- A+
尊重原创版权: https://www.gewuweb.com/hot/10176.html
《嵌入式Linux内存使用与性能优化》笔记
尊重原创版权: https://www.gewuweb.com/sitemap.html

这本书有两个关切点:系统内存(用户层)和性能优化。
这本书和Brendan Gregg的《Systems
Performance》相比,无论是技术层次还是更高的理论都有较大差距。但是这不影响,快速花点时间简单过一遍。
然后在对《Systems Performance》进行详细的学习。
由于Ubuntu测试验证更合适,所以在Ubuntu(16.04)+Kernel(4.10.0)环境下做了下面的实验。
全书共9章:14章着重于内存的使用,尽量降低进程的内存使用量,定位和发现内存泄露;59章着重于如何让系统性能优化,提高执行速度。
第1章 内存的测量
第2章 进程内存优化
第3章 系统内存优化
第4章 内存泄露
第5章 性能优化的流程
第6章 进程启动速度
第7章 性能优化的方法
第8章 代码优化的境界
第9章 系统性能优化
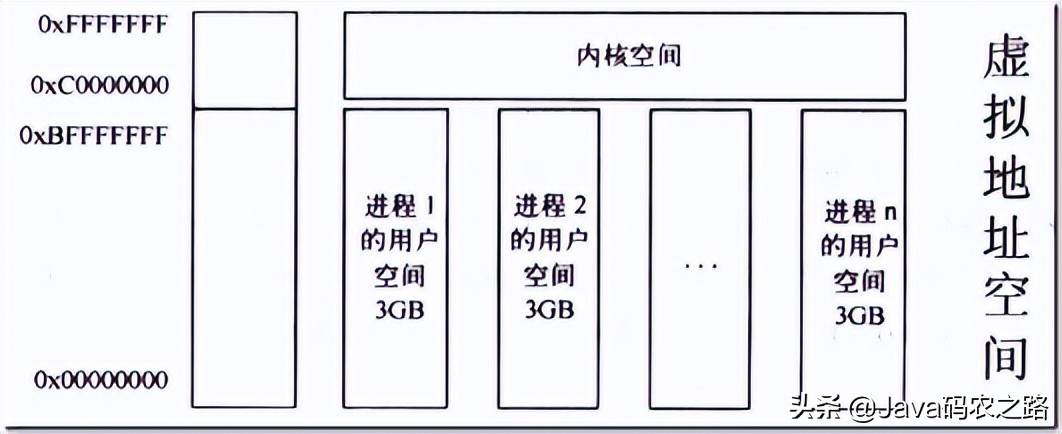
用户空间的内存使用量是由进程使用量累积和系统使用之和,所以优化系统内存使用,就是逐个攻克每个进程的使用量和优化系统内存使用。。
俗话说“知己知彼,百战不殆”,要优化一个进程的使用量,首先得使用工具去评估内存使用量( 第1章 内存的测量 );
然后就来看看进程那些部分耗费内存,并针对性进行优化( 第2章 进程内存优化 );
最后从系统层面寻找方法进行优化( 第3章 系统内存优化 )。
内存的使用一个致命点就是内存泄露,如何发现内存泄露,并且将内存泄露定位是重点( 第4章 内存泄露 )
第1章 内存的测量
关于系统内存使用,将按照 (1)明确目标 -> (2) 寻找评估方法, (3)了解当前状况->对系统内存进行优化->重新测量
,评估改善状况的过程,来阐述系统的内存使用与优化。(1)明确目标,针对系统内存优化,有两个:
A. 每个守护进程使用的内存尽可能少
B. 长时间运行后,守护进程内存仍然保持较低使用量,没有内存泄露 。
(2)寻找评估方法,第1章关注点。
(3)对系统内存进行优化,第2章针对进程进行优化,第3章针对系统层面进行内存优化,第4章关注内存泄露。
系统内存测量
free用以获得当前系统内存使用情况。
在一嵌入式设备获取如下:
busybox free
total used free shared buffers
Mem: 23940 15584 8356 0 0 (23940=15584+8356)
-/+ buffers: 15584 8356
Swap: 0 0 0
和PC使用的free对比:
total used free shared buffers cached
Mem: 14190636 10494128 3696508 587948 1906824 5608888
-/+ buffers/cache: 2978416 11212220
Swap: 7999484 68844 7930640
可见这两个命令存在差异,busybox没有cached。这和实际不符,实际可用内存=free+buffers+cached。
buffers是用来给Linux系统中块设备做缓冲区,cached用来缓冲打开的文件。下面是通过cat
/proc/meminfo获取,可知实际可用内存=8352+0+3508=11860。已经使用内存为=23940-11860=12080。可见两者存在差异,
busybox的free不太准确;/proc/meminfo的数据更准确。
MemTotal: 23940 kB
MemFree: 8352 kB
Buffers: 0 kB
Cached: 3508 kB
…
进程内存测量
在进程的proc中与内存有关的节点有statm、maps、memmap。
cat /proc/xxx/statm
1086 168 148 1 0 83 0
这些参数以页(4K)为单位,分别是:
1086 Size,任务虚拟地址空间的大小。
168 Resident,应用程序正在使用的物理内存的大小。
148 Shared,共享页数。
1 Trs,程序所拥有的可执行虚拟内存的大小。
0 Lrs,被映像到任务的虚拟内存空间的的库的大小。
83 Drs,程序数据段和用户态的栈的大小。
0 dt,脏页数量(已经修改的物理页面)。
Size、Trs、Lrs、Drs对应虚拟内存,Resident、Shared、dt对应物理内存。
cat /proc/xxx/maps
00400000-00401000 r-xp 00000000 08:05 18561374 /home/lubaoquan/temp/hello
00600000-00601000 r--p 00000000 08:05 18561374 /home/lubaoquan/temp/hello
00601000-00602000 rw-p 00001000 08:05 18561374 /home/lubaoquan/temp/hello
00673000-00694000 rw-p 00000000 00:00 0 [heap]
7f038c1a1000-7f038c35f000 r-xp 00000000 08:01 3682126 /lib/x86_64-linux-
gnu/libc-2.19.so
7f038c35f000-7f038c55e000 ---p 001be000 08:01 3682126 /lib/x86_64-linux-
gnu/libc-2.19.so
7f038c55e000-7f038c562000 r--p 001bd000 08:01 3682126 /lib/x86_64-linux-
gnu/libc-2.19.so
7f038c562000-7f038c564000 rw-p 001c1000 08:01 3682126 /lib/x86_64-linux-
gnu/libc-2.19.so
7f038c564000-7f038c569000 rw-p 00000000 00:00 0
7f038c569000-7f038c58c000 r-xp 00000000 08:01 3682489 /lib/x86_64-linux-
gnu/ld-2.19.so
7f038c762000-7f038c765000 rw-p 00000000 00:00 0
7f038c788000-7f038c78b000 rw-p 00000000 00:00 0
7f038c78b000-7f038c78c000 r--p 00022000 08:01 3682489 /lib/x86_64-linux-
gnu/ld-2.19.so
7f038c78c000-7f038c78d000 rw-p 00023000 08:01 3682489 /lib/x86_64-linux-
gnu/ld-2.19.so
7f038c78d000-7f038c78e000 rw-p 00000000 00:00 0
7ffefe189000-7ffefe1aa000 rw-p 00000000 00:00 0 [stack]
7ffefe1c4000-7ffefe1c6000 r--p 00000000 00:00 0 [vvar]
7ffefe1c6000-7ffefe1c8000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
第一列,代表该内存段的虚拟地址。
第二列,r-xp,代表该段内存的权限,r=读,w=写,x=执行,s=共享,p=私有。
第三列,代表在进程地址里的偏移量。
第四列,映射文件的的主从设备号。
第五列,映像文件的节点号。
第六列,映像文件的路径。
kswapd
Linux存在一个守护进程kswapd,他是Linux内存回收机制,会定期监察系统中空闲呢村的数量,一旦发现空闲内存数量小于一个阈值的时候,就会将若干页面换出。
但是在嵌入式Linux系统中,却没有交换分区。没有交换分区的原因是:
1.一旦使用了交换分区,系统系能将下降得很快,不可接受。
2.Flash的写次数是有限的,如果在Flash上面建立交换分区,必然导致对Flash的频繁读写,影响Flash寿命。
那没有交换分区,Linux是如何做内存回收的呢?
对于那些没有被改写的页面,这块内存不需要写到交换分区上,可以直接回收。
对于已经改写了的页面,只能保留在系统中,,没有交换分区,不能写到Flash上。
在Linux物理内存中,每个页面有一个dirty标志,如果被改写了,称之为dirty page。所有非dirty page都可以被回收。
第2章 进程内存优化
当存在很多守护进程,又要去降低守护进程内存占用量,如何去推动:
1.所有守护进程内存只能比上一个版本变少。
2.Dirty Page排前10的守护进程,努力去优化,dirty page减少20%。
可以从三个方面去优化:
1.执行文件所占用的内存
2.动态库对内存的影响
3.线程对内存的影响
2.1 执行文件
一个程序包括代码段、数据段、堆段和栈段。一个进程运行时,所占用的内存,可以分为如下几部分:
栈区(stack):由编译器自动分配释放,存放函数的参数、局部变量等
堆区(heap):一般由程序员分配释放,若程序员不释放,程序结束时可有操作系统来回收
全局变量、静态变量:初始化的全局变量和静态变量在一块区域,未初始化的全局变量和静态变量在另一块区域,程序结束后由系统释放
文字常量:常量、字符串就是放在这里的,程序结束后有系统释放
程序代码:存放函数体的二进制代码
下面结合一个实例分析:
include <stdlib.h>
include <stdio.h>
int n=10;
const int n1=20;
int m;
int main()
{
int s=7;
static int s1=30;
char *p=(char *)malloc(20);
pid_t pid=getpid();
printf("pid:%dn", pid);
printf("global variable address=%pn", &n);
printf("const global address=%pn", &n1);
printf("global uninitialization variable address=%pn", &m);;
printf("static variable address=%pn", &s1);
printf("stack variable address=%pn", &s);
printf("heap variable address=%pn", &p);
pause();
}
执行程序结果:
pid:18768
global variable address=0x601058
const global address=0x400768
global uninitialization variable address=0x601064
static variable address=0x60105c
stack variable address=0x7ffe1ff7d0e0
heap variable address=0x7ffe1ff7d0e8
查看cat /proc/17868/maps
00400000-00401000 r-xp 00000000 08:05 18561376 /home/lubaoquan/temp/example
(只读全局变量n1位于进程的代码段)
00600000-00601000 r--p 00000000 08:05 18561376 /home/lubaoquan/temp/example
00601000-00602000 rw-p 00001000 08:05 18561376 /home/lubaoquan/temp/example
(全局初始变量n、全局未初始变量m、局部静态变量s1,都位于进程的数据段)
00771000-00792000 rw-p 00000000 00:00 0 [heap]
7f7fb86a2000-7f7fb8860000 r-xp 00000000 08:01 3682126 /lib/x86_64-linux-
gnu/libc-2.19.so
7f7fb8860000-7f7fb8a5f000 ---p 001be000 08:01 3682126 /lib/x86_64-linux-
gnu/libc-2.19.so
7f7fb8a5f000-7f7fb8a63000 r--p 001bd000 08:01 3682126 /lib/x86_64-linux-
gnu/libc-2.19.so
7f7fb8a63000-7f7fb8a65000 rw-p 001c1000 08:01 3682126 /lib/x86_64-linux-
gnu/libc-2.19.so
7f7fb8a65000-7f7fb8a6a000 rw-p 00000000 00:00 0
7f7fb8a6a000-7f7fb8a8d000 r-xp 00000000 08:01 3682489 /lib/x86_64-linux-
gnu/ld-2.19.so
7f7fb8c63000-7f7fb8c66000 rw-p 00000000 00:00 0
7f7fb8c89000-7f7fb8c8c000 rw-p 00000000 00:00 0
7f7fb8c8c000-7f7fb8c8d000 r--p 00022000 08:01 3682489 /lib/x86_64-linux-
gnu/ld-2.19.so
7f7fb8c8d000-7f7fb8c8e000 rw-p 00023000 08:01 3682489 /lib/x86_64-linux-
gnu/ld-2.19.so
7f7fb8c8e000-7f7fb8c8f000 rw-p 00000000 00:00 0
7ffe1ff5f000-7ffe1ff80000 rw-p 00000000 00:00 0 [stack]
(局部变量s、malloc分配内存指针p都位于栈段)
7ffe1ffbb000-7ffe1ffbd000 r--p 00000000 00:00 0 [vvar]
7ffe1ffbd000-7ffe1ffbf000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
第3章 系统内存优化
3.1 守护进程的内存使用
守护进程由于上期运行,对系统内存使用影响很大:
1.由于一直存货,所以其占用的内存不会被释放。
2.即使什么都不做,由于引用动态库,也会占用大量的物理内存。
3.由于生存周期很长,哪怕一点内存泄露,累积下来也会很大,导致内存耗尽。
那么如何降低风险呢?
1.设计守护进程时,区分常驻部分和非常驻部分。尽量降低守护进程的逻辑,降低内存占用,降低内存泄露几率。或者将几个守护进程内容合为一个。
2.有些进程只是需要尽早启动,而不需要变成守护进程。可以考虑加快启动速度,从而使服务达到按需启动的需求。优化方式有优化加载动态库、使用Prelink方法、采用一些进程调度方法等。
3.2 tmpfs分区
Linux中为了加快文件读写,基于内存建立了一个文件系统,成为ramdisk或者tmpfs,文件访问都是基于物理内存的。
使用df -k /tmp可以查看分区所占空间大小:
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 77689292 9869612 63850172 14% /
在对这个分区进行读写时,要时刻注意,他是占用物理内存的。不需要的文件要及时删除。
3.3 Cache和Buffer
系统空闲内存=MemFree+Buffers+Cached。
Cache也称缓存,是把从Flash中读取的数据保存起来,若再次读取就不需要去读Flash了,直接从缓存中读取,从而提高读取文件速度。Cache缓存的数据会根据读取频率进行组织,并最频繁读取的内容放在最容易找到的位置,把不再读的内容不短往后排,直至从中删除。
在程序执行过程中,发现某些指令不在内存中,便会产生page fault,将代码载入到物理内存。程序退出后,代码段内存不会立即丢弃,二是作为Cache缓存。
Buffer也称缓存,是根据Flash读写设计的,把零散的写操作集中进行,减少Flash写的次数,从而提高系统性能。
Cache和BUffer区别简单的说都是RAM中的数据, Buffer是即将写入磁盘的,而Cache是从磁盘中读取的 。
使用free -m按M来显示Cache和Buffer大小:
total used free shared buffers cached
Mem: 13858 1204 12653 206 10 397
-/+ buffers/cache: 796 13061
Swap: 7811 0 7811
降低Cache和Buffer的方法:
sync
该命令将未写的系统缓冲区写到磁盘中。包含已修改的 i-node、已延迟的块 I/O 和读写映射文件。/proc/sys/vm/drop_caches
a)清理pagecache(页面缓存)echo 1 > /proc/sys/vm/drop_caches 或者 # sysctl -w vm.drop_caches=1
b)清理dentries(目录缓存)和inodes
echo 2 > /proc/sys/vm/drop_caches 或者 # sysctl -w vm.drop_caches=2
c)清理pagecache、dentries和inodes
echo 3 > /proc/sys/vm/drop_caches 或者 # sysctl -w vm.drop_caches=3
上面三种方式都是临时释放缓存的方法,要想永久释放缓存,需要在/etc/sysctl.conf文件中配置:vm.drop_caches=1/2/3,然后sysctl
-p生效即可!vfs_cache_pressure
vfs_cache_pressure=100
这个是默认值,内核会尝试重新声明dentries和inodes,并采用一种相对于页面缓存和交换缓存比较”合理”的比例。
减少vfs_cache_pressure的值,会导致内核倾向于保留dentry和inode缓存。
增加vfs_cache_pressure的值,(即超过100时),则会导致内核倾向于重新声明dentries和inodes
总之,vfs_cache_pressure的值:
小于100的值不会导致缓存的大量减少
超过100的值则会告诉内核你希望以高优先级来清理缓存。
3.4 内存回收
kswapd有两个阈值:pages_high和pages_low,当空闲内存数量低于pages_low时,kswapd进程就会扫描内存并且每次释放出32个free
pages,知道free page数量达到pages_high。
kswapd回收内存的原则?
1.如果物理页面不是dirty page,就将该物理页面回收。
代码段,只读不能被改写,所占内存都不是dirty page。数据段,可读写,所占内存可能是dirty
page,也可能不是。堆段,没有对应的映射文件,内容都是通过修改程序改写的,所占物理内存都是dirty
page。栈段和堆段一样,所占物理内存都是dirty page。共享内存,所占物理内存都是dirty page。就是说,这条规则主要面向 进程的代码段和未修改的数据段 。
2.如果物理页面已经修改并且可以备份回文件系统,就调用pdflush将内存中的内容和文件系统进行同步。pdflush写回磁盘,主要针对Buffers。
3.如果物理页面已经修改但是没有任何磁盘的备份,就将其写入swap分区。
kswapd再回首过程中还存在两个重要方法:LMR(Low on Memory Reclaiming)和OMK(Out of Memory Killer)。
由于kswapd不能提供足够空闲内存是,LMR将会起作用,每次释放1024个垃圾页知道内存分配成功。
当LMR不能快速释放内存的时候,OMK就开始起作用,OMK会采用一个选择算法来决定杀死某些进程。发送SIGKILL,就会立即释放内存。
3.5 /proc/sys/vm优化
此文件夹下面有很多接口控制内存操作行为,在进行系统级内存优化的时候需要仔细研究,适当调整。
block_dump
表示是否打开Block Debug模式,用于记录所有的读写及Dirty Block写回操作。0,表示禁用Block
Debug模式;1,表示开启Block Debug模式。dirty_background_ratio
表示脏数据达到系统整体内存的百分比,此时触发pdflush进程把脏数据写回磁盘。dirty_expires_centisecs
表示脏数据在内存中驻留时间超过该值,pdflush进程在下一次将把这些数据写回磁盘。缺省值3000,单位是1/100s。dirty_ratio
表示如果进程产生的脏数据达到系统整体内存的百分比,此时进程自行吧脏数据写回磁盘。dirty_writeback_centisecs
表示pdflush进程周期性间隔多久把脏数据协会磁盘,单位是1/100s。vfs_cache_pressure
表示内核回收用于directory和inode
cache内存的倾向;缺省值100表示内核将根据pagecache和swapcache,把directory和inode
cache报纸在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode
cache;高于100,将导致内核倾向于回收directory和inode cache。min_free_kbytes
表示强制Linux VM最低保留多少空闲内存(KB)。nr_pdflush_threads
表示当前正在进行的pdflush进程数量,在I/O负载高的情况下,内核会自动增加更多的pdflush。overcommit_memory
指定了内核针对内存分配的策略,可以是0、1、2.
0 表示内核将检查是否有足够的可用内存供应用进程使用。如果足够,内存申请允许;反之,内存申请失败。
1 表示内核允许分配所有物理内存,而不管当前内存状态如何。
2 表示内核允许分配查过所有物理内存和交换空间总和的内存。overcommit_ratio
如果overcommit_memory=2,可以过在内存的百分比。page-cluster
表示在写一次到swap区时写入的页面数量,0表示1页,3表示8页。swapiness
表示系统进行交换行为的成都,数值(0~100)越高,越可能发生磁盘交换。legacy_va_layout
表示是否使用最新的32位共享内存mmap()系统调用。nr_hugepages
表示系统保留的hugetlg页数。
第4章 内存泄露
4.1 如何确定是否有内存泄露
解决内存泄露一个好方法就是:不要让你的进程成为一个守护进程,完成工作后立刻退出,Linux会自动回收该进程所占有的内存。
测试内存泄露的两种方法:
1.模仿用户长时间使用设备,查看内存使用情况,对于那些内存大量增长的进程,可以初步怀疑其有内存泄露。
2.针对某个具体测试用例,检查是否有内存泄露。
在发现进程有漏洞之后,看看如何在代码中检查内存泄露。
4.2 mtrace
glibc针对内存泄露给出一个钩子函数mtrace:
1.加入头文件<mcheck.h>
2.在需要内存泄露检查的代码开始调用void mtrace(),在需要内存泄露检查代码结尾调用void
muntrace()。如果不调用muntrace,程序自然结束后也会显示内存泄露3.用debug模式编译检查代码(-g或-ggdb)
4.在运行程序前,先设置环境变量MALLOC_TRACE为一个文件名,这一文件将存有内存分配信息
5.运行程序,内存分配的log将输出到MALLOC_TRACE所执行的文件中。
代码如下:
include <stdio.h>
include <stdlib.h>
include <mcheck.h>
int main(void)
{
mtrace();
char *p=malloc(10);
return 0;
}
编译,设置环境变量,执行,查看log:
gcc -o mem-leakage -g mem-leakage.c
export MALLOC_TRACE=/home/lubaoquan/temp/malloc.og
./mem-leakage
= Start
@ ./mem-leakage:[0x400594] + 0x100d460 0xa (0xa表示泄露的内存大小,和malloc(10)对应)
加入mtrace会导致程序运行缓慢:
1.日志需要写到Flash上(可以将MALLOC_TRACE显示到stdout上。)
2.mtrace函数内,试图根据调用malloc代码指针,解析出对应的函数
性能优化是一个艰苦、持续、枯燥、反复的过程,涉及到的内容非常多,编译器优化、硬件体系结构、软件的各种技巧等等。
另外在嵌入式电池供电系统上,性能的优化也要考虑到功耗的使能。PnP的两个P(Power and Performance)是不可分割的部分。
第5章 性能优化的流程
5.1 性能评价
首先“快”与“慢”需要一个客观的指标,同时明确定义测试阶段的起讫点。
同时优化也要考虑到可移植性以及普适性,不要因为优化过度导致其他问题的出现。
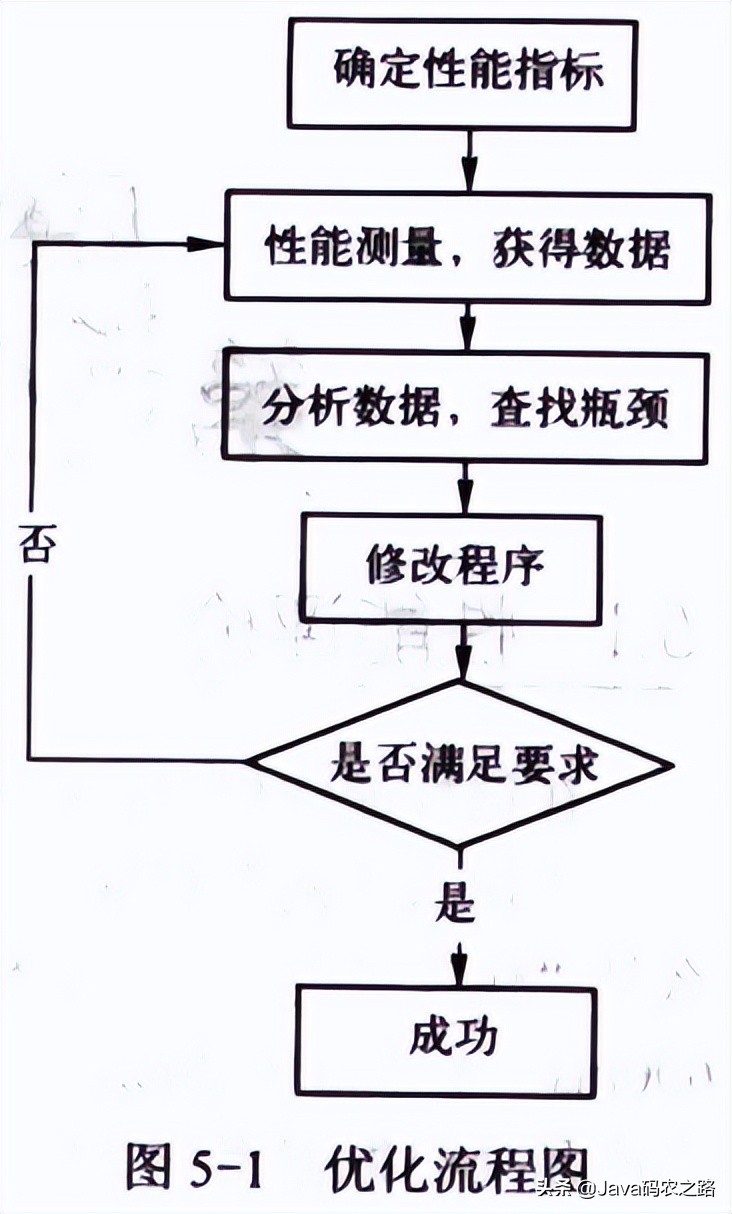
5.2 性能优化的流程
1. 测量,获得数据,知道和目标性能指标的差距。
2. 分析待优化的程序,查找性能瓶颈。
3. 修改程序。
4. 重新测试,验证优化结果。
5. 达到性能要求,停止优化。不达目标,继续分析。
5.3 性能评测
介绍两种方法:可视操作(摄像头)和日志。
话说摄像头录像评测,还是很奇葩的,适用范围很窄。但是貌似还是有一定市场。
5.4 性能分析
导致性能低下的三种主要原因:
(1) 程序运算量很大,消耗过多CPU指令。
(2) 程序需要大量I/O,读写文件、内存操作等,CPU更多处于I/O等待。
(3) 程序之间相互等待,结果CPU利用率很低。
简单来说即是CPU利用率高、I/O等待时间长、死锁情况。
下面重点放在第一种情况,提供三种方法。
1. 系统相关:/proc/stat、/proc/loadavg
** cat /proc/stat ** 结果如下:
cpu 12311503 48889 7259266 561072284 575332 0 72910 0 0 0-----分别是user、nice、system、idle、iowait、irq、softirq、steal、guest、guest_nice user:从系统启动开始累计到当前时刻,用户态CPU时间,不包含nice值为负的进程。 nice:从系统启动开始累计到当前时刻,nice值为负的进程所占用的CPU时间。 system:从系统启动开始累计到当前时刻,内核所占用的CPU时间。 idle:从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其他等待时间。 iowait:从系统启动开始累计到当前时刻,硬盘IO等待时间。 irq:从系统启动开始累计到当前时刻,硬中断时间。 softirq:从系统启动开始累计到当前时刻,软中断时间。 steal:从系统启动开始累计到当前时刻,involuntary wait guest:running as a normal guest guest_nice:running as a niced guest cpu0 3046879 11947 1729621 211387242 95062 0 1035 0 0 0 cpu1 3132086 8784 1788117 116767388 60010 0 535 0 0 0 cpu2 3240058 12964 1826822 116269699 353944 0 31989 0 0 0 cpu3 2892479 15192 1914705 116647954 66316 0 39349 0 0 0 intr 481552135 16 183 0 0 0 0 0 0 175524 37 0 0 2488 0 0 0 249 23 0 0 0 0 0 301 0 0 3499749 21 1470158 156 33589268 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -------------------Counts of interrupts services since boot time.Fist column is the total of all interrupts services, each subsequent if total for particular interrupt. ctxt 2345712926-------------------------------------------------Toal number of context switches performed since bootup accross all CPUs. btime 1510217813------------------------------------------------Give the time at which the system booted, in seconds since the Unix epoch. processes 556059------------------------------------------------Number of processes and threads created, include(but not limited to) those created by fork() or clone() system calls. procs_running 2-------------------------------------------------Current number of runnable threads procs_blocked 1-------------------------------------------------Current number of threads blocked, waiting for IO to complete. softirq 415893440 117 134668573 4001105 57050104 3510728 18 1313611 104047789 0 111301395---总softirq和各种类型softirq产生的中断数:HI_SOFTIRQ,TIMER_SOFTIRQ,NET_TX_SOFTIRQ,NET_RX_SOFTIRQ,BLOCK_SOFTIRQ,IRQ_POLL_SOFTIRQ,TASKLET_SOFTIRQ,SCHED_SOFTIRQ,HRTIMER_SOFTIRQ,RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ 由cpu的各种时间可以推导出:
CPU时间=user+nice+system+idle+iowait+irq+softirq+steal+guest+guest_nice
CPU利用率=1-idle/(user+nice+system+idle+iowait+irq+softirq+steal+guest+guest_nice)
CPU用户态利用率=(user+nice)/(user+nice+system+idle+iowait+irq+softirq+steal+guest+guest_nice)
CPU内核利用率=system/(user+nice+system+idle+iowait+irq+softirq+steal+guest+guest_nice)
IO利用率=iowait/(user+nice+system+idle+iowait+irq+softirq+steal+guest+guest_nice)
** cat /proc/loadavg ** 结果如下:
0.46 0.25 0.16 2/658 13300 1、5、15分钟平均负载;
2/658:在采样时刻,运行队列任务数目和系统中活跃任务数目。
13300:最大pid值,包括线程。
2. 进程相关:/proc/xxx/stat
24021 (atop) S 1 24020 24020 0 -1 4194560 6179 53 0 0 164 196 0 0 0 -20 1 0 209898810 19374080 1630 18446744073709551615 1 1 0 0 0 0 0 0 27137 0 0 0 17 1 0 0 0 0 0 0 0 0 0 0 0 0 0 3. top
top是最常用来监控系统范围内进程活动的工具,提供运行在系统上的与CPU关系最密切的进程列表,以及很多统计值。
第6章 进程启动速度
进程启动可以分为两部分:
(1) 进程启动,加载动态库,直到main函数值钱。这是还没有执行到程序员编写的代码,其性能优化有其特殊方法。
(2) main函数之后,直到对用户的操作有所响应。涉及到自身编写代码的优化,在7、8章介绍。
6.1 查看进程的启动过程
hello源码如下:
#include <stdio.h> #include <stdlib.h> int main() { printf("Hello world!n"); return 0; } 编译:
gcc -o hello -O2 hello.c strace用于查看系统运行过程中系统调用,同时得知进程在加载动态库时的大概过程,-tt可以打印微妙级别时间戳。
strace -tt ./hello如下:
20:15:10.185596 execve("./hello", ["./hello"], [/* 82 vars */]) = 0 20:15:10.186087 brk(NULL) = 0x19ad000 20:15:10.186206 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) 20:15:10.186358 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f24710ea000 20:15:10.186462 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) 20:15:10.186572 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 20:15:10.186696 fstat(3, {st_mode=S_IFREG|0644, st_size=121947, ...}) = 0 20:15:10.186782 mmap(NULL, 121947, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f24710cc000 20:15:10.186857 close(3) = 0 20:15:10.186975 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) 20:15:10.187074 open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3 20:15:10.187153 read(3, "177ELF2113��������3�>�1���Pt2�����"..., 832) = 832----------------libc.so.6文件句柄3,大小832。 20:15:10.187270 fstat(3, {st_mode=S_IFREG|0755, st_size=1868984, ...}) = 0 20:15:10.187358 mmap(NULL, 3971488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f2470afd000 20:15:10.187435 mprotect(0x7f2470cbd000, 2097152, PROT_NONE) = 0 20:15:10.187558 mmap(0x7f2470ebd000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1c0000) = 0x7f2470ebd000---参数依次是:addr、length、prot、flags、fd、offset。 20:15:10.187662 mmap(0x7f2470ec3000, 14752, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f2470ec3000 20:15:10.187749 close(3) = 0 20:15:10.187887 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f24710cb000 20:15:10.187992 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f24710ca000 20:15:10.188072 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f24710c9000 20:15:10.188191 arch_prctl(ARCH_SET_FS, 0x7f24710ca700) = 0--------------------------------set architecture-specific thread state, the parameters are code and addr。 20:15:10.188334 mprotect(0x7f2470ebd000, 16384, PROT_READ) = 0 20:15:10.188419 mprotect(0x600000, 4096, PROT_READ) = 0 20:15:10.188541 mprotect(0x7f24710ec000, 4096, PROT_READ) = 0 20:15:10.188633 munmap(0x7f24710cc000, 121947) = 0 20:15:10.188785 fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 2), ...}) = 0 20:15:10.188965 brk(NULL) = 0x19ad000 20:15:10.189158 brk(0x19ce000) = 0x19ce000 20:15:10.189243 write(1, "Hello world!n", 13Hello world!-----------------------------------往句柄1写13个字符Hello world!n。 ) = 13 20:15:10.189299 exit_group(0) = ? 20:15:10.189387 +++ exited with 0 +++ 通过设置LD_DEBUG环境变量,可以打印出在进程加载过程中都做了那些事情:
LD_DEBUG=all ./hello如下。看似简单的一个Hello world!,其系统已经做了很多准备工作。
13755: 13755: file=libc.so.6 [0]; needed by ./hello [0]----------(1) 搜索其所依赖的动态库。 13755: find library=libc.so.6 [0]; searching 13755: search cache=/etc/ld.so.cache 13755: trying file=/lib/x86_64-linux-gnu/libc.so.6 13755: 13755: file=libc.so.6 [0]; generating link map 13755: dynamic: 0x00007fbac5cedba0 base: 0x00007fbac592a000 size: 0x00000000003c99a0 13755: entry: 0x00007fbac594a950 phdr: 0x00007fbac592a040 phnum: 10 13755: 13755: checking for version `GLIBC_2.2.5' in file /lib/x86_64-linux-gnu/libc.so.6 [0] required by file ./hello [0] 13755: checking for version `GLIBC_2.3' in file /lib64/ld-linux-x86-64.so.2 [0] required by file /lib/x86_64-linux-gnu/libc.so.6 [0] 13755: checking for version `GLIBC_PRIVATE' in file /lib64/ld-linux-x86-64.so.2 [0] required by file /lib/x86_64-linux-gnu/libc.so.6 [0] 13755: 13755: Initial object scopes------------------------------(2) 加载动态库。 13755: object=./hello [0] 13755: scope 0: ./hello /lib/x86_64-linux-gnu/libc.so.6 /lib64/ld-linux-x86-64.so.2 13755: object=linux-vdso.so.1 [0] 13755: scope 0: ./hello /lib/x86_64-linux-gnu/libc.so.6 /lib64/ld-linux-x86-64.so.2 13755: scope 1: linux-vdso.so.1 13755: 13755: object=/lib/x86_64-linux-gnu/libc.so.6 [0] 13755: scope 0: ./hello /lib/x86_64-linux-gnu/libc.so.6 /lib64/ld-linux-x86-64.so.2 13755: 13755: object=/lib64/ld-linux-x86-64.so.2 [0] 13755: no scope 13755: 13755: 13755: relocation processing: /lib/x86_64-linux-gnu/libc.so.6 (lazy) 13755: symbol=_res; lookup in file=./hello [0] 13755: symbol=_res; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0] 13755: binding file /lib/x86_64-linux-gnu/libc.so.6 [0] to /lib/x86_64-linux-gnu/libc.so.6 [0]: normal symbol `_res' [GLIBC_2.2.5] ... 13755: symbol=__vdso_time; lookup in file=linux-vdso.so.1 [0] 13755: binding file linux-vdso.so.1 [0] to linux-vdso.so.1 [0]: normal symbol `__vdso_time' [LINUX_2.6] 13755: symbol=__vdso_gettimeofday; lookup in file=linux-vdso.so.1 [0] 13755: binding file linux-vdso.so.1 [0] to linux-vdso.so.1 [0]: normal symbol `__vdso_gettimeofday' [LINUX_2.6] 13755: 13755: relocation processing: ./hello (lazy) 13755: symbol=__gmon_start__; lookup in file=./hello [0] 13755: symbol=__gmon_start__; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0] 13755: symbol=__gmon_start__; lookup in file=/lib64/ld-linux-x86-64.so.2 [0] ... 13755: 13755: calling init: /lib/x86_64-linux-gnu/libc.so.6--------(3) 初始化动态库。 13755: 13755: symbol=__vdso_clock_gettime; lookup in file=linux-vdso.so.1 [0] 13755: binding file linux-vdso.so.1 [0] to linux-vdso.so.1 [0]: normal symbol `__vdso_clock_gettime' [LINUX_2.6] 13755: symbol=__vdso_getcpu; lookup in file=linux-vdso.so.1 [0] 13755: binding file linux-vdso.so.1 [0] to linux-vdso.so.1 [0]: normal symbol `__vdso_getcpu' [LINUX_2.6] 13755: symbol=__libc_start_main; lookup in file=./hello [0] 13755: symbol=__libc_start_main; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0] 13755: binding file ./hello [0] to /lib/x86_64-linux-gnu/libc.so.6 [0]: normal symbol `__libc_start_main' [GLIBC_2.2.5] 13755: 13755: initialize program: ./hello--------------------------(4) 初始化进程。 13755: 13755: 13755: transferring control: ./hello------------------------(5) 将程序的控制权交给main函数。 13755: 13755: symbol=puts; lookup in file=./hello [0] 13755: symbol=puts; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0] 13755: binding file ./hello [0] to /lib/x86_64-linux-gnu/libc.so.6 [0]: normal symbol `puts' [GLIBC_2.2.5] 13755: symbol=_dl_find_dso_for_object; lookup in file=./hello [0] 13755: symbol=_dl_find_dso_for_object; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0] 13755: symbol=_dl_find_dso_for_object; lookup in file=/lib64/ld-linux-x86-64.so.2 [0] 13755: binding file /lib/x86_64-linux-gnu/libc.so.6 [0] to /lib64/ld-linux-x86-64.so.2 [0]: normal symbol `_dl_find_dso_for_object' [GLIBC_PRIVATE] Hello world!-------------------------------------------------------(6) 执行用户程序。 13755: 13755: calling fini: ./hello [0]---------------------------(7) 执行去初始化动作。 6.2 减少加载动态库的数量
正如《Systems Performance》所说的,最好的优化就是取出不必要的工作。
(1) 将一些无用的动态库去掉。
(2) 重新组织动态库的结构,力争将进程加载动态库的数量减到最小。
(3) 将一些动态库编译成静态库,与进程或其他动态库合并。
优点是:
- 减少了加载动态库的数量。
- 在与其他动态库合并之后,动态库内部之间的函数调用不必再进行符号查找、动态链接。
缺点是:
- 如果被其他进程或动态库依赖,则会导致被复制多份,占用更多空间。
- 失去了代码段内存共享,导致内存使用增加。
- 由于被多个进程使用,导致page fault增多,进而影响加载速度。
因此,对于只被很少进程加载的动态库,将其编译成静态库,减少进程启动时加载动态库的数量。对于那些守护使用的动态库,代码段大多已经被加载到内存,运行时产生的page
fault要少,因此动态库反而要比静态库速度更快。
(4) 使用dlopen动态加载动态库。可以精确控制动态库的生存周期,一方面可以减少动态库数据段的内存使用,另一方面可以减少进程启动时加载动态库的时间。
6.3 共享库的搜索路径
在进程加载动态库是,loader要从很多路径搜索动态库,搜索顺序是:DT_NEED-->DT_RPATH-->LD_LIBRARY_PATH-->LD_RUNPATH-->ld.so.conf-->/lib
/usr/lib。
DT_RPATH和LD_RUNPATH是程序编译时加的选项,使用-rpath来设置DT_RPATH。
还存在一种比DT_RPATH更高优先级的目录搜索机制HWCAP。HWCAP是为了支持系统根据不同的硬件特性,道不同的目录去搜索动态库。
可以通过屏蔽LD_HWCAP_MASK减少搜索路径。
export LD_HWCAP_MASK=0X00000000 6.4 动态库的高度
依据动态库之间的依赖关系,从当前动态库到最底层动态库之间的最长路径,成为该动态库的高度。
降低动态库的高度,有利于提高加载时间。
6.5 动态库的初始化
在loader完成对动态库的内存应设置后,需要运行动态库的一些初始化函数,来完成设置动态库的一些基本环境。包括两部分:
(1) 动态库的构造和析构函数机制
首先构造三个文件hello.c、hello.h、main.c。
===========hello.c============ #include <stdio.h> void __attribute__ ((constructor)) my_init(void) { printf("constructorn");; } void __attribute__ ((destructor)) my_finit(void) { printf("destructorn");; } void hello(const char *name) { printf("Hello %s!n", name); } ===========hello.h============ #ifndef HELLO_H #define HELLO_H void hello(const char *name); #endif //HELLO_H ===========main.c============ #include "hello.h" int main() { hello("everyone"); return 0; } 然后编译库(gcc -fPIC -shared -o libmyhello.so hello.c)、拷贝库到系统lib目录(sudo cp
libmyhello.so /usr/lib)、编译执行文件(gcc -o hello main.c -L./ -lmyhello)。
执行./hello结果如下:
constructor Hello everyone! destructor (2) 动态库的全局变量初始化工作
在C语言中,全局变量保存在.data段。再启动过程中,loader只是简单地使用mmap将数据段映射到dirty
page,这些变量只有在第一次使用到的时候才会为其分配物理内存。
从优化的角度来讲,要尽量减少全局对象的使用。
6.6 动态链接
首先给一段代码,基于此看看动态链接的过程。
#include <stdio.h> int main() { printf("hellon"); return 0; } printf是glibc中定义,采用动态库,在程序编译阶段,编译器无法得知printf函数地址。
在程序运行时,当调用printf的时候,程序会将处理权交给linker,由其负责在执行文件以及其连接的动态库中查找printf函数地址。
由于linker不知道printf具体在哪个动态库,所以将在整个执行文件和动态库范围内查找。
26221: 26221: runtime linker statistics: 26221: total startup time in dynamic loader: 703291 cycles 26221: time needed for relocation: 188666 cycles (26.8%) 26221: number of relocations: 77 26221: number of relocations from cache: 3 26221: number of relative relocations: 1199 26221: time needed to load objects: 325593 cycles (46.2%) hello 26221: 26221: runtime linker statistics: 26221: final number of relocations: 82 26221: final number of relocations from cache: 3 可以看出及时简单打印hello,在启动过程中查找、链接了很多符号,耗费了大量cpu cycle。
优化的方法:
(1) 减少导出符号的数量
通过去掉那些动态库中不必导出的符号,从而减少动态库在做链接时所查找的符号的数量,可以加快动态链接的速度。
(2) 减少符号的长度
在做符号链接时,linker将做字符串的匹配,符号名字越长,其查找匹配的时间越长。
(3) 使用prelink
如果动态库在编译的时候就能确定运行时的加载地址,那么动态库函数调用的地址就应该是已知的,在进程运行的时候就没有必要再进行符号的查找和链接,从而节省进程的启动时间。
6.7 提高进程启动速度
1. 将进程改为线程
2. prefork进程
3. preload进程
4. 提前加载,延后退出
5. 调整CPU的频率
总体来讲,优化进程的启动速度的顺序为:
(1) 优化动态库的搜索路径
(2) 检查进程中是否有无用的动态库
(3) 减少进程或所依赖动态库的全局对象的数量
(4) 使用prelink,预先链接进程的动态库
(5) 考虑重新组织动态库,争取减少进程加载动态库的数量
(6) 考虑使用dlopen,将一起启动时不需要的动态库从进程的依赖动态库中去除
如果仍然无法满足要求,可以采用调度的方法:
(1) 进程改为线程
(2) preload进程
(3) 提前加载、延迟退出。
6.8 进程冷起与热起的区别
在程序第一次启动(冷起)退出后,再次启动速度明显比第一次快,为什么呢?
在程序第一次启动、退出后,进程虽然被销毁了,但是进程代码段所占用的物理内存并没有被销毁;而是被Linux缓存起来,保存在Cache中。
这样程序再次启动时,指令不必再从Flash读到内存中,而是直接使用Linux内核中的Cache,减少了程序启动过程中所产生的page
fault,从而加快了进程的启动速度。
在进程启动过程中:
(1) 进程冷起时,如果运行的指令较多,则出现的page fault较多,影响进程的启动速度。
(2) 进程所依赖的某些动态库可能已经被一些守护进程所加载,其代码段已经在内存中,故这种动态库对进程的冷起和热起性能影响不大。
(3) 没有被其他进程使用过的动态库,在冷起时则会产生page fault影响进程的启动速度。
第7章 性能优化的方法
程序优化!=编码技巧
编码技巧是程序优化的一部分;程序优化涉及到硬件架构、程序架构、逻辑设计等,还有一点如何确定代码瓶颈位置很重要。
7.1 寻找程序热点
1. gprof
#include <stdio.h> void funca() { int i = 0, n = 0; for(i=0; i<10000000; i++) { n++; n--; } } void funcb() { int i = 0, n = 0; for(i=0; i<10000000; i++) { n++; n--; } } int main() { int i=0; for(i=0;i<10;i++) { funca(); } funcb(); return 0; } 然后编译(gcc performance.c -pg -o performance)、运行(./performance)、查看结果(gprof
performance gmon.out -q -p)。
gprof performance gmon.out -p Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls ms/call ms/call name 91.95 0.40 0.40 10 40.46 40.46 funca 9.20 0.45 0.04 1 40.46 40.46 funcb ========================================= gprof performance gmon.out -q Call graph (explanation follows) granularity: each sample hit covers 2 byte(s) for 2.25% of 0.45 seconds index % time self children called name <spontaneous> [1] 100.0 0.00 0.45 main [1] 0.40 0.00 10/10 funca [2] 0.04 0.00 1/1 funcb [3] ----------------------------------------------- 0.40 0.00 10/10 main [1] [2] 90.9 0.40 0.00 10 funca [2] ----------------------------------------------- 0.04 0.00 1/1 main [1] [3] 9.1 0.04 0.00 1 funcb [3] ----------------------------------------------- 2. oprofile
7.2 程序逻辑瓶颈
oprofile只能有助于发现热点,但是对程序热点与代码逻辑对应关系无法对应,因此不能定位由逻辑问题所造成的瓶颈。
可以通过添加日志的方法来确定不同逻辑部分耗时。进而找出逻辑问题。
7.3 优化的层次
1. 针对某一特定事例的优化,考虑使用oprofile,查找热点,进行优化。主要以扩及优化为主、程序热点函数优化为辅。
2. 系统整体性能的提高,分两层:业务逻辑的优化和底层基础函数性能优化。
上层业务逻辑优化:重点在于逻辑的调整、算法的优化。
底层基础函数游湖:重点在于代码的写作技巧。
7.4 何时开始性能优化
(1) 在需求阶段,就要把性能指标定义下来。
(2) 在软件设计阶段,要考虑这些性能指标,根据指标来考虑程序所使用的算法、逻辑,在这个阶段考虑逻辑上的优化。
(3) 在软件功能基本完成后,一方面软件的逻辑要做一些细微调整,另一方面要开始使用oprofile之类的工具查找热点函数,对热点函数做代码优化。
7.5 如何推动系统性能优化
(1) 需要找出一些关键的步骤,这些步骤性能直接影响着用户使用体验。
(2) 为这些关键的过程定义相应的性能指标。
(3) 在定义性能指标后,需要测试现系统,看看各个过程和目标性能之间的差距。
(4) 拿到结果之后吗,需要和相应开发团队谈判,要求其优化代码。
当优化任务
陷入僵局的时候,要求相应团队出具两份报告:一,从程序逻辑考虑,程序都做了哪些事情,每个事情花了多少时间,主要算法是什么;二,这个过程中oprofile报告,包括每个函数执行时间占比。查看前几名函数逻辑上是否合理;对于前几名函数,检查其从算法实现到代码优化层次是否能够进行优化。
(5) 在各个团队优化完代码之后,返回流程(3)从新测试性能。如没有达标,继续3~5过程。
7.6 为什么软件性能会低下
7.7 程序逻辑优化
5个程序优化的思路:
(1) Do it faster:找到最有效率的方法,来提高程序的运行速度。
(2) Do it in parallel:并行加快执行速度。
(3) Do it later:不必要的功能,可以考虑延后执行,腾出资源做重要的事。
(4) Don't do it at all:最好的优化就是不做事。
(5) Do it before:把一些工作空闲时预先完成。
第8章 代码优化的境界
从高级语言C/C++,到指令在系统上运行,分两个阶段:
(1) 编译器将C/C++转变成可以在系统上运行的机器指令。编译器会对代码进行优化,优化后的机器指令可能与编写的代码有较大差异。
(2) 机器指令在不同硬件上执行,与体系结构、执行环境有密切关系。
所以优化代码有两个境界:从代码看到编译器优化后产生的汇编指令;根据芯片组特性,能看到汇编语言在硬件中执行状态,比如流水线使用情况、缓存命中率等等。
8.1 GCC编译优化
8.1.1 条件编译
通过宏来降低条件判断等操作,提高效率。
gcc -DXXX
8.1.2 指定CPU的型号
gcc -mcpu=XXX,是编译出来的代码能够充分利用硬件平台的特点,加快程序的执行速度。
8.1.3 builtin函数
GCC提供一些builtin函数来完成一些特殊功能。
(1) void *__builtin_apply_args(void);
(1) void __builtin_apply(void (func)(), void *arguments, int size);
(1) void *__builtin_return(void *result);
GCC网站http://gcc.gnu.org/onlinedocs/提供了builtin详细信息。
8.1.4 GCC编译优化
-O0 关闭编译器优化
-O/-O1 增加了一些GCC优化代码选项
-O2 除了完成所有-O1级别的优化之外,增加了比如处理器指令调度等。
-O3 除了完成所有-O2级别的优化之外,增加了循环展开和其他一些处理器特性相关优化工作。
8.2 优化基本原则
8.3 标准C代码优化
8.4 C++代码优化
8.5 硬件相关的优化
第9章 系统性能优化
9.1 Shell脚本优化
9.1.1 Shell脚本优化
在嵌入式Linux中,bash脚本占很大比重。优化shell有助于缩短系统启动时间,加快进程的执行速度。
在Linux bash shell一般由Busybox实现,命令主要被分为两大类:built-ins和applets。
Built-ins只是简单的函数调用,而applets则意味着需要调用"fork/exec"创建子进程来执行,并且busybox也可以使用外部命令。
处于性能考虑,应使用built-ins来代替applets和外部命令。
输入 busybox ,可以看到支持的所有功能。
include/applets.h中,定义了BusyBox支持的所有功能。
docs/nofork_noexec.txt中,说明了built-ins和applets的区别。
applets.h定义功能的时候,也定义了类型,分类如下:
(1) APPLET:即applets,创建一个子进程,然后调用exec执行相应的功能,执行完毕后,返还控制给父进程。
(2) APPLET_NOUSAGE:BusyBox中不包含该命令的帮助文档。
(3) APPLET_NOEXEC:调用fork创建子进程,然后执行BusyBox对应功能,执行完毕后,返回控制给父进程。
(4) APPLET_NOFORK:相当于built-ins,只执行BusyBox内部函数,不创建子进程,效率最高。
9.1.2 bash脚本
包含在pipe中的built-ins将创建子进程来执行。
包含在'中的命令将创建子进程来执行。
对bash脚本进行优化时,要尽量避免fork进程。
9.1.3 如何优化busybox bansh脚本
(1) 去掉脚本中无用的代码
(2) 尽可能使用busybox中的built-ins替换外部命令
printf "Starting" --> echo "Starting"
(3) 尽可能不使用pipe
(4) 减少pipe中的命令数
(5) 尽可能不适用" ** ' ** "
更多方法参考: ** Optimize RC Scripts **
9.2 使用preload预先加载进程
在系统比较空闲时,通过将特定程序的代码从Flash加载到Cache,加快进程执行速度。
能否控制在Cache内存回收时,对某些关键进程所占用的Cache尽量少回收,加大某一进程Cache内存数量。
Linux有一个开源项目 ** preload ** ,就是利用控制Linux中的cache,来加快进程的启动速度。
类似的技术有prelink和readahead
9.3 调整进程的优先级
在Linux内核中,支持两种进程:实时进程和普通进程。
(1) 实时进程
实时进程的优先级是静态设定的,只有当运行队列没有实时进程的情况下,普通进程才能够获得调度。
实时进程采用两种调度策略:SCHED_FIFO和SCHED_RR。
FIFO采用先进先出的策略,对于所有相同优先级的进程,最先进入runqueue的进程总能优先获得调度;Round
Robin采用更加公平的轮转策略,使得相同优先级的实时进程能够轮流获得调度。
对于实时进程来讲,使用绝对优先级概念,绝对优先级取值范围是0~99,数字越大,优先级越高。
(2) 普通进程
Linux 2.6普通进程的绝对优先级取值是0,普通进程有静态优先级和动态优先级之分。
可以通过nice修改进程的静态优先级。
系统在运行过程中,在静态优先级基础上,不断动态计算出每个进程的动态优先级,拥有最高优先级的进程被调度器选中。
动态优先级计算公式:动态优先级=max(100,min(静态优先级-bonus+5,139))
bonus取决于进程的平均睡眠时间。
对实时进程设置通过如下函数进行:
#include <sched.h> int sched_setscheduler(pid_t pid, int policy, const struct sched_param *param); int sched_getscheduler(pid_t pid); int sched_setparam(pid_t pid, const struct sched_param *param); int sched_getparam(pid_t pid, const struct sched_param *param); pid:指定所要设置的进程号,pid为0,表示为当前进程。
policy:设置进程调度策略,SCHED_OTHER/SCHED_FIFO/SCHED_RR。
param:设置进程的绝对优先级,范围是0~99。
对普通进程来讲,绝对优先级为0,通过nice来影响进程的调度。
nice取值-20~19,可以通过setpriority来设置普通进程优先级。
#include <sys/resource.h> int setpriority(int class, int id, int niceval); class:PRIO_PROCESS/PRIO_PGRP/PRIO_USER。
niceval:为进程nice值,-20~19。
对实时线程操作,使用pthread_setschedparam;对普通线程,仍然可以使用setpriority和nice来调整线程优先级。
9.4 让进程运行的慢一些
对于某些没有时限要求的进程,可以降低运行速度。
(1) 降低进程优先级。
(2)
增加一些代码来控制Linux中进程的调度,如sched_yield自愿放弃CPU,进程仍然处于TASK_RUNNING状态,但调度器把它放在运行队列链表的末尾。
9.5 守护进程的数量
守护进程占用大量动态库代码段和数据段内存,内存蟹柳概率加大,CPU性能下降,导致系统整体性能下降。
9.6 文件系统
主要看基于Flash和RAM的两大类文件系统。
基于Flash的文件系统:JFFS2、YAFFS2、Cramfs、Romfs,YAFFS2目前被广泛运用。
基于RAM的文件系统:Ramdisk(在Linux启动,initrd提供将内核映像和根文件系统一起载入内存)、Ramfs/tmpfs(把所有的文件都放在RAM中)。