures,以便识别一些可能代表特定恶意行为或您感兴趣的指标的预定义模式。
可以将 Cuckoo 的signatures用于以下用途的一些示例:
-
通过隔离一些独特的行为(如文件名或互斥锁)来识别特定恶意软件系列。
-
发现恶意软件对系统执行的有趣修改,例如安装设备驱动程序。
-
通过隔离那些通常执行的典型操作来识别特定的恶意软件类别,例如银行木马或勒索软件。
-
将样本分类为恶意软件/未知类别(无法识别干净的样本)
首先,所有签名必须位于 Cuckoo 中的 cuckoo/cuckoo/signatures/。以下是一个基本的示例签名:
from cuckoo.common.abstracts import Signature class CreatesExe(Signature): name = "creates_exe" description = "Creates a Windows executable on the filesystem" severity = 2 categories = ["generic"] authors = ["Cuckoo Developers"] minimum = "2.0" def on_complete(self): return self.check_file(pattern=".*\.exe$", regex=True) 在这个例子中,我们只是遍历摘要中所有访问过的文件并检查是否有任何以“.exe”结尾的文件:在这种情况下,它将返回True,表示签名匹配,否则返回False。
如果签名匹配,“signatures”部分中的一个新条目将被添加到全局容器中,大致如下:
"signatures": [ { "severity": 2, "description": "Creates a Windows executable on the filesystem", "alert": false, "references": [], "data": [ { "file_name": "C:\d.exe" } ], "name": "creates_exe" } ] 创建signatures:
首先要做的是导入依赖项,创建一个框架并定义一些初始属性。以下当前可以设置的:
* name:签名的标识符。
* description:对签名所代表的内容的简要描述。
* severity:标识匹配事件严重性的数字(通常在 1 到 3 之间)。
* categories:描述匹配事件类型的类别列表(例如“banker”、“injection”或“anti-vm”)。
* families:恶意软件家族名称列表,以防签名与已知的特定匹配。
* authors:签名的作者名单。
* references:为签名提供上下文的参考(URL)列表。
* enable:如果设置为 False,签名将被跳过。
* alert:如果设置为 True 可用于指定应报告签名(可能由专用报告模块)。
* minimum:成功运行此签名所需的最低 Cuckoo 版本。
* maximum:成功运行此签名所需的最大 Cuckoo 版本。
from cuckoo.common.abstracts import Signature class BadBadMalware(Signature): name = "badbadmalware" description = "Creates a mutex known to be associated with Win32.BadBadMalware" severity = 3 categories = ["trojan"] families = ["badbadmalware"] authors = ["Me"] minimum = "2.0" def on_complete(self): return 现在我们的签名将返回 True,无论是否观察到分析的恶意软件打开了指定的互斥锁。如果想直接访问全局容器,可以通过以下方式翻译之前的签名:
from cuckoo.common.abstracts import Signature class BadBadMalware(Signature): name = "badbadmalware" description = "Creates a mutex known to be associated with Win32.BadBadMalware" severity = 3 categories = ["trojan"] families = ["badbadmalware"] authors = ["Me"] minimum = "2.0" def on_complete(self): for process in self.get_processes_by_pid(): if "summary" in process and "mutexes" in process["summary"]: for mutex in process["summary"]["mutexes"]: if mutex == "i_am_a_malware": return True return False Evented Signatures
从 1.0 版本开始,Cuckoo 提供了一种编写更高性能签名的方法。 过去,每个签名都需要遍历分析期间收集的整个 API 调用集合。 当此类集合很大时,这会不必要地导致性能问题。
由于 1.2 Cuckoo 只支持所谓的“事件签名”。 基于 run 函数的旧签名可以移植到使用 on_complete。 主要区别在于,使用这种新格式时,所有签名将并行执行,并且将通过 API 调用集合在一个循环内为每个签名调用一个名为 on_call() 的回调函数。
from cuckoo.common.abstracts import Signature class SystemMetrics(Signature): name = "generic_metrics" description = "Uses GetSystemMetrics" severity = 2 categories = ["generic"] authors = ["Cuckoo Developers"] minimum = "2.0" # 从 1.0 版本开始,Cuckoo 提供了一种编写更高性能签名的方法。 # 过去,每个签名都需要遍历分析期间收集的整个 API 调用集合。 # 当此类集合很大时,这会不必要地导致性能问题。 filter_processnames = set() filter_apinames = set(["GetSystemMetrics"]) filter_categories = set() # 这是签名模板。 它应该用作创建自定义签名的框架,因此默认情况下是禁用的。 # on_call 函数用于“事件”签名。这些使用更有效的方式处理记录的 API 调用。 enabled = False def on_complete(self): # 在 on_complete 方法中,您可以实现任何清理代码并最后一次决定此签名是否匹配。 # 如果匹配,则返回 True。 return False # RunSignatures 插件中的循环将为每个记录的 API 调用调用此方法。 # 返回值决定了这个签名的“状态”。True 表示签名匹配,False 这次没有。 # 使用 self.deactivate() 停止 API 调用中的流式传输。 def on_call(self, call, pid, tid): # 实际上不需要此检查,因为我们已经使用了上面的 filter_apinames。 if call["api"] == "GetSystemMetrics": # Signature 匹配成功, 返回 True. return True return None 将编写好的规则放在规则库对应的位置,上传样本即可,匹配成功后在log中会输出想要的结果。
报告-Reporting
在原始分析结果被处理模块加工和提取完成,并且生成全局容器之后,它会被cuckoo传递给所有可用的报告模块,使它能以不同的方式被访问和使用
所有的报告模块必须被放在 cuckoo/cuckoo/reporting 目录下(被翻译为 cuckoo.reporting 模块)
每个模块还应该在 $CWD/conf/reporting.conf 文件有一个专门的部分进行说明。例如,如果创建一个模块 cuckoo/processing/foorbar.py ,必须追加以下内容到上述文件中 [foobar] enabled=on
你添加的每一个选项都可以在你的报告模块 self.oprions 字典中使用。
以下是一个json报告的示例:
import os import json import codecs from cuckoo.common.abstracts import Report from cuckoo.common.exceptions import CuckooReportError class JsonDump(Report): """Saves analysis results in JSON format.""" def run(self, results): """Writes report. @param results: Cuckoo results dict. @raise CuckooReportError: if fails to write report. """ try: report = codecs.open(os.path.join(self.reports_path, "report.json"), "w", "utf-8") json.dump(results, report, sort_keys=False, indent=4) report.close() except (UnicodeError, TypeError, IOError) as e: raise CuckooReportError("Failed to generate JSON report: %s" % e) 这段代码非常简单,它接受由处理模块产生的全局容器,将其转换为json并写入文件
编写有效的报告模块有几个要求:
-
声明你的类继承自
Report -
使用
run()函数执行主要操作 -
尝试捕获大部分异常并抛出
CuckooReportError来通知这个问题所有报告模块都可以访问这些属性:
-
self.analysis_path: 存放原始分析结果的文件夹路径(例如:storage/analyses/1/) -
self.reports_path: 报告的存放路径(例如:storage/analyses/1/reports/) -
self.options:一个字典,包含在conf/reporting.conf中的报表配置节中指定的所有选项。
帮助文档
cuckoo搭建时遇到的问题:
-
pip版本升级过高:在Ubuntu中对python的操作容易导致系统本身产生问题。
解决办法:当需要升级pip时,手动更新到指定版本,不要自动更新到最高版本 -
报错客户机未创建
解决办法:cuckoo安装全程使用同一个账户进行。参考:https://blog.csdn.net/wojiushiwo945you/article/details/112261641 -
虚拟机无法连接外网
解决办法:虚拟机配置网络时要写原来的网关 -
沙箱启动失败:报错无法找到libyara.so文件。
解决办法:不安装yara模块,暂时解决 -
沙箱未加载规则库
解决办法:执行cuckoo community指令从社区下载规则库,注意cuckoo的活动目录和源码目录不是同一个,规则库被下载在活动目录中,也就是.cuckoo的文件夹下 -
沙箱未启动动态分析:样本文件没有来得及运行,报错排版问题。
暂未解决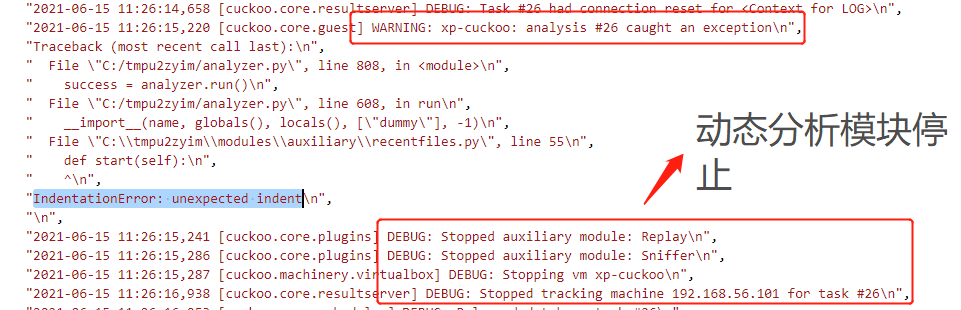
-
tcpdump模块有问题:报错无法停止sniifer模块,不太影响沙箱运行,但会导致沙箱分析结果不太完整。
暂未解决猜测是root权限的原因
解决tcpdump的权限被拒绝 sudo yum -C install apparmor-utils sudo aa-disable /usr/sbin/tcpdump 打开.cuckoo/analyzer/windows/modules/auxiliary/recentfiles.py ''' r = SHELL32.SHGetKnownFolderPath( uuid.UUID(self.locations[location]).get_bytes_le(), 0, None, ctypes.byref(dirpath) ) if r: log.warning("Error obtaining user directory: 0x%08x", r) return # TODO We should free the memory with CoTaskMemFree(). return dirpath.value ''' 



